清华推出SageAttention2,4比特量化让大模型注意力机制实现3倍加速,性能不掉点!
原文标题:4比特量化三倍加速不掉点!清华即插即用的SageAttention迎来升级
原文作者:机器之心
冷月清谈:
清华大学团队提出了名为SageAttention2的4比特即插即用Attention方法,解决了大模型中注意力机制运算效率低下的问题。相比于FlashAttention2和xformers,SageAttention2分别实现了3倍和4.5倍的推理加速,并且在视频、图像、文本生成等大模型上保持了端到端的性能表现。
SageAttention2的主要改进在于以下几个方面:
1. 平滑处理Q和K矩阵,以减小INT4量化带来的误差。SageAttention2在保留了原有对K的平滑处理的基础上,新增了对Q的平滑处理,从而显著提升了量化后的精度。
2. 采用Per-thread量化策略,将量化粒度细化到线程级别,进一步提高了4Bit QK^T乘法的精度。
3. 使用FP32寄存器累加FP8 PV矩阵乘法的结果,有效避免了FP22累加器带来的误差累积。
4. 对P和V采用E4M3数据格式的FP8量化,保证了精度接近FP16。
5. 提供了一种可选的V矩阵平滑技术,可以进一步提高PV矩阵乘法的精度。
SageAttention2易于使用,只需一行代码即可替换模型中原有的Attention函数,方便集成到各种大模型中。
SageAttention2的主要改进在于以下几个方面:
1. 平滑处理Q和K矩阵,以减小INT4量化带来的误差。SageAttention2在保留了原有对K的平滑处理的基础上,新增了对Q的平滑处理,从而显著提升了量化后的精度。
2. 采用Per-thread量化策略,将量化粒度细化到线程级别,进一步提高了4Bit QK^T乘法的精度。
3. 使用FP32寄存器累加FP8 PV矩阵乘法的结果,有效避免了FP22累加器带来的误差累积。
4. 对P和V采用E4M3数据格式的FP8量化,保证了精度接近FP16。
5. 提供了一种可选的V矩阵平滑技术,可以进一步提高PV矩阵乘法的精度。
SageAttention2易于使用,只需一行代码即可替换模型中原有的Attention函数,方便集成到各种大模型中。
怜星夜思:
1、SageAttention2 提到了在 Q、K 矩阵中存在异常值,这些异常值通常是什么样的?对模型训练和推理有什么影响?
2、除了文中提到的方法,还有哪些技术可以用来降低注意力机制的计算复杂度?
