提升Transformer模型处理变长序列效率,FlashAttention2和xFormers助力性能飞跃
原文标题:Transformer模型变长序列优化:解析PyTorch上的FlashAttention2与xFormers高性能注意力机制
原文作者:数据派THU
冷月清谈:
首先,文章分析了变长序列带来的挑战:传统的填充方法会导致计算资源浪费,而简单的序列连接策略又会带来O(N²)的计算复杂度。
为了解决这个问题,文章提出并比较了几种优化方案:
1. 动态填充:根据批次中最长序列的长度进行填充,减少了不必要的计算开销,实验显示在评估和训练模式下都有性能提升。
2. PyTorch NestedTensors:利用PyTorch的NestedTensors特性,避免了显式填充操作。实验结果显示,在编译模式下,性能提升显著,约为基准的3倍。
3. FlashAttention2:使用flash-attn 2.7.0版本中的`flash_attn_varlen_func`函数,通过高效的内存访问模式、精确的序列边界追踪以及优化的CUDA核函数实现,分别在评估和训练模式下实现了2.6倍和2.1倍的性能提升。
4. xFormers:利用xFormers库中的`memory_efficient_attention`操作符和`BlockDiagonalMask`掩码机制,实现了高效的内存管理和优化的计算模式。在评估和训练模式下都取得了接近FlashAttention2的性能提升。
最后,文章还探讨了如何在HuggingFace框架中集成这些优化技术,以GPT2模型为例,展示了如何通过简单的配置修改或少量代码修改来启用FlashAttention2,并通过无填充优化进一步提升性能。实验结果表明,无填充优化方案相比原始基准测试,性能提升了约2.5倍。
怜星夜思:
2、除了文中提到的这些优化方法,还有哪些技术可以提升Transformer模型的性能?
3、对于非常长的序列,比如几万个token,这些优化方法还能有效吗?
原文内容

来源:DeepHub IMBA本文约10000字,建议阅读15+分钟
本文将探讨变长输入序列这一挑战——这是真实世界数据(如文档、代码、时间序列等)的固有特征。
随着生成式AI(genAI)模型在应用范围和模型规模方面的持续扩展,其训练和部署所需的计算资源及相关成本也呈现显著增长趋势,模型优化对于提升运行时性能和降低运营成本变得尤为关键。作为现代genAI系统核心组件的Transformer架构及其注意力机制,由于其计算密集型的特性,成为优化的重点对象。
在前面的文章中,我们已经介绍了优化注意力核函数能够显著提升Transformer模型的性能。本文将进一步探讨变长输入序列这一挑战——这是真实世界数据(如文档、代码、时间序列等)的固有特征。
批处理变长输入的技术挑战
在典型的深度学习工作负载中,单个样本在传输至GPU并输入AI模型之前需要进行批处理。批处理不仅能提高计算效率,还能在训练过程中促进模型收敛。通常情况下,批处理操作是通过在新的维度(批次维度)上堆叠所有样本张量来实现的。但是torch.stack操作要求所有张量具有相同的形状,这与变长序列的特性相矛盾。
解决这一挑战的传统方法是将输入序列填充至固定长度后再进行堆叠。这种方法需要在模型中实现适当的掩码机制,以确保输出不受填充元素的影响。在注意力层中,填充掩码用于标识哪些token是填充token,从而在计算注意力时予以忽略(参考PyTorch MultiheadAttention的实现)。这种填充方法会导致GPU资源的显著浪费,增加计算成本并降低开发效率。这一问题在大规模AI模型中表现得尤为突出。
序列连接策略
避免填充的一种替代方案是沿着现有维度连接序列,而非在新维度上堆叠。与torch.stack不同,torch.cat允许处理不同形状的输入张量。连接操作的输出是一个长度等于所有输入序列长度之和的单一序列。为了使这种方案有效,需要为序列配备注意力掩码,确保每个token只关注其原始序列中的其他token,这一过程通常被称为文档掩码。若用N表示所有序列的总长度,采用大O符号表示,则掩码的空间复杂度为O(N²),注意力层的计算复杂度也为O(N²)(因为它需要在计算注意力分数后才应用掩码),这使得该方案的效率极低。
注意力层优化技术
针对上述问题,专门设计的注意力层提供了解决方案。与标准注意力层不同,这类优化的注意力核函数采用了更高效的计算策略。标准注意力层会计算完整的O(N²)注意力分数集合后再应用掩码,而优化后的核函数从设计之初就只计算实际需要的分数。本文将介绍几种具有不同特点的解决方案。
与HuggingFace模型的集成方案
对于使用预训练模型的开发团队来说,迁移至这些优化方案可能存在一定难度。本文将演示如何通过HuggingFace的API简化这一过程,使开发人员能够以最小的代码改动实现这些优化技术的集成。
-
本文中涉及的平台、库或优化技术的使用并不构成对其的推荐。最适合的技术选择将取决于具体应用场景的要求。
-
部分讨论的API仍处于原型或测试阶段,其接口可能在未来发生变化。
-
文中提供的代码示例仅供参考,不保证其在生产环境中的适用性、最优性或稳定性。
实验性LLM模型实现
为了深入讨论这些优化技术,我们首先实现一个简化版的生成模型(部分参考了已有的GPT模型架构)。对于完整的语言模型构建指南,建议参考相关领域的专业教程。
Transformer模块实现
首先构建一个基础的Transformer模块,其设计特别考虑了对不同注意力机制和优化策略的实验需求。虽然该模块执行的计算与标准Transformer模块相同,但我们对传统的运算符选择进行了微调,以支持PyTorch NestedTensor输入的要求。
# 通用导入 import time, functoolstorch导入
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn定义Transformer配置参数
BATCH_SIZE = 32
NUM_HEADS = 16
HEAD_DIM = 64
DIM = NUM_HEADS * HEAD_DIM
