国产AI音乐平台崛起,一键生成MV,中文创作更胜一筹,挑战Suno!
原文标题:围猎Suno!国产AI音乐三巨头:华语创作称雄,MV一键生成全球首创
原文作者:机器之心
冷月清谈:
“天谱乐”是全球首个支持多模态配乐的大模型,可以根据文本、图片或视频生成音乐,并一键生成MV,这比Suno的SunoScenes功能更早推出。其生成的中文歌曲质量更高,更贴合中国用户的审美。
字节跳动的豆包音乐大模型也已全面接入旗下App,支持文本和图片生成音乐。昆仑万维的“天工 SkyMusic”则专注于文本生成音乐,音质表现出色,并支持方言歌曲创作。
与国外平台相比,国内平台更注重降低创作门槛,让普通用户也能轻松创作音乐。同时,它们也积极探索商业化应用,例如为短视频、广告等提供BGM。未来,AI音乐将在更专业的领域发挥作用,例如为专业人士提供创作辅助,实现更精细的控制和更高效的创作流程。
怜星夜思:
2、AI生成的音乐是否拥有版权?如果用AI生成的音乐进行商业用途,需要注意哪些法律问题?
3、AI音乐创作对传统音乐行业会带来哪些冲击?未来的音乐人需要具备哪些新的能力?
原文内容
机器之心原创
终于,谷歌新一代视频生成大模型 Veo2 把 Sora 给秒了:「更懂人间烟火」、「懂电影拍摄技巧」、「分辨率高达 4K 」……
视频生成已经步入影视级,但,还是个默片。
Veo2生成视频,来自X网友 @moderncpp7,背景音效是作者手动添加。
国内互联网公司却开辟了新玩法,让「视听同步生成」变成现实。只需上传一段视频,音乐大模型就能立刻整出 30 秒的 MV !
中文吐词清晰,声音自然,歌词高度贴合画面,韵律也很中国,因为视频只有16秒所以MV也就16秒。
过去整这么一出,还有点折腾。得先用音乐大模型生成音频,再用剪辑工具把视频和音频「拼」起来。
现在,音乐大模型直接把 MV 给你端上来,连提示词都省了。
一键配乐
「天谱乐」拿下「全球首创」