3、SageAttention2 的 per-thread 量化策略是如何提高4-bit QK^T 乘法精度的?
2、除了文中提到的方法,还有哪些技术可以用来降低注意力机制的计算复杂度?
3、SageAttention2 的 per-thread 量化策略是如何提高4-bit QK^T 乘法精度的?
原文内容
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]
论文共同第一作者张金涛、黄浩峰分别来自清华大学计算机系和交叉信息研究院,论文通讯作者陈键飞副教授及其他合作作者均来自清华大学计算机系。
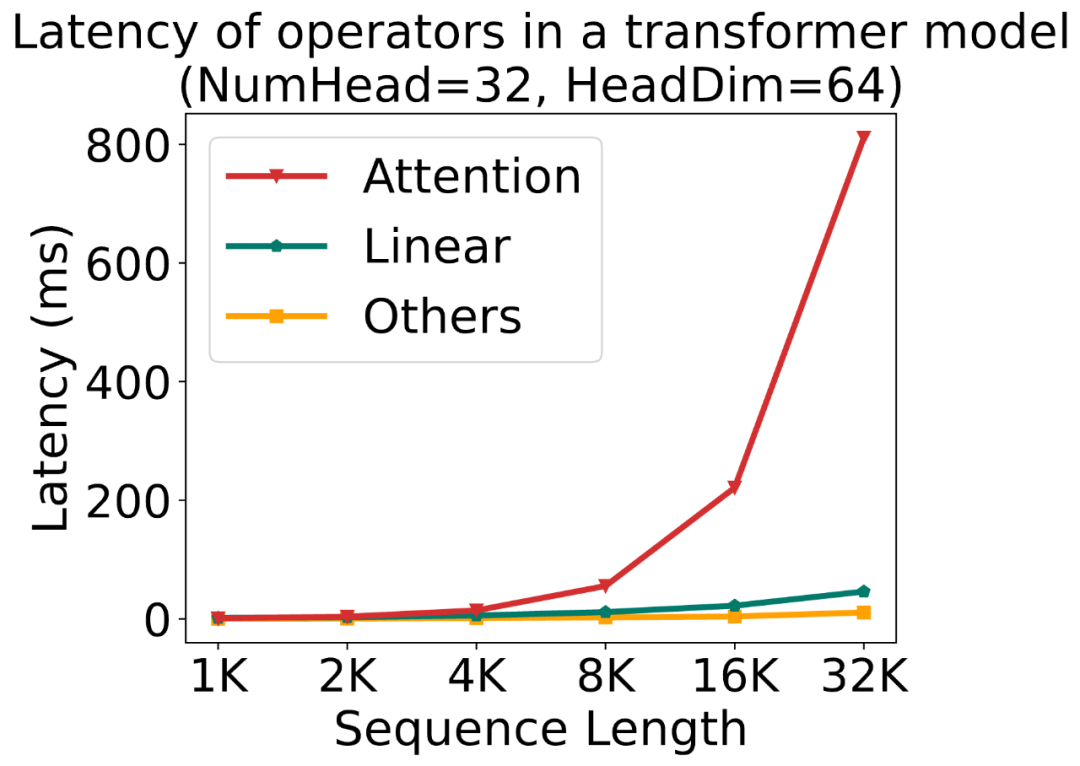
大模型中,线性层的低比特量化已经逐步落地。然而,对于注意力模块,目前几乎各个模型都还在用高精度(例如 FP16 或 FP32)的注意力运算进行训练和推理。并且,随着大型模型需要处理的序列长度不断增加,Attention(注意力运算)的时间开销逐渐成为主要开销。
此前,清华大学陈键飞团队提出的 8-Bit 的即插即用 Attention(),将 Attention 中的 QK^T 量化至 INT8,将 PV 保持为 FP16 精度并使用 FP16 精度的矩阵乘法累加器,同时提出 Smooth K 技术保持了量化 Attention 的精度,实现了 2 倍加速于 FlashAttention2,且在各类大模型上均保持了端到端的精度表现。
目前,SageAttention 已经被业界及社区广泛地使用于各种开源及商业大模型中,比如 CogvideoX、Mochi、Flux、Llama3、Qwen 等。
近日,陈键飞团队进一步提出了 4-Bit 的即插即用 Attention(SageAttention2),相较于 FlashAttention2 和 xformers 分别实现了 3 倍以及 4.5 倍的即插即用的推理加速,且在视频、图像、文本生成等大模型上均保持了端到端的精度表现。

-
论文标题:SageAttention2: Efficient Attention with Thorough Outlier Smoothing and Per-thread INT4 Quantization
-
论文链接:https://arxiv.org/abs/2411.10958
-
开源代码:https://github.com/thu-ml/SageAttention
即插即用举例
SageAttention2 实现了高效的 Attention 算子,可以实现即插即用的推理加速。输入任意 Q, K, V 矩阵,SageAttention2 可以快速返回 Attention Output (O)。
