清华大学SimpleFlight框架实现无人机零微调部署,轨迹跟踪误差降低50%,显著提升强化学习在无人机控制领域的应用。
原文标题:轨迹跟踪误差直降50%,清华汪玉团队强化学习策略秘籍搞定无人机
原文作者:数据派THU
冷月清谈:
清华大学研究团队提出了一种名为SimpleFlight的强化学习框架,用于无人机控制,可将轨迹跟踪误差降低50%以上。该框架的核心在于解决了强化学习策略从仿真到现实应用的难题,实现了零微调部署。SimpleFlight集成了五大关键技术:
1. 使用相对位姿误差、速度和旋转矩阵作为策略网络输入,方便长距离规划和处理急转弯。
2. 将时间向量添加到价值网络输入,增强对时间信息的感知。
3. 使用CTBR指令作为策略输出,并用连续动作差异的正则化作为平滑度奖励,保证飞行稳定性。
4. 通过系统辨识校准关键动力学参数,并谨慎选择性地应用域随机化。
5. 使用较大的batch size进行训练,提高策略的泛化能力和鲁棒性。
研究人员在Crazyflie 2.1和自制250mm轴距四旋翼无人机上进行了实验,结果表明SimpleFlight在各种轨迹,包括平滑和不可行轨迹上,都取得了最佳性能,且无需额外微调。
1. 使用相对位姿误差、速度和旋转矩阵作为策略网络输入,方便长距离规划和处理急转弯。
2. 将时间向量添加到价值网络输入,增强对时间信息的感知。
3. 使用CTBR指令作为策略输出,并用连续动作差异的正则化作为平滑度奖励,保证飞行稳定性。
4. 通过系统辨识校准关键动力学参数,并谨慎选择性地应用域随机化。
5. 使用较大的batch size进行训练,提高策略的泛化能力和鲁棒性。
研究人员在Crazyflie 2.1和自制250mm轴距四旋翼无人机上进行了实验,结果表明SimpleFlight在各种轨迹,包括平滑和不可行轨迹上,都取得了最佳性能,且无需额外微调。
怜星夜思:
1、SimpleFlight框架中提到谨慎使用域随机化,如何判断哪些参数需要进行域随机化,哪些不需要?有没有一些通用的原则或方法?
2、文章中提到了使用旋转矩阵而不是四元数作为输入更有利于神经网络的学习,为什么会有这样的差异?
3、SimpleFlight主要针对轨迹跟踪任务,如果想将其应用于其他无人机控制任务,比如目标抓取、编队飞行等,需要做哪些改进?
2、文章中提到了使用旋转矩阵而不是四元数作为输入更有利于神经网络的学习,为什么会有这样的差异?
3、SimpleFlight主要针对轨迹跟踪任务,如果想将其应用于其他无人机控制任务,比如目标抓取、编队飞行等,需要做哪些改进?
原文内容

来源:机器之心本文约3000字,建议阅读10分钟
本文介绍了基于强化学习的无人机控制策略零样本泛化到真实世界的关键因素。
作者来自于清华大学高能效计算实验室,通讯作者为清华大学汪玉教授和于超博士后,研究方向为强化学习和具身智能。
控制无人机执行敏捷、高机动性的行为是一项颇具挑战的任务。传统的控制方法,比如 PID 控制器和模型预测控制(MPC),在灵活性和效果上往往有所局限。而近年来,强化学习(RL)在机器人控制领域展现出了巨大的潜力。通过直接将观测映射为动作,强化学习能够减少对系统动力学模型的依赖。
然而,「Sim2Real」(从仿真到现实)的鸿沟却始终是强化学习应用于无人机控制的难点之一。如何实现无需额外微调的策略迁移,是研究者们追逐的目标。尽管有许多基于强化学习的控制方法被提出,但至今学界仍未就训练出鲁棒且可零微调部署的控制策略达成一致,比如:奖励函数应该如何设计才能让无人机飞得平稳?域随机化在无人机控制中到底该怎么用?
最近,清华大学的研究团队为我们带来了一个突破性的答案。他们详细研究了训练零微调部署的鲁棒 RL 策略所需的关键因素,并提出了一套集成五大技术、基于 PPO 的强化学习框架 SimpleFlight。这一框架在轨迹跟踪误差上比现有的 RL 基线方法降低了 50% 以上!如果你正为强化学习策略无法实际控制无人机而发愁,那么 SimpleFlight 能够帮助你训练出无需额外微调就能在真实环境中运行的鲁棒策略。