今年 7 月,音频垂直赛道独角兽趣丸科技推出了全球首个多模态配乐大模型「天谱乐」。
趣丸科技一直深耕音乐、音频领域,旗下的拳头产品有 TT 语音,如今累计注册用户已超 2 亿,是国内最大的兴趣社交平台之一。

AI音乐创作平台-天谱乐官网
「天谱乐」支持文本生曲,最长 3.5 分钟。
文本生成歌曲,提示词:写一首关于当代年轻人青春热血的歌曲。
除了文本,「天谱乐」 还支持图片生曲、视频生曲,也是全球首个落地多模态能力的 AI 音乐应用:
用户上传图片或 60 秒内视频,就能立刻生成与之高度匹配的 BGM,呈现 30 秒 MV 效果。
而 Suno 直到 10 月才推出了 SunoScenes ,允许用户通过上传照片和视频作为提示词,生成与之匹配的 30 秒音乐。
我们上传了一张《好东西》的剧照,「天谱乐」立刻生成了一首歌曲。
给李子柒的一段制茶视频配上音乐,无论是歌词还是曲风都带有浓浓的国风。
我们知道,Suno V3 和 Udio 生成的歌曲都有带着明显的金属质感,听起来像压缩过的 MP3 ,尤其是人声部分特别明显,中文人声唱词更是差强人意。
在最具挑战的人声问题上,「天谱乐」中文人声唱词在多次技术迭代之后,已经达到了专业级人声效果,显著减少了电音感,拥有更加真实的歌手声音,接近音乐发行的级别。
「天谱乐」此次的技术突破,来自于天谱乐大模型在长序列音乐语意建模和高质量音频空间建模上实现进一步突破,高度还原音乐音频在高维空间的连续信号表征,实现音乐性和音质的飞跃。
不过,要生成理想的 MV 效果,歌曲必须高度贴合内容,这意味着音乐模型还要能理解画面蕴含的情绪、主题和细节。
基于大模型,「天谱乐」能准确识别出画面情绪和基调,完成卡点,生成精准匹配的背景音乐,这种先进的多模态理解与生成能力使「天谱乐」达到了国际领先水平。
目前,「天谱乐」大模型已全面接入趣丸旗下唱鸭 App,在国内率先实现产品化应用,目前已有 4600 万人注册使用唱鸭 App 或天谱乐官网,累计创作近 1000 万首 AI 歌曲。