具体来说,SageAttention2 使用起来很方便,克隆仓库(git clone https://github.com/thu-ml/SageAttention)并执行 python setup.py install 后,只需一行代码便可以得到 Attention 的输出,可以使用该接口方便地替换任意模型中的 Attention 函数:

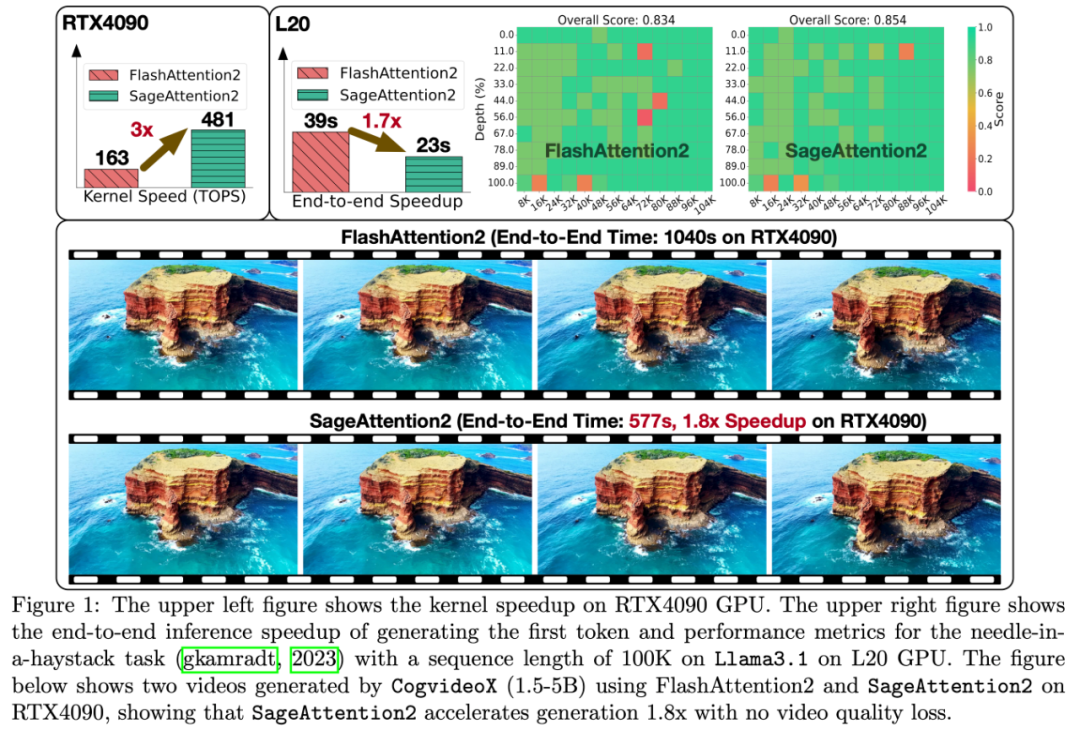
效果上,以开源视频生成模型 CogvideoX-1.5-5B 为例,使用 SageAttention2 可以端到端加速 1.8 倍,且生成的视频无损:
使用全精度 Attention
使用 SageAttention2
更重要的是,SageAttention2 提供了比 SageAttention 更广泛的硬件支持。除了在 RTX 4090 上可以 3 倍加速于 FlashAttention 外,在 L20、L40、L40S 可以实现 2 倍的加速,在 A100、A800、A6000 上可以实现 1.45-1.6 倍的加速(基于 SageAttention)。
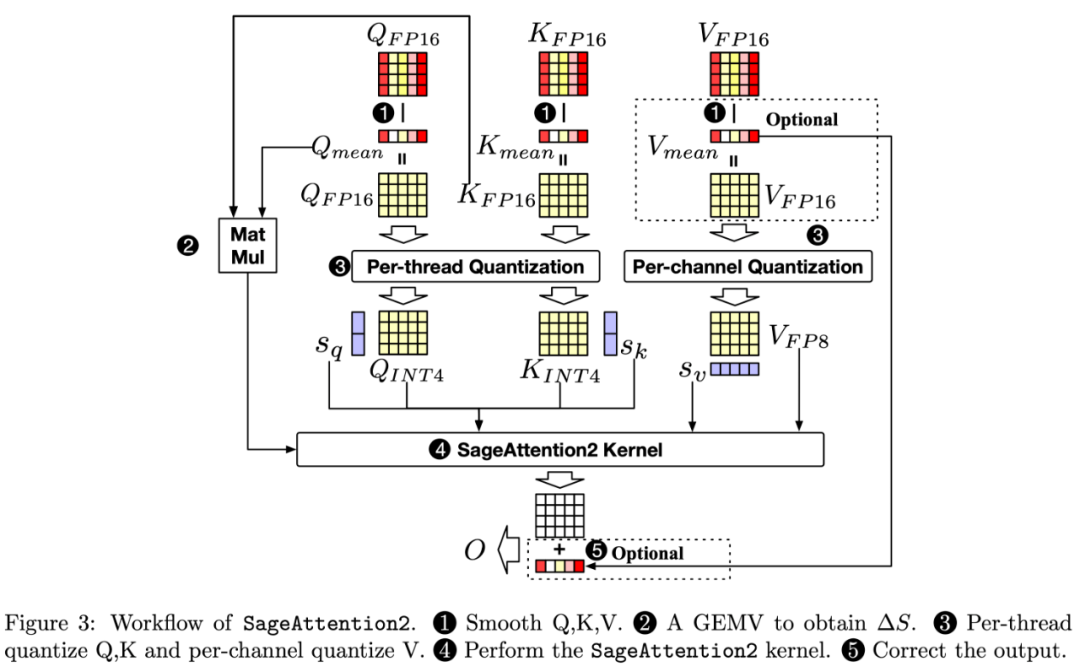
接下来,研究团队将从前言、挑战、方法以及实验效果四个方面介绍 SageAttention2(总体流程图如下图)。
前言
随着大模型需要处理的序列长度越来越长,Attention 的速度优化变得越来越重要。下图展示了一个标准的 Transformer 模型中各运算的时间占比随序列长度的变化:
为了方便指代注意力运算中的矩阵,我们先回顾一下注意力的计算公式:
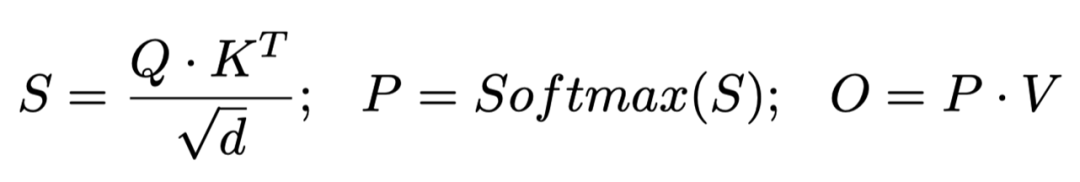
尽管 SageAttention 提出将 Q,K 量化至 INT8,将 P,V 保持 FP16 精度且采用 FP16 的矩阵乘法累加器来加快 Attention 的速度。然而,这样做的缺点是:1)INT8 的矩阵乘法只达到了一半的 INT4 矩阵乘法的速度,2)使用 FP16 的乘法累加器的 FP16 的矩阵乘法的加速只在 RTX4090 和 RTX3090 显卡上有效。
为了克服上述缺点,SageAttention2 提出将 Q, K 量化至 INT4,并将 P, V 量化至 FP8 来加速 Attention。然而,这样做的挑战是很大的。
4-Bit 注意力量化有什么问题?