-
论文标题:What Matters in Learning A Zero-Shot Sim-to-Real RL Policy for Quadrotor Control? A Comprehensive Study
-
论文链接:https://arxiv.org/abs/2412.11764
-
开源代码及模型项目网站:https://sites.google.com/view/simpleflight
实验效果一览
为了验证 SimpleFlight 的有效性,研究人员在开源的微型四旋翼无人机 Crazyflie 2.1 上进行了广泛的实验。
实验中,无人机的位置、速度和姿态信息由 OptiTrack 运动捕捉系统以 100Hz 的频率提供,并传输到离线计算机上进行策略解算。策略生成的 collective thrust and body rates( CTBR) 控制指令以 100Hz 的频率通过 2.4GHz 无线电发送到无人机。
研究人员使用了以下两种类型的轨迹作为基准轨迹:
-
平滑轨迹:包括八字形和随机多项式轨迹。八字形轨迹具有周期性,研究人员测试了三种速度:慢速 (15.0s 完成)、正常速度 (5.5s 完成) 和快速 (3.5s 完成)。随机多项式轨迹由多个随机生成的五次多项式段组成,每个段的持续时间在 1.00s 和 4.00s 之间随机选择。
-
不可行轨迹:包括五角星和随机之字形轨迹。五角星轨迹要求无人机以恒定速度依次访问五角星的五个顶点。研究人员测试了两种速度:慢速 (0.5m/s) 和快速 (1.0m/s)。随机之字形轨迹由多个随机选择的航点组成,航点的 x 和 y 坐标在 -1m 和 1m 之间分布,连续航点之间由直线连接,时间间隔在 1s 和 1.5s 之间随机选择。

策略的训练数据包括平滑随机五次多项式和不可行之字形轨迹。训练过程持续 15,000 个 epoch,训练完成后,将策略直接部署到 Crazyflie 无人机上进行测试,没有进行任何微调。值得注意的是,由于策略在不同随机种子下表现稳定,研究人员在 3 个随机种子中随机挑选了一个策略而没有选择表现最好的那个。

研究人员将 SimpleFlight 与两种 SOTA 的 RL 基线方法 (DATT [1] 和 Fly [2]) 进行了比较,如表 1 所示。结果表明,SimpleFlight 在所有基准轨迹上都取得了最佳性能,轨迹跟踪误差降低了 50% 以上,并且是唯一能够成功完成所有基准轨迹(包括平滑和不可行轨迹)的方法。图 2 是一些真机飞行的视频。