DEPTH = 24
NUM_TOKENS = 1024
MAX_SEQ_LEN = 1024
PAD_ID = 0
DEVICE = ‘cuda’class MyAttentionBlock(nn.Module):
def init(
self,
attn_fn,
dim,
num_heads,
format=None,
**kwargs
):
super().init()
self.attn_fn = attn_fn
self.num_heads = num_heads
self.dim = dim
self.head_dim = dim // num_heads
self.norm1 = nn.LayerNorm(dim, bias=False)
self.norm2 = nn.LayerNorm(dim, bias=False)
self.qkv = nn.Linear(dim, dim * 3)
self.proj = nn.Linear(dim, dim)MLP层实现
self.fc1 = nn.Linear(dim, dim * 4)
self.act = nn.GELU()
self.fc2 = nn.Linear(dim * 4, dim)self.permute = functools.partial(torch.transpose, dim0=1, dim1=2)
if format == ‘bshd’:
self.permute = nn.Identity()def mlp(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.fc2(x)
return xdef reshape_and_permute(self,x, batch_size):
x = x.view(batch_size, -1, self.num_heads, self.head_dim)
return self.permute(x)def forward(self, x_in, attn_mask=None):
batch_size = x_in.size(0)
x = self.norm1(x_in)
qkv = self.qkv(x)为支持PyTorch嵌套张量,采用先分割后重排的策略
而非传统的先重排后分割输入状态的方法
q, k, v = qkv.chunk(3, -1)
q = self.reshape_and_permute(q, batch_size)
k = self.reshape_and_permute(k, batch_size)
v = self.reshape_and_permute(v, batch_size)应用注意力函数
x = self.attn_fn(q, k, v, attn_mask=attn_mask)
输出重排与维度调整
x = self.permute(x).reshape(batch_size, -1, self.dim)
x = self.proj(x)
x = x + x_in
x = x + self.mlp(self.norm2(x))
return x
这种实现为我们提供了一个灵活的实验平台,可以用于测试各种注意力机制的性能表现。
Transformer解码器架构实现
基于前面的可配置Transformer模块,我们构建了一个标准的Transformer解码器架构。这一实现遵循了典型的Transformer架构设计范式,同时保持了足够的灵活性以适应不同的实验需求。
class MyDecoder(nn.Module): def __init__( self, block_fn, num_tokens, dim, num_heads, num_layers, max_seq_len, pad_idx=None ): super().__init__() self.num_heads = num_heads self.pad_idx = pad_idx # 构建token嵌入层,支持填充标记处理 self.embedding = nn.Embedding(num_tokens, dim, padding_idx=pad_idx) # 位置编码嵌入层 self.positional_embedding = nn.Embedding(max_seq_len, dim) # 构建多层Transformer块 self.blocks = nn.ModuleList([ block_fn( dim=dim, num_heads=num_heads ) for _ in range(num_layers)]) # 输出投影层 self.output = nn.Linear(dim, num_tokens)def embed_tokens(self, input_ids, position_ids=None):
token嵌入与位置编码的结合
x = self.embedding(input_ids)
if position_ids is None:
position_ids = torch.arange(input_ids.shape[1],
device=x.device)
x = x + self.positional_embedding(position_ids)
return xdef forward(self, input_ids, position_ids=None, attn_mask=None):
Token嵌入与位置编码的整合
x = self.embed_tokens(input_ids, position_ids)
自动生成填充掩码(如果需要)
if self.pad_idx is not None:
assert attn_mask is None生成布尔类型的填充掩码
attn_mask = (input_ids != self.pad_idx)
attn_mask = attn_mask.view(BATCH_SIZE, 1, 1, -1)
.expand(-1, self.num_heads, -1, -1)依次通过所有Transformer层