研究团队发现直接将注意力运算中的 Q, K 量化为 INT4 后将会导致在几乎所有模型和任务上都会得到极差的结果,例如,在 CogVideoX 文生视频模型中,会得到完全模糊的视频;Llama2-7B 进行四选一选择题任务上得到 25% 的准确率。

经过仔细分析后,研究团队发现主要是两个原因导致了量化注意力的不准确:
(1)INT4 的数值范围相比 INT8 非常小,导致其量化误差在 Q,K 矩阵中出现一些异常值时会变得十分明显,恰好大多模型都在 Q, K 中表现出来了较大的通道维度的异常值。这极大削减了 QK^⊤矩阵乘法的精度。
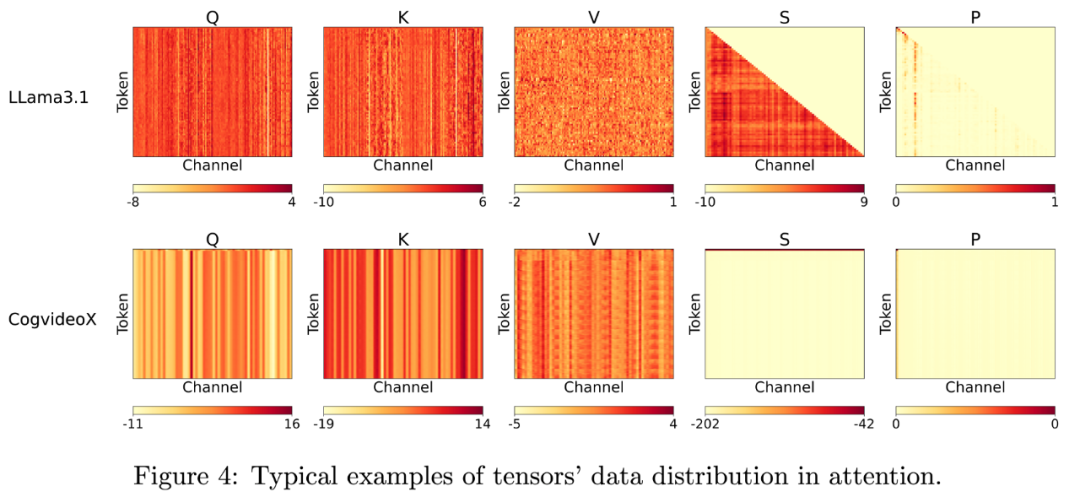
(2)研究团队发现 Nvidia 的显卡上,FP8 的矩阵乘法指令 (mma.f32.f8.f8.f32) 的乘法累加器并不是官方宣称的 FP32 精度,而是只有 FP22 精度,这导致了 PV 矩阵乘法出现较大的累加误差。

技术方案
为了解决上述的两个挑战,研究团队提出了对应的解决办法。
(1)保留 SageAttention 中对 K 进行平滑处理的同时,提出对 Q 进行平滑处理:Q – mean (Q)。其中 mean (Q) 是沿着通道维度的平均值向量。完成该平滑操作后需要在 Attention 计算过程中将 mean (Q) 和 K^T 的向量与矩阵乘法的结果补偿到 S 中。