 图 2:SimpleFlight 在 Crazyflie 2.1 无人机上的实验效果
图 2:SimpleFlight 在 Crazyflie 2.1 无人机上的实验效果
研究人员指出,这些对比的核心目的并非进行绝对的横向评价,而是为了表明:SimpleFlight 实现了目前所知的在 Crazyflie 2.1 上的最佳控制性能,尽管没有依赖任何新的算法改进或复杂的架构升级。SimpleFlight 的意义更在于作为一套关键训练因素的集合,它能够轻松集成到现有的四旋翼无人机控制方法中,从而帮助研究者和开发者进一步优化控制性能。
此外,研究人员还进行了额外实验,将 SimpleFlight 部署到一款由团队自制的 250mm 轴距四旋翼无人机上。这款无人机配备了 Nvidia Orin 处理器,进一步验证了 SimpleFlight 在不同硬件平台上的适应性与效果。自制无人机的飞行视频和结果已上传至项目官网,供感兴趣的同行参考。
SimpleFlight 的五大核心秘诀
那么,SimpleFlight 是如何做到的呢?研究人员主要是从优化输入空间设计、奖励设计和训练技术三方面来缩小模拟到现实的差距,并总结出了以下 5 大关键因素:
-
采用与未来一段参考轨迹的相对位姿误差、速度和旋转矩阵作为策略网络的输入,这使得策略可以进行长距离规划,并更好地处理具有急转弯的不可行轨迹。研究人员指出,在强化学习策略的学习中,采用旋转矩阵而不是四元数作为输入,更有利于神经网络的学习。
-
将时间向量添加到价值网络的输入。无人机的控制任务通常是随时间动态变化的,时间向量作为价值网络的额外输入,增强了价值网络对时间信息的感知,从而更准确地估计状态值。
-
采用 CTBR 指令作为策略输出动作,使用连续动作之间的差异的正则化作为平滑度奖励。在无人机控制中,不平滑的动作输出可能导致飞行过程中的不稳定,甚至出现震荡和意外偏离轨迹的情况。而现实中的无人机由于硬件特性和动态响应的限制,比仿真环境更容易受到这些不稳定动作的影响。研究人员比较了多种平滑度奖励方案,结果表明使用连续动作之间的差异的正则化作为平滑度奖励,可以获得最佳的跟踪性能,同时鼓励策略输出平滑的动作,避免在现实世界中产生不稳定的飞行行为。
-
使用系统辨识对关键动力学参数进行校准,并选择性地应用域随机化手段。研究人员通过系统辨识对关键动力学参数进行了精确校准,确保仿真模型能够尽可能接近真实无人机的动力学特性。然而,研究也发现,域随机化的应用需要极为谨慎。对于那些能够通过系统辨识达到合理精度的参数,过度引入域随机化可能会适得其反。这是因为不必要的随机化会显著增加强化学习的学习复杂度,导致性能下降。换句话说,域随机化并非 「越多越好」,需要通过合理选择哪些参数应用随机化。
-
在训练过程中使用较大的 batch size。在 SimpleFlight 的训练过程中,研究人员特别关注了 batch size 对策略性能的影响。他们通过实验发现,增大 batch size 尽管对仿真环境中的性能提升并不显著,但在真实无人机上的表现却得到了显著改善。这表明,大 batch size 在缩小模拟与现实之间的 Sim2Real Gap 方面,扮演了关键角色。这种现象背后的原因可能与强化学习的泛化能力有关。在大 batch size 的训练中,策略能够在更广泛的状态分布上进行学习,从而提升其应对真实环境中复杂情况的鲁棒性。这种改进不仅帮助策略更好地适应现实世界中的不确定性,还减少了从仿真到现实部署时可能出现的性能退化问题。
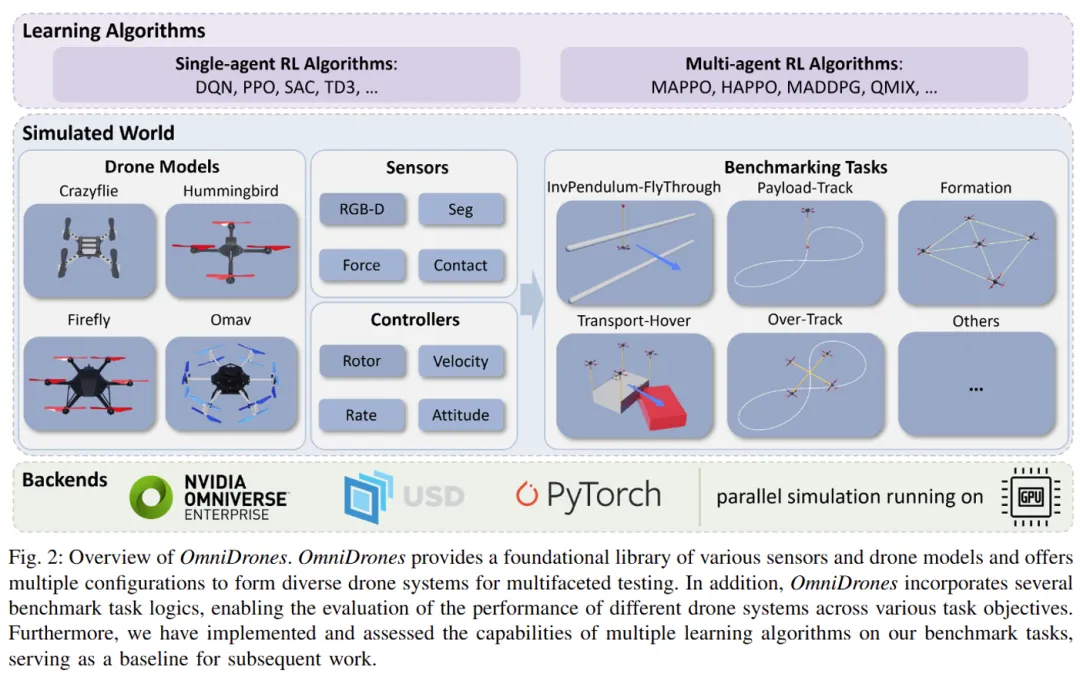
另外值得注意的是,SimpleFlight 框架集成在研究人员自主开发的高效无人机仿真平台 OmniDrones,该平台基于 NVIDIA 的 Isaac Sim 仿真环境搭建,允许用户在 GPU 并行模拟之上轻松设计和试验各种应用场景,可以实现每秒超过 10^5 步的仿真速度,极大地加速了强化学习策略的训练。
还等什么?赶快试试 SimpleFlight,把你的强化学习策略送上无人机吧!
Reference:
[1] Huang, K., Rana, R., Spitzer, A., Shi, G. and Boots, B., 2023. Datt: Deep adaptive trajectory tracking for quadrotor control. arXiv preprint arXiv:2310.09053.
[2] Eschmann, J., Albani, D. and Loianno, G., 2024. Learning to fly in seconds. IEEE Robotics and Automation Letters.
编辑:黄继彦