for b in self.blocks:
x = b(x, attn_mask)生成最终输出logits
logits = self.output(x)
return logits
变长序列数据集实现
为了系统评估模型性能,还要实现了一个包含变长序列的模拟数据集。为简化实验设置,我们采用了一个固定的序列长度分布。在实际应用场景中,序列长度分布通常由数据本身的特性决定,如文档长度或音频片段持续时间。值得注意的是,序列长度分布会直接影响填充策略导致的计算效率损失。
# 随机数据集实现 class FakeDataset(Dataset): def __len__(self): return 1000000def getitem(self, index):
生成随机长度的序列
length = torch.randint(1, MAX_SEQ_LEN, (1,))
sequence = torch.randint(1, NUM_TOKENS, (length + 1,))准备输入输出对
inputs = sequence[:-1]
targets = sequence[1:]
return inputs, targetsdef pad_sequence(sequence, length, pad_val):
“”“实现序列填充功能”“”
return torch.nn.functional.pad(
sequence,
(0, length - sequence.shape[0]),
value=pad_val
)def collate_with_padding(batch):
“”“批处理数据整理函数,包含填充操作”“”
padded_inputs =
padded_targets =
for b in batch:
padded_inputs.append(pad_sequence(b[0], MAX_SEQ_LEN, PAD_ID))
padded_targets.append(pad_sequence(b[1], MAX_SEQ_LEN, PAD_ID))
padded_inputs = torch.stack(padded_inputs, dim=0)
padded_targets = torch.stack(padded_targets, dim=0)
return {
‘inputs’: padded_inputs,
‘targets’: padded_targets
}
def data_to_device(data, device):
“”“数据传输至指定设备的工具函数”“”
if isinstance(data, dict):
return {
key: data_to_device(val,device)
for key, val in data.items()
}
elif isinstance(data, (list, tuple)):
return type(data)(
data_to_device(val, device) for val in data
)
elif isinstance(data, torch.Tensor):
return data.to(device=device, non_blocking=True)
else:
return data.to(device=device)
这些实现为我们提供了一个完整的实验框架,可以系统地评估不同优化策略的效果。通过这个框架可以精确地量化各种优化方法对计算效率的影响。
训练与评估流程设计
最后还要实现了一个完整的main函数,用于对变长序列数据进行训练和评估。这个实现包含了现代深度学习训练流程的关键要素,包括混合精度训练、梯度计算和性能监控。
def main( block_fn, data_collate_fn=collate_with_padding, pad_idx=None, train=True, compile=False ): # 初始化随机种子,确保实验可重现 torch.random.manual_seed(0) device = torch.device(DEVICE) # 启用高精度矩阵乘法,提升数值稳定性 torch.set_float32_matmul_precision("high")配置数据加载器,优化数据传输效率
data_set = FakeDataset()
data_loader = DataLoader(
data_set,
batch_size=BATCH_SIZE,
collate_fn=data_collate_fn,
num_workers=12, # 并行数据加载
pin_memory=True, # 启用内存钉扎,加速GPU传输
drop_last=True # 确保批次大小一致
)模型实例化与设备配置
model = MyDecoder(
block_fn=block_fn,
num_tokens=NUM_TOKENS,
dim=DIM,
num_heads=NUM_HEADS,
num_layers=DEPTH,
max_seq_len=MAX_SEQ_LEN,
pad_idx=pad_idx
).to(device)启用torch编译优化(如果指定)
if compile:
model = torch.compile(model)损失函数与优化器配置
criterion = torch.nn.CrossEntropyLoss(ignore_index=PAD_ID)
optimizer = torch.optim.SGD(model.parameters())定义训练步骤
def train_step(model, inputs, targets,
position_ids=None, attn_mask=None):使用自动混合精度训练
with torch.amp.autocast(DEVICE, dtype=torch.bfloat16):
outputs = model(inputs, position_ids, attn_mask)
outputs = outputs.view(-1, NUM_TOKENS)