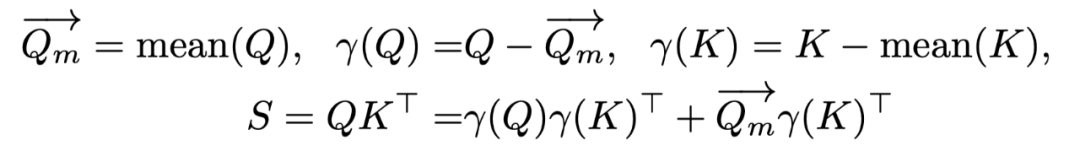
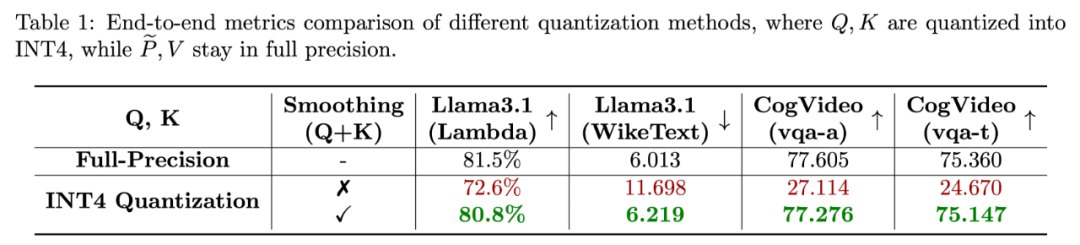
这使得相比直接量化 Q, K 至 INT4 的准确度有质的改变,如下表展示了对比了该方法和直接量化 Q, K 至 INT4 在 Cogvideo 和 Llama3.1 上的端到端表现。
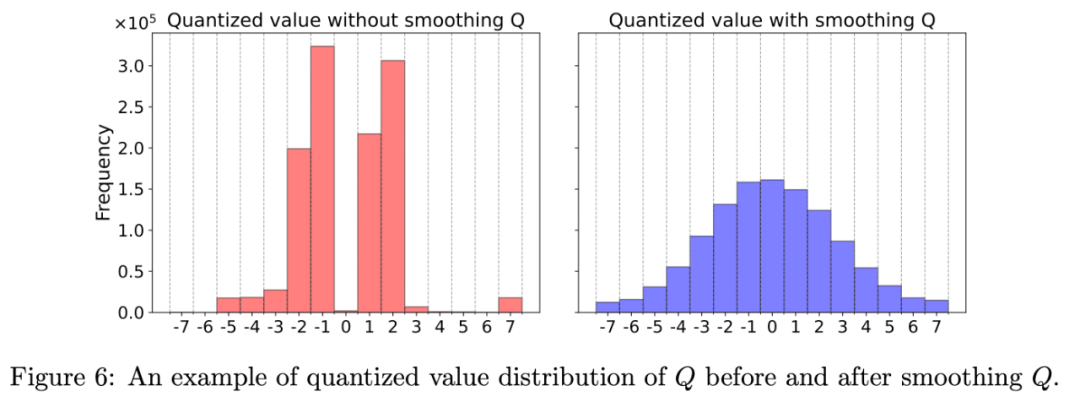
矩阵 Q 平滑前后的数据分布可视化的结果如下,可以发现平滑后的 Q 对 INT4 数据范围的利用度更高:
(2)对 Q, K 进行 Per-thread 量化。对于矩阵 Q, K,SageAttention2 采用了根据 mma 指令对矩阵内存排布的要求,对 Q,K 中的 Token 按照 GPU 线程进行分组,使量化粒度比 SageAttention 中的 per-block 细化 16 倍,极大提高了 4Bit 的 QK^⊤乘法准确度的同时不引入任何额外开销。
具体来说,在 SageAttention 中,每个 Q 的块将被划分为 c_w 个段,由 GPU 流处理器(SM)中的 c_w 个 GPU warp 处理。然后,每个包含 32 个线程的 warp 会使用 NVIDIA 的 mma.m16n8k64 PTX 指令来执行 QK^⊤运算。根据这一指令的布局要求,研究团队发现一个 warp 内的 Q [8×(n%8)] 可以共用一个量化缩放参数,而一个 warp 内的 K [8×(n%8)] 和 K [8×(n%8+1)] 也可以共用一个量化缩放参数,其中 n 是 token 索引。