「零门槛」音乐生成
国产应用三分天下
2023 年 12 月底上线的 Suno 迅速成为 2024 年 AI 音乐领域的焦点。在国内,类似 Suno 的音乐创作模型接连面世,趣丸科技「天谱乐」也与字节跳动、昆仑万维两家音乐大模型形成「三分天下有其一」的格局。
在这场「零门槛」AI 音乐生成角逐中,昆仑万维最先发力。旗下的音乐生成模型「天工 SkyMusic 」基于昆仑万维的「天工 3.0 」超级大模型打造,能够快速生成多种风格的音乐作品。
在音质上表现出色,还支持粤语、成都话等方言歌曲创作。目前仅支持文本生曲。
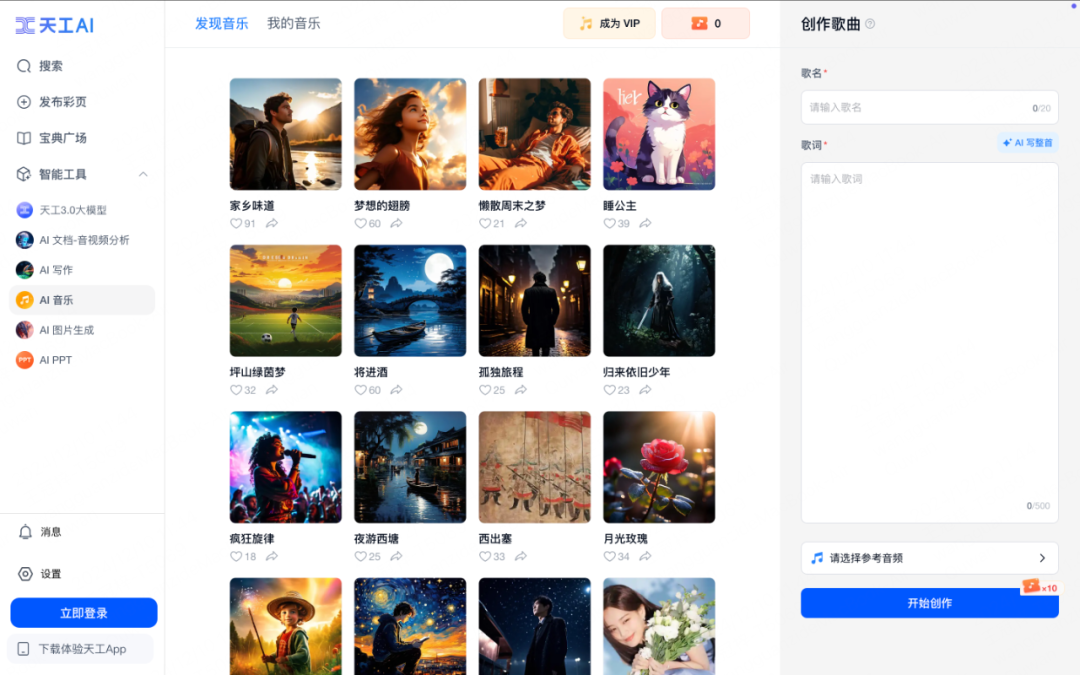
随后,昆仑万维又推出 AI 流媒体 App( Melodio )和 AI 商用音乐创作平台( Mureka ),致力于让全球用户都能轻松进行音乐表达。
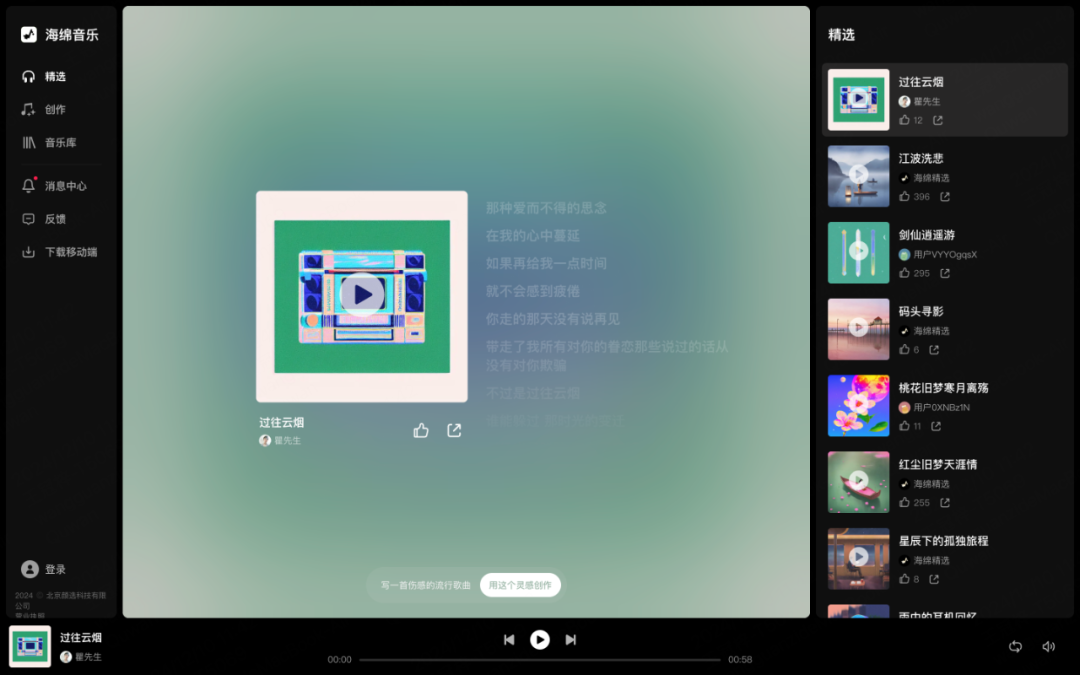
8 月,字节跳动携豆包音乐大模型加入 AI 音乐战局,此时,趣丸科技推出「天谱乐」已两月有余。
字节的模型一上线就全面接入豆包 App、海绵音乐 App(字节旗下 AI 音乐创作工具),向所有用户开放。用户只需输入简单的提示词,就能得到包含歌词、曲谱和演唱的完整歌曲作品,还内置十多种风格和情绪选项。
相比 Suno,海绵音乐在人声清晰度、中文发音等方面进行了优化,更能驾驭国风类音乐。
目前支持文本、图片生曲,但不包括视频输入。
相比之下,拥有海量版权的在线音乐巨头则审慎得多。针对创作者,网易云音乐和腾讯音乐分别推出了具备 AI 辅助创作功能的「天音」和「启明星」平台。
「天音」更适合专业创作者,在「一键生成」上并没展现出领先其他 AI 生成应用的优势。「启明星」接入了「琴乐大模型」,仍聚焦于纯音乐创作,并未涉足涉及人声的歌曲生成。
对此,腾讯音乐表示,歌曲生成等复杂能力可以拭目以待。作为这一轮 AI 技术下的用户平台,他们选择踊跃但理性投入。