targets = targets.flatten()
loss = criterion(outputs, targets)梯度清零、反向传播与参数更新
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()定义评估步骤
@torch.no_grad()
def eval_step(model, inputs, targets,
position_ids=None, attn_mask=None):
with torch.amp.autocast(DEVICE, dtype=torch.bfloat16):
outputs = model(inputs, position_ids, attn_mask)处理嵌套张量的特殊情况
if outputs.is_nested:
outputs = outputs.data._values
targets = targets.data._values
else:
outputs = outputs.view(-1, NUM_TOKENS)
targets = targets.flatten()
loss = criterion(outputs, targets)
return loss根据模式选择执行函数
if train:
model.train()
step_fn = train_step
else:
model.eval()
step_fn = eval_step性能监控初始化
t0 = time.perf_counter()
summ = 0
count = 0主训练循环
for step, data in enumerate(data_loader):
数据传输至GPU
data = data_to_device(data, device=device)
step_fn(model, data[‘inputs’], data[‘targets’],
position_ids=data.get(‘indices’),
attn_mask=data.get(‘attn_mask’))性能统计计算
batch_time = time.perf_counter() - t0
if step > 20: # 跳过预热阶段
summ += batch_time
count += 1
t0 = time.perf_counter()
if step >= 100: # 限制评估步数
break输出平均步骤时间
print(f’average step time: {summ / count}')
PyTorch SDPA基准测试
在基准测试中,我们使用PyTorch的SDPA(Scaled Dot-Product Attention)机制作为baseline。在NVIDIA H100 GPU上进行测试,环境配置为CUDA 12.4和PyTorch 2.5.1,同时评估了启用和禁用torch.compile的场景。
# 配置SDPA基准测试 from torch.nn.functional import scaled_dot_product_attention as sdpa block_fn = functools.partial(MyAttentionBlock, attn_fn=sdpa) causal_block_fn = functools.partial( MyAttentionBlock, attn_fn=functools.partial(sdpa, is_causal=True) )执行评估与训练测试
for mode in [‘eval’, ‘train’]:
for compile in [False, True]:
block_func = causal_block_fn
if mode == ‘train’ else block_fn
print(f’{mode} with {collate}, ’
f’{“compiled” if compile else “uncompiled”}')
main(block_fn=block_func,
pad_idx=PAD_ID,
train=mode==‘train’,
compile=compile)
基准测试结果显示:
-
评估模式
-
未编译:132毫秒(ms)
-
编译后:130 ms
-
训练模式
-
未编译:342 ms
-
编译后:299 ms
这些基准数据为后续优化方案提供了重要的参考点。通过这些数据可以客观评估不同优化策略的效果。
变长输入序列的优化策略
下面我们就要详细探讨几种针对Transformer模型中变长输入序列处理的优化策略。每种策略都有其独特的优势和应用场景,将通过实验数据来评估它们的效果。
动态填充优化
第一个优化策略关注填充机制本身。不同于传统方法将每个批次的序列填充到固定长度,我们采用了一种动态填充策略:将序列填充到当前批次中最长序列的长度。这种方法可以显著减少不必要的计算开销。以下是具体实现:
def collate_pad_to_longest(batch): padded_inputs = [] padded_targets = [] # 计算当前批次中的最大序列长度 max_length = max([b[0].shape[0] for b in batch]) # 只填充到最大长度,而不是预设的固定长度 for b in batch: padded_inputs.append(pad_sequence(b[0], max_length, PAD_ID)) padded_targets.append(pad_sequence(b[1], max_length, PAD_ID)) # 堆叠处理后的序列 padded_inputs = torch.stack(padded_inputs, dim=0) padded_targets = torch.stack(padded_targets, dim=0) return { 'inputs': padded_inputs, 'targets': padded_targets }执行动态填充优化的性能测试