这种量化方法更为细致且不增加额外开销。这是因为它根据 MMA 指令的布局将不同的 GPU 线程分配到不同的量化 Token 组,每个线程只对应一个量化缩放参数进行反量化。而非 Per-token 量化那样,每个线程对应多个量化缩放参数。
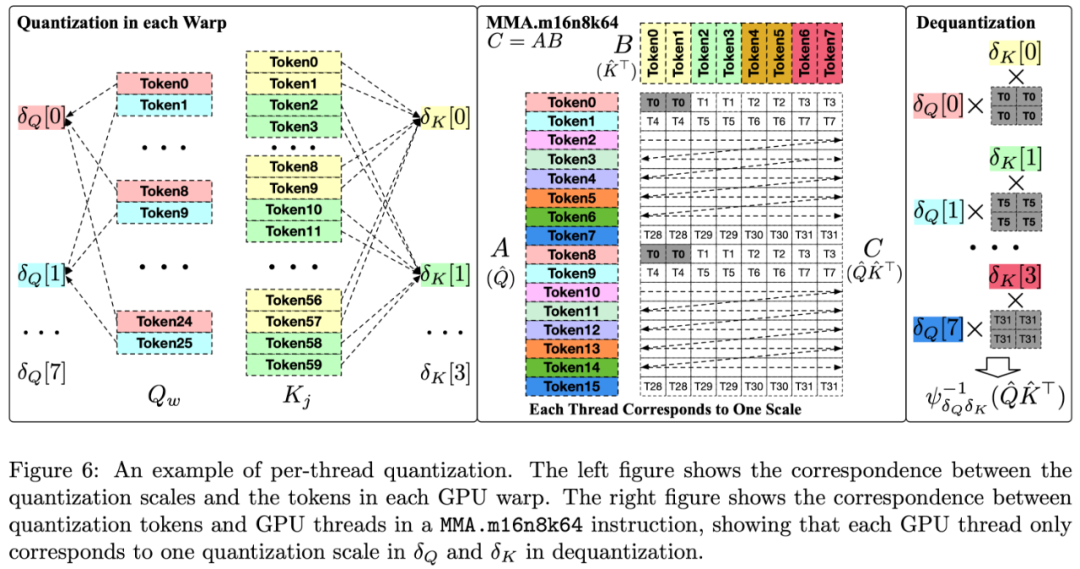
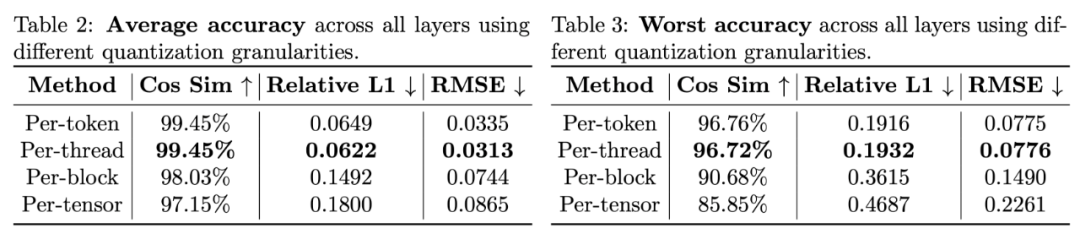
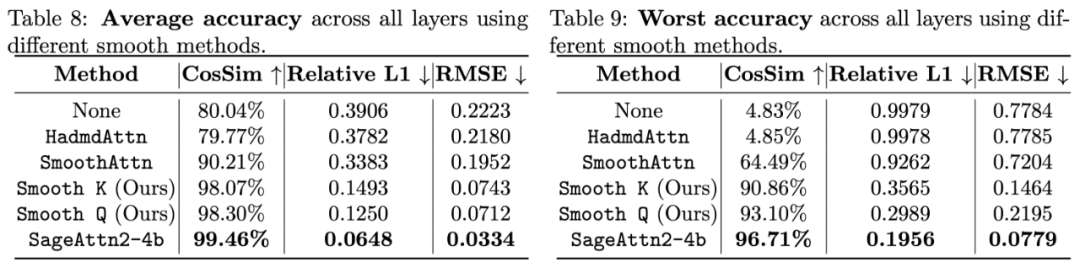
如下表所示,可以发现 per-thread 量化的准确度比 SageAttention 中采用的 per-block 量化高得多,准确度和 per-token 量化几乎没有差别。
(3)对 FP8 的 PV 矩阵乘法采用 FP32 的寄存器将每次 FlashAttention 分块粒度的 PV 的 FP22 的乘法结果累加起来。这种做法可以有效地避免 FP22 的乘法累加器沿着序列长度累积过多的误差,将 FP22 累加器带来的误差控制在 FlashAttention 分块的粒度中,提高了 FP8 的 PV 乘法的准确度。
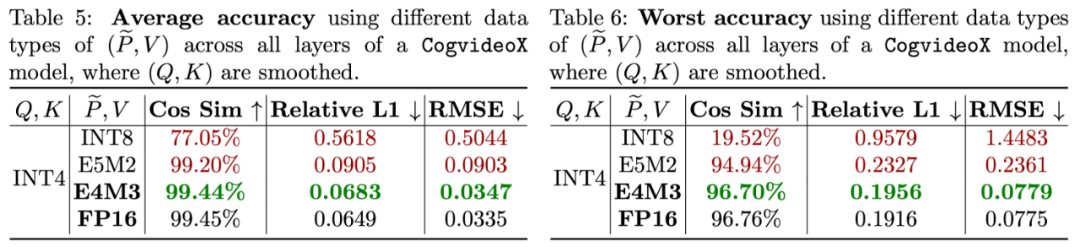