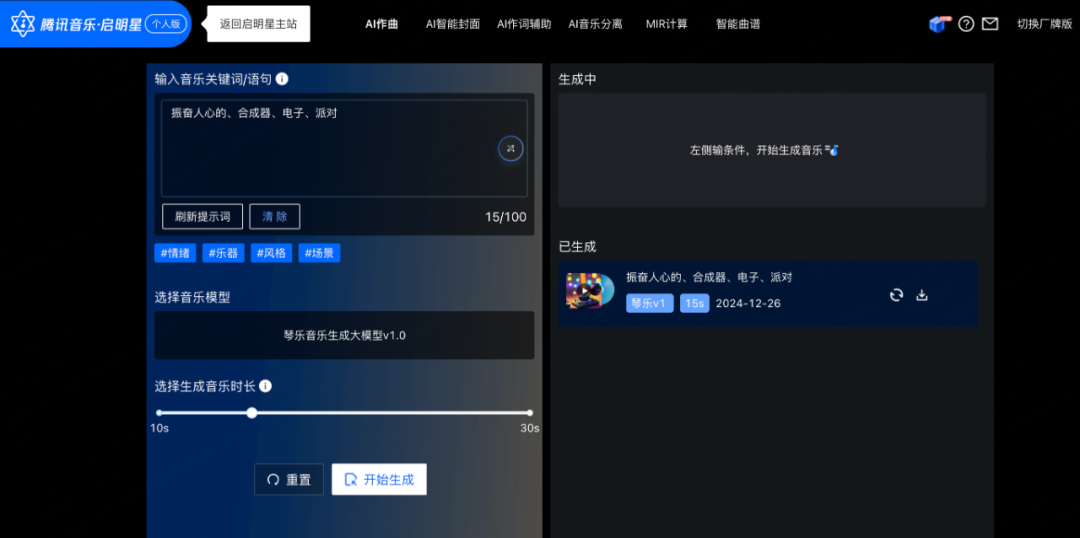
「启明星」接入了腾讯音乐「琴乐大模型」,输入曲风、乐器、场景等关键词就会生成一段纯音乐。
商用领跑
跨界共创
技术可以跨越国界,但应用一定要满足本地用户的需求。与当前已经落地的 AIGC 应用类似,国内 AI 音乐模型的发展也更接地气。
得益于更容易获符合本土市场偏好的华语和国风音乐训练数据,国内模型能够更准确地把握中国听众的音乐审美偏好,因此在中文歌曲创作上,「天谱乐」等国产音乐大模型明显优于市场上最先进的 AI 音乐模型之一 Suno。
Suno 为杜甫《小至》创作的歌曲,无论人声吐词还是旋律,都明显「水土不服」。
同时,国内音乐大模型市场也展现出独特的竞争格局。与 Suno 等专注技术创新的初创企业不同,这里的主导者是一批深耕内容与文娱领域的互联网企业。
他们无一例外地将重点放在降低创作门槛上,帮普通人生成个性化音乐,除了想在 C 端市场快速建立起存在感,也源于自身业务的深层需求,如平台在流量增长进入瓶颈期后尽可能地留住用户。
数据显示,2023 年抖音用户投稿超过 100 亿,其中有 78% 的内容都含有 BGM ,对 30 秒到 1 分钟不等的配乐需求量巨大。传统模式下,平台要么为此支付高额版权费,要么自建 BGM 库。音乐大模型能低成本批量生成个性化 BGM,满足迫切的业务需求。
作为国内最大的兴趣社交平台之一,趣丸也顺应年轻人消费音乐的方式从「听唱」转向「唱作」,将音乐大模型整合进唱鸭等产品,通过提升用户体验来强化其社交生态。
不少从业者认为,短视频、广告宣传、直播、游戏等场景的 BGM 很可能率先被 AI 取代。这些「快餐」内容对创作专业性、音质和 IP 要求都相对较低,更注重快速生产和个性化定制,与当前 AI 音乐的技术优势完美契合。
2024 年,音乐大模型横空出世终于补齐了 AIGC 时代「创作平权」的最后一块拼图。随着技术持续迭代,国内 AI 音乐应用也正朝着双轨并行的方向演进。