for mode in [‘eval’, ‘train’]:
for compile in [False, True]:
block_func = causal_block_fn
if mode == ‘train’ else block_fn
print(f’{mode} with {collate}, ’
f’{“compiled” if compile else “uncompiled”}')
main(block_fn=block_func,
data_collate_fn=collate_pad_to_longest,
pad_idx=PAD_ID,
train=mode==‘train’,
compile=compile)
实验结果表明,动态填充策略带来了可观的性能提升:
-
评估模式
-
未编译:129 ms(相比基准提升2.3%)
-
编译后:116 ms(相比基准提升10.8%)
-
训练模式
-
未编译:337 ms(相比基准提升1.5%)
-
编译后:294 ms(相比基准提升1.7%)
PyTorch NestedTensors优化方案
接下来,评估在PyTorch NestedTensors下的应用。这是一个目前处于原型阶段的特性,它允许我们直接处理不同长度的张量,这些张量被称为"jagged"或"ragged"张量。这种方法避免了显式填充的需求,但需要特别注意张量操作的兼容性。
以下代码展示了如何使用NestedTensors处理变长序列:
def nested_tensor_collate(batch): # 创建嵌套张量结构 inputs = torch.nested.as_nested_tensor([b[0] for b in batch], layout=torch.jagged) targets = torch.nested.as_nested_tensor([b[1] for b in batch], layout=torch.jagged) # 生成位置索引 indices = torch.concat([torch.arange(b[0].shape[0]) for b in batch])特别处理:创建与输入具有相同"jagged"形状的索引张量
这是由于NestedTensors对张量操作的限制
xx = torch.empty_like(inputs)
xx.data._values[:] = indicesreturn {
‘inputs’: inputs,
‘targets’: targets,
‘indices’: xx
}执行NestedTensors性能评估
for compile in [False, True]:
print(f’eval with nested tensors, ’
f’{“compiled” if compile else “uncompiled”}')
main(
block_fn=block_fn,
data_collate_fn=nested_tensor_collate,
train=False,
compile=compile
)
NestedTensors方案的性能表现令人瞩目:
-
未编译模式下:131 ms(与基准相当)
-
编译模式下:42 ms(性能提升约3倍)
这个显著的性能提升主要得益于两个因素:
-
避免了填充带来的冗余计算
-
编译优化能够更好地利用NestedTensors的特性进行计算优化
但是需要注意的是,由于NestedTensors仍处于原型阶段,在实际应用中需要谨慎评估其稳定性和兼容性。
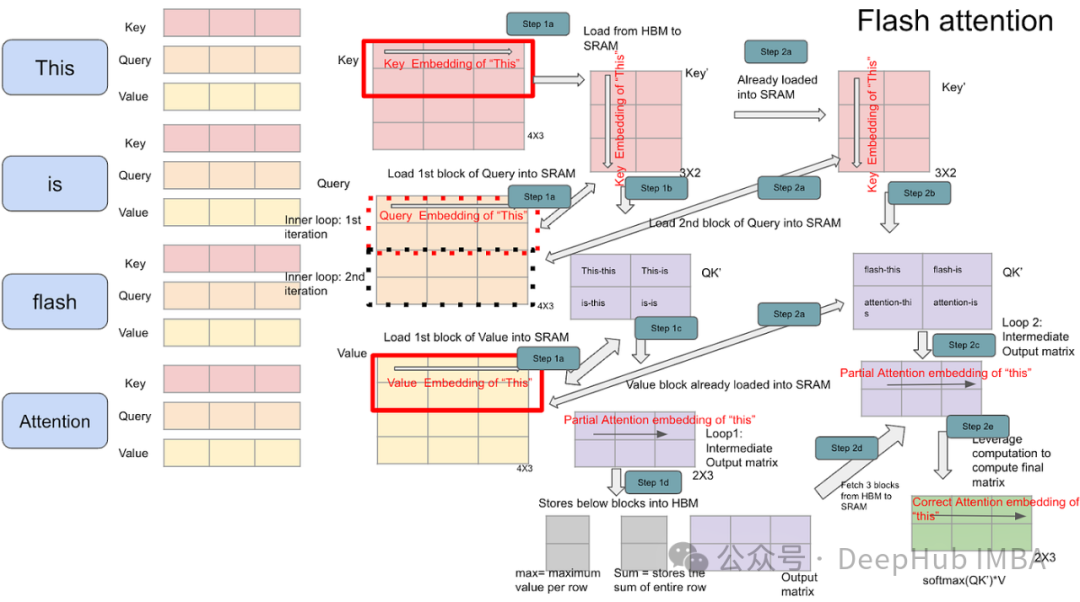
FlashAttention2优化实现
前面的文章我们已经探讨了FlashAttention对Transformer模型性能的影响。本节将重点介绍flash-attn 2.7.0版本中的flash_attn_varlen_func,这是一个专门为处理可变长度输入设计的API。这个优化方案的核心思想是将批次中的所有序列连接成一个连续序列,同时使用一个特殊的索引张量(cu_seqlens)来追踪各个原始序列的边界位置。
以下是这种方法的详细实现:
def collate_concat(batch): # 将所有序列连接为单一序列,并添加batch维度 inputs = torch.concat([b[0] for b in batch]).unsqueeze(0) targets = torch.concat([b[1] for b in batch]).unsqueeze(0) # 生成位置索引 indices = torch.concat([torch.arange(b[0].shape[0]) for b in batch]) # 计算累积序列长度,用于定位序列边界 seqlens = torch.tensor([b[0].shape[0] for b in batch]) seqlens = torch.cumsum(seqlens, dim=0, dtype=torch.int32) # 添加起始位置0,形成完整的区间索引 cu_seqlens = torch.nn.functional.pad(seqlens, (1, 0))return {
‘inputs’: inputs,
‘targets’: targets,
‘indices’: indices,
‘attn_mask’: cu_seqlens
}配置FlashAttention变长序列处理函数
from flash_attn import flash_attn_varlen_func
标准版本:用于评估模式
fa_varlen = lambda q, k, v, attn_mask: flash_attn_varlen_func(
q.squeeze(0),
k.squeeze(0),
v.squeeze(0),
cu_seqlens_q=attn_mask,
cu_seqlens_k=attn_mask,
max_seqlen_q=MAX_SEQ_LEN,