(4)针对 P 和 V,研究团队对比了多种量化的数据类型,对比发现使用 E4M3 数据格式的 FP8 精度最准确,基本接近了 FP16 的准确度。因此采用将 P 和 V 量化至 E4M3。
下图展示了 SageAttention2 的算法流程:

SageAttention2 共实现了两种 Kernel,区别在于对 Q, K 进行 INT4 量化还是 INT8 量化:

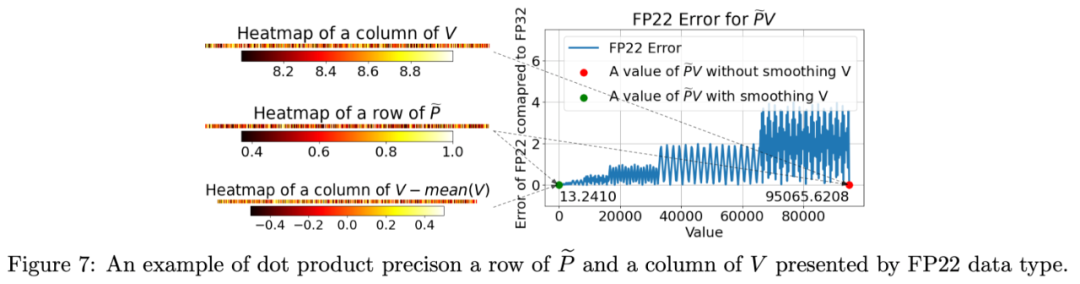
此外,SageAttention2 还提出一种可选的对矩阵 V 进行平滑处理的技术,可以进一步提高 PV 矩阵乘法的准确度。具体来说,当某些模型中 V 矩阵具有通道维度的偏移时,可以将 V 减去其通道维度的平均值 mean (V) 来去除偏移,之后进行正常的量化 Attention 运算。只需要对最终 Attention 的 Output 加上 mean (V) 即可保持计算的正确性。
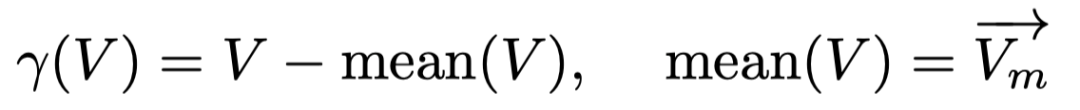

这种做法可以提升准确度的原因如下图所示。在 FP22 的表示范围内,数值越大,相比 FP32 的误差越大。而 P 的范围是 0~1 之间,那么当 V 矩阵的列有较大的数值偏移时,PV 的 FP22 累加器的精度就越差,通过平滑 V 去除偏移后,就可以加强 PV 矩阵乘法的准确度。