以「天谱乐」为例,一方面践行着「人人都能玩点音乐」,为普通用户提供娱乐性音乐生成服务;另一方面也在为专业人士提供更加实用的创作辅助,创造更大价值。
「天谱乐」网页端已经为广告、影视和音乐从业者提供专家模式,实现更精准的参数控制。
另外在视频配乐上,镜头卡点识别功能将传统需要剪辑师手动完成的情绪匹配和卡点对齐过程自动化,极大地提升了工作效率。
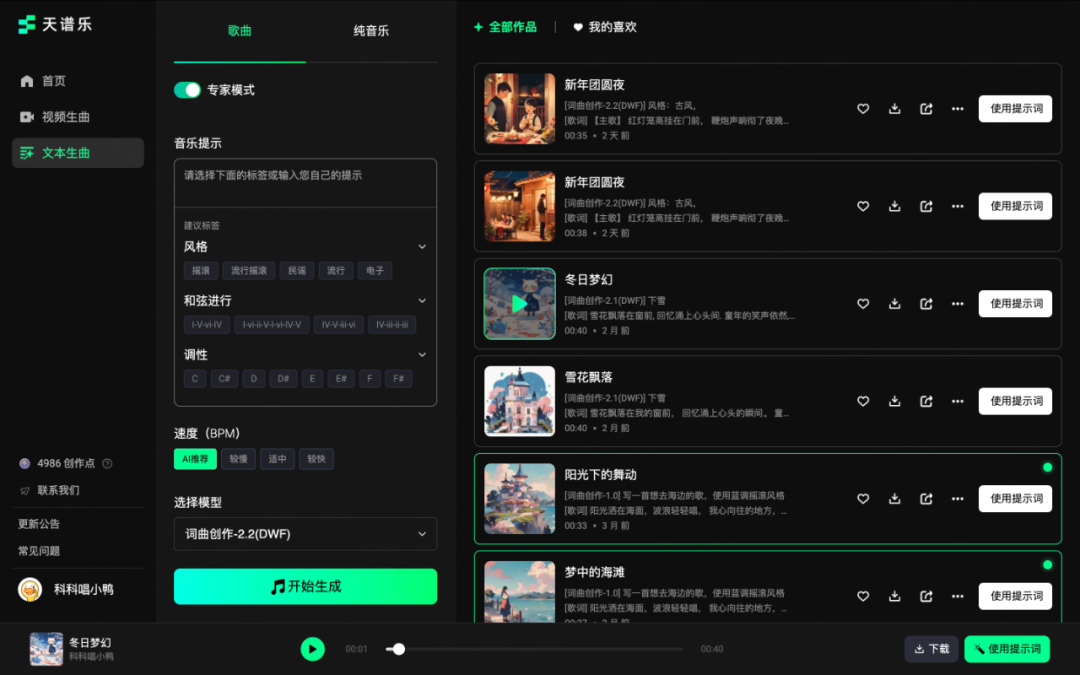
「天谱乐」网页端(也是「唱鸭」的网页版AI作曲),为广告、影视和音乐从业者提供音乐专家模式,具备更精准的参数控制和更高的创作自由度。
据了解,「天谱乐」即将推出 MidiRender 功能,它像音乐界的 ControlNet,让创作过程更可控:
创作者先确定核心创意和基础旋律——比如像《星球大战》主题曲开头那样具有标志性的动机旋律,再由 AI 协助完成歌词填充和编曲工作。
MidiRender 不仅强化了人类对音乐生成的细节把控,也大大缩短了传统创作中从动机旋律到完整作品需要的数周乃至数月时间。
创作者输入原创音乐片段:
「天谱乐」填充歌词完成编曲:
有了 MidiRender ,「天谱乐」最终做出来的音乐,跟最初人类作曲家的动机旋律完全匹配。
事实上,业界对提升 AI 音乐「可编辑能力」的呼声一直很高。端到端生成模式难以进行编辑调整,也难以获取分轨、MIDI 等制作文件,要让音乐生成工具真正融入创作人士的工作流程,必须实现从盲盒式生成到精确控制的转变。
视觉生成的技术轨迹也证明了这一点:从 DALL-E 「盲盒式生成」到 Midjourney 的局部重绘,再到 Stable Diffusion 的 ControlNet,视频生成可控性也在逐步提升。
AI 大模型作为工具,最终还是要服务于人,而不是去抢夺创作主导权,趣丸科技副总裁贾朔认为。未来,AI 和艺术家会是合作伙伴,毕竟,谁不能也不想独自创造音乐的未来。