max_seqlen_k=MAX_SEQ_LEN
).unsqueeze(0)因果版本:用于训练模式,确保注意力的因果性
fa_varlen_causal = lambda q, k, v, attn_mask: flash_attn_varlen_func(
q.squeeze(0),
k.squeeze(0),
v.squeeze(0),
cu_seqlens_q=attn_mask,
cu_seqlens_k=attn_mask,
max_seqlen_q=MAX_SEQ_LEN,
max_seqlen_k=MAX_SEQ_LEN,
causal=True
).unsqueeze(0)配置使用FlashAttention的Transformer块
block_fn = functools.partial(MyAttentionBlock,
attn_fn=fa_varlen,
format=‘bshd’)
causal_block_fn = functools.partial(MyAttentionBlock,
attn_fn=fa_varlen_causal,
format=‘bshd’)执行性能评估
print(‘flash-attn eval’)
main(
block_fn=block_fn,
data_collate_fn=collate_concat,
train=False
)
print(‘flash-attn train’)
main(
block_fn=causal_block_fn,
data_collate_fn=collate_concat,
train=True,
)
FlashAttention2的性能提升非常显著:
-
评估模式:51 ms(比基准快2.6倍)
-
训练模式:160 ms(比基准快2.1倍)
这种显著的性能提升主要源于以下技术创新:
-
高效的内存访问模式:通过分块计算和重排访问模式,减少了内存带宽需求
-
序列边界的精确追踪:使用cu_seqlens避免了填充带来的计算浪费
-
优化的CUDA核函数实现:专门针对变长序列场景进行了优化
目前flash_attn_varlen_func还不支持torch.compile。这是因为其实现包含了复杂的CUDA核函数,这些函数目前还无法被PyTorch的编译器正确处理。在实际应用中,即使没有编译优化,其性能仍然远超基准实现。
XFormers内存高效注意力机制的实现
前面的文章我们也介绍了xFormers (0.0.28)中的memory_efficient_attention操作符。下面我们将重点探讨BlockDiagonalMask的应用,这是一个专门为处理任意长度输入序列设计的掩码机制。这种方法的独特之处在于它能够在保持高计算效率的同时精确处理序列边界。
让我们详细分析这个实现:
from xformers.ops import fmha from xformers.ops import memory_efficient_attention as meadef collate_xformer(batch):
序列连接与维度处理
inputs = torch.concat([b[0] for b in batch]).unsqueeze(0)
targets = torch.concat([b[1] for b in batch]).unsqueeze(0)
indices = torch.concat([torch.arange(b[0].shape[0]) for b in batch])提取每个序列的长度信息
seqlens = [b[0].shape[0] for b in batch]
设置批次大小,用于掩码生成
batch_sizes = [1 for b in batch]
创建块对角掩码,处理序列边界
block_diag = fmha.BlockDiagonalMask.from_seqlens(seqlens, device=‘cpu’)
block_diag._batch_sizes = batch_sizesreturn {
‘inputs’: inputs,
‘targets’: targets,
‘indices’: indices,
‘attn_mask’: block_diag
}配置评估模式的注意力计算
mea_eval = lambda q, k, v, attn_mask: mea(
q,k,v, attn_bias=attn_mask)配置训练模式的因果注意力计算
mea_train = lambda q, k, v, attn_mask: mea(
q,k,v, attn_bias=attn_mask.make_causal())构建评估模式的Transformer块配置
block_fn = functools.partial(MyAttentionBlock,
attn_fn=mea_eval,
format=‘bshd’)构建训练模式的Transformer块配置
causal_block_fn = functools.partial(MyAttentionBlock,
attn_fn=mea_train,
format=‘bshd’)执行性能评估测试
print(f’xFormer Attention ‘)
for compile in [False, True]:
print(f’eval with xFormer Attention, ’
f’{“compiled” if compile else “uncompiled”}')
main(block_fn=block_fn,
train=False,
data_collate_fn=collate_xformer,
compile=compile)
print(f’train with xFormer Attention’)
main(block_fn=causal_block_fn,
train=True,
data_collate_fn=collate_xformer)
XFormers的性能表现令人印象深刻:
-
评估模式(未编译):50 ms
-