实验效果
SageAttention 实现了底层的 GPU CUDA Kernel,在算子速度以及各个模型端到端准确度上都有十分不错的表现。
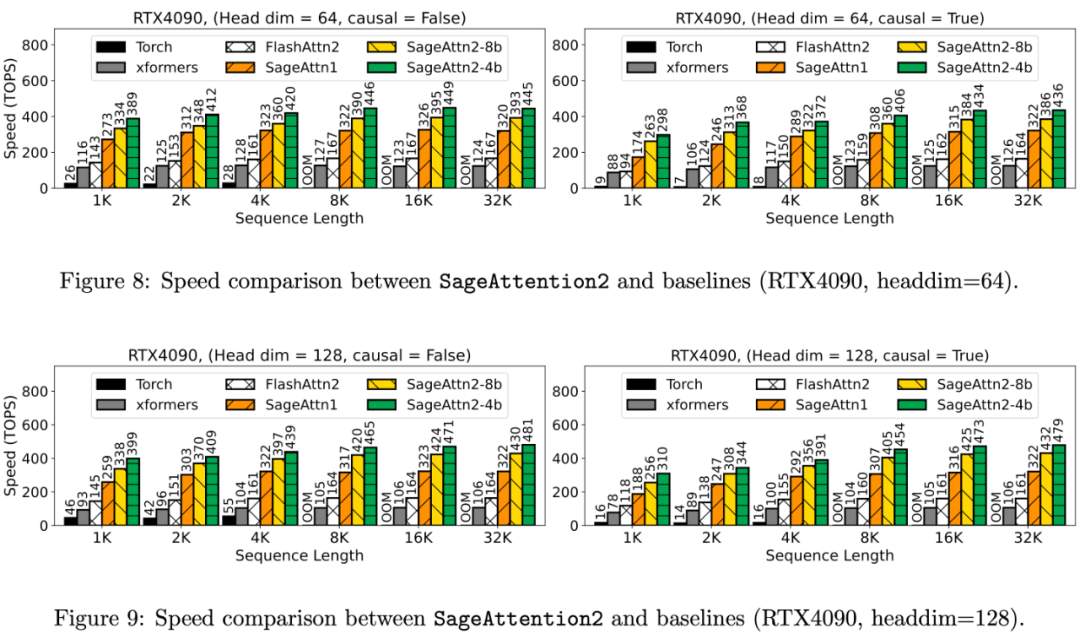
具体来说,算子速度相比于 FlashAttention2 和 xformers 有大约 3 倍以及 4.5 倍的加速:

算子的准确度方面也是比对 Q, K 进行 SmoothQuant 和 Hadamard 变换要更加准确:
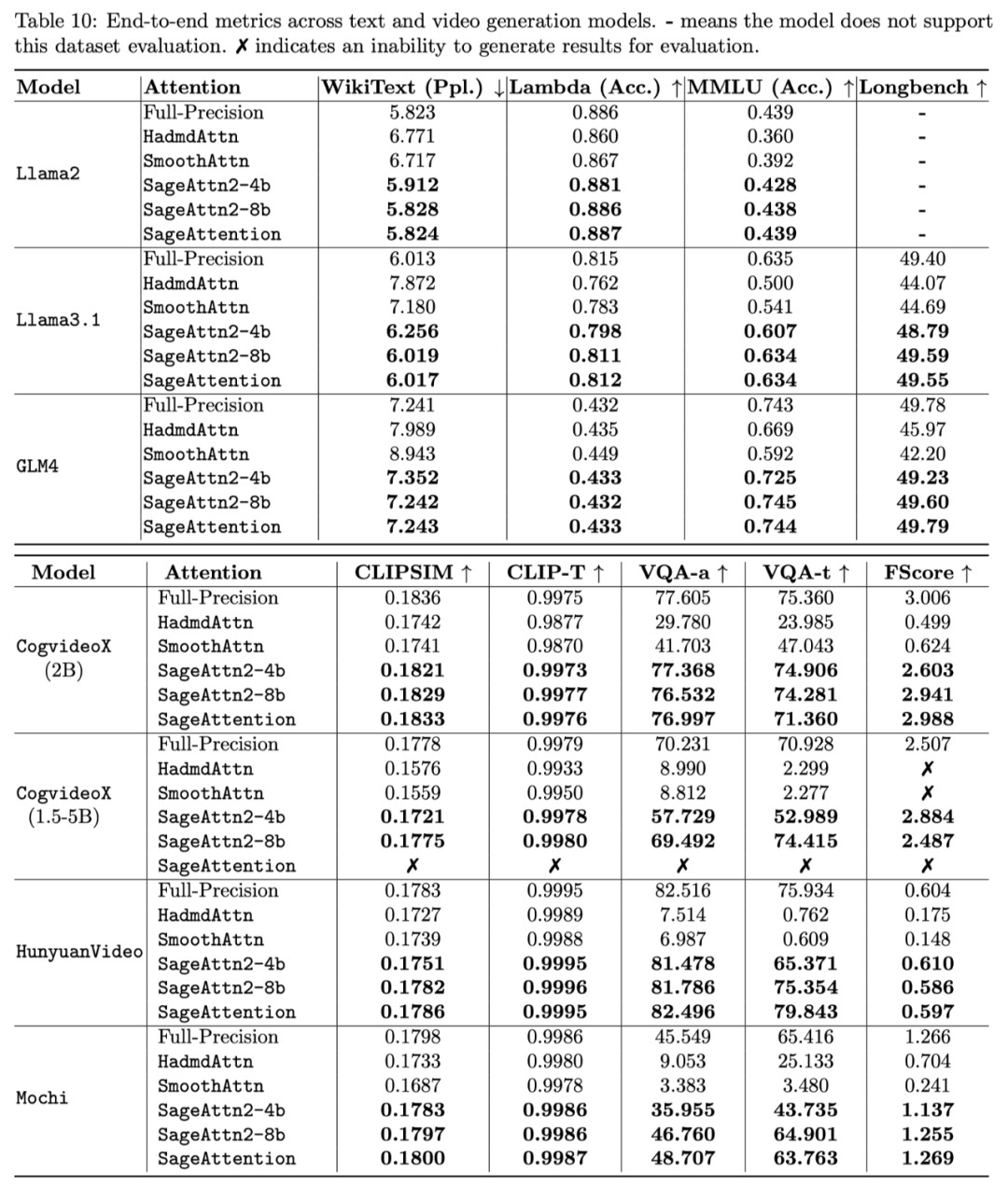
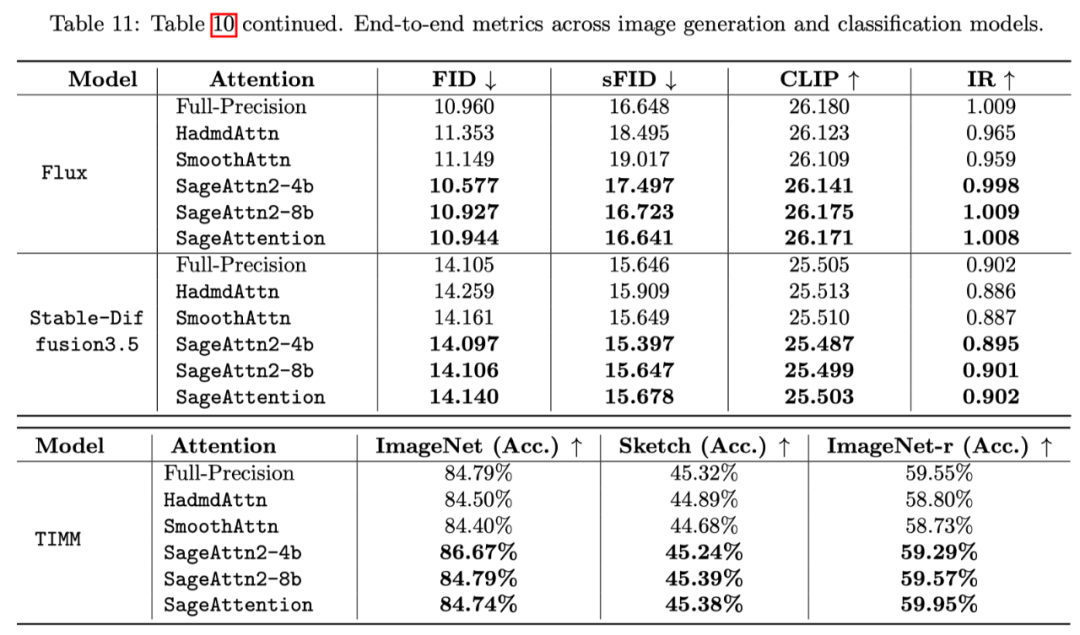
各模型在真实场景的端到端精度表现中,在视频、图像、文本生成等大模型上均保持了端到端的精度表现:
下图是在 HunyuanVideo 中的可视化实例:

下图是在 Cogvideo 中的可视化实例:

下表展示了各个语言、视频、图像生成模型中 SageAttention2 的端到端精度表现:
端到端的速度表现上,SageAttention2 两个 Kernel 的实现均可以有效地对长序列模型进行加速,比如可以端到端 1.8 倍加速 CogVideoX1.5-5B,其他模型上也均有 1.6 到 1.8 倍的提速。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]