评估模式(已编译):42 ms
-
训练模式:159 ms
这些性能数据反映了XFormers优化策略的几个关键优势:
高效的内存管理:
-
BlockDiagonalMask提供了一种内存友好的方式来处理序列边界
-
避免了传统填充方法带来的内存浪费
优化的计算模式:
-
通过块对角矩阵的形式组织注意力计算
-
有效减少了不必要的计算操作
灵活的掩码机制:
-
make_causal方法可以方便地转换为因果注意力模式
-
支持动态序列长度而不损失性能
编译优化兼容性:
-
在评估模式下,能够充分利用torch.compile带来的优化
-
虽然训练模式下的编译支持仍有限制,但基础性能已经相当优秀
但是在实际应用中还需要注意以下几点:
-
训练模式下的编译支持目前仍有限制
-
性能提升的程度可能会随具体的硬件环境和模型配置而变化
-
内存使用模式与标准实现有所不同,可能需要相应调整内存预算
优化结果综合分析
通过上述一系列实验,我们获得了不同优化策略的性能数据。让我们通过一张对比图来直观地理解这些结果:

不同优化方法的步骤时间对比(数值越低表示性能越好),xFormer的memory_efficient_attention表现最为出色,在评估时实现了约3倍的性能提升,在训练时获得了约2倍的加速。这里需要特别说明的是,这些性能数据不应被视为普适性结论。在实际应用中,不同注意力计算方法的性能表现会因具体的模型架构、硬件配置和应用场景而呈现显著差异。
HuggingFace模型的变长输入优化
相比从零开始构建模型,现代机器学习开发更多地依赖于预训练模型的微调。虽然前文描述的优化技术可以在不改变模型权重和行为的前提下集成到现有模型中,但如何高效实施这种集成仍然是一个重要问题。在本节中,我们将探讨如何在HuggingFace生态系统中实现这些优化。
GPT2LMHeadModel实验设计
为了演示优化过程,我们选择了GPT2LMHeadModel作为实验对象。首先要调整数据集和数据处理流程以适配HuggingFace的标准接口:
from transformers import GPT2Config, GPT2LMHeadModelclass HuggingFaceFakeDataset(Dataset):
“”“用于HuggingFace模型实验的模拟数据集”“”
def len(self):
return 1000000def getitem(self, index):
生成随机长度序列
length = torch.randint(1, MAX_SEQ_LEN, (1,))
input_ids = torch.randint(1, NUM_TOKENS, (length,))创建训练标签,将第一个token标记为填充
labels = input_ids.clone()
labels[0] = PAD_ID
return {
‘input_ids’: input_ids,
‘labels’: labels
}def hf_collate_with_padding(batch):
“”“HuggingFace模型的批处理数据整理函数”“”
padded_inputs =
padded_labels =
for b in batch:
input_ids = b[‘input_ids’]
labels = b[‘labels’]执行序列填充
padded_inputs.append(pad_sequence(input_ids, MAX_SEQ_LEN, PAD_ID))
padded_labels.append(pad_sequence(labels, MAX_SEQ_LEN, PAD_ID))转换为批次张量
padded_inputs = torch.stack(padded_inputs, dim=0)
padded_labels = torch.stack(padded_labels, dim=0)
return {
‘input_ids’: padded_inputs,
‘labels’: padded_labels,
‘attention_mask’: (padded_inputs != PAD_ID) # 生成注意力掩码
}
在这个实现中,特别注意以下几个方面:
-
数据格式的一致性:确保生成的数据符合HuggingFace的预期格式
-
填充处理:实现了高效的填充策略,同时保持数据的语义完整性
-
注意力掩码:自动生成适当的注意力掩码,用于处理填充token
HuggingFace模型训练流程的实现
为了系统评估优化效果,还需要实现了一个完整的训练流程。这个实现不仅包含了标准的训练循环,还集成了各种现代深度学习的优化技术:
def hf_main( config, collate_fn=hf_collate_with_padding, compile=False ): # 初始化环境配置 torch.random.manual_seed(0) device = torch.device(DEVICE) # 启用高精度矩阵计算,提升数值稳定性 torch.set_float32_matmul_precision("high")配置数据加载器
data_set = HuggingFaceFakeDataset()
data_loader = DataLoader(
data_set,
batch_size=BATCH_SIZE,
collate_fn=collate_fn,
num_workers=12 if DEVICE == “CUDA” else 0, # 根据设备类型调整并行加载
pin_memory=True, # 启用内存钉扎加速数据传输
drop_last=True # 保持批次大小一致
)模型初始化和设备迁移
model = GPT2LMHeadModel(config).to(device)
条件编译优化
if compile:
model = torch.compile(model)配置训练组件
criterion = torch.nn.CrossEntropyLoss(ignore_index=PAD_ID)
optimizer = torch.optim.SGD(model.parameters())model.train() # 设置训练模式
性能监控初始化
t0 = time.perf_counter()
summ = 0
count = 0主训练循环
for step, data in enumerate(data_loader):
数据迁移到目标设备
data = data_to_device(data, device=device)
input_ids = data[‘input_ids’]
labels = data[‘labels’]
position_ids = data.get(‘position_ids’)
attn_mask = data.get(‘attention_mask’)使用混合精度训练
with torch.amp.autocast(DEVICE, dtype=torch.bfloat16):
outputs = model(input_ids=input_ids,
position_ids=position_ids,
attention_mask=attn_mask)处理序列偏移,确保正确的预测目标
logits = outputs.logits[…, :-1, :].contiguous()
labels = labels[…, 1:].contiguous()计算损失
loss = criterion(logits.view(-1, NUM_TOKENS), labels.flatten())
梯度更新
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()记录和更新性能统计
batch_time = time.perf_counter() - t0
if step > 20: # 跳过初始预热步骤
summ += batch_time
count += 1
t0 = time.perf_counter()
if step >= 100: # 限制评估步数
break输出平均步骤时间
print(f’average step time: {summ / count}')
这个实现中包含了几个关键的技术考虑:
-
混合精度训练:
-
使用torch.amp.autocast实现自动混合精度
-
选择bfloat16数据类型,在保持数值稳定性的同时提升计算效率
-
内存优化:
-
使用pin_memory和non_blocking数据传输
-
通过set_to_none=True优化梯度清零操作
-
性能监控:
-
实现了精确的性能统计
-
考虑了预热阶段的影响
-
数据处理:
-
处理序列的因果关系,确保预测目标的正确性
-
优化了张量操作的内存布局(通过contiguous()调用)
这种实现为我们提供了一个可靠的基准测试平台,使我们能够准确评估不同优化策略的效果。
基于SDPA的基准测试实现
使用标准SDPA(Scaled Dot-Product Attention)的基准测试。这为后续的优化策略提供了一个参考点:
config = GPT2Config( n_layer=DEPTH, # 设置模型深度 n_embd=DIM, # 嵌入维度 n_head=NUM_HEADS, # 注意力头数量 vocab_size=NUM_TOKENS, # 词表大小 )执行不同配置的基准测试
for compile in [False, True]:
print(f"HF GPT2 train with SDPA, compile={compile}")
hf_main(config=config, compile=compile)
基准测试的结果显示,在不同配置下的性能表现存在显著差异:
-
未启用编译优化时:815毫秒
-
启用编译优化后:440毫秒
这个基准测试揭示了编译优化能带来接近1.85倍的性能提升,这主要得益于PyTorch的动态编译技术对计算图的优化。
FlashAttention2的集成实现
接下来需要通过配置HuggingFace的内置支持来启用FlashAttention2。这种方法的优势在于实现简单,只需要修改配置参数即可:
flash_config = GPT2Config( n_layer=DEPTH, n_embd=DIM, n_head=NUM_HEADS, vocab_size=NUM_TOKENS, attn_implementation='flash_attention_2' # 启用FlashAttention2 )
print(f"HF GPT2 train with flash")
hf_main(config=flash_config)
这个简单的配置修改产生了显著的性能提升:
-
步骤时间降至620毫秒
-
相比未优化版本提升了约31.9%的性能
这种改进的实现原理是:HuggingFace框架会在内部自动将填充后的输入数据进行"解填充"(unpadding)操作,然后将处理后的数据传递给优化过的flash_attn_varlen_func函数。这个过程虽然引入了一些数据预处理开销,但整体性能仍然获得了显著提升。
FlashAttention2的无填充优化
虽然上述实现已经带来了可观的性能提升,但在数据处理流程中仍存在一些冗余操作:先对序列进行填充,然后又在内部进行解填充。为了进一步优化性能,可以直接使用未填充的输入数据。
最近的HuggingFace更新增加了对连接序列(未填充)输入的支持,但这个功能目前仅限于特定模型。要在GPT2模型中启用这个功能,需要对modeling_gpt2.py文件进行少量修改。以下是完整的补丁内容:
@@ -370,0 +371 @@
+ position_ids = None
@@ -444,0 +446 @@
+ position_ids=position_ids
@@ -611,0 +614 @@
+ position_ids=None
@@ -621,0 +625 @@
+ position_ids=position_ids
@@ -1140,0 +1145 @@
+ position_ids=position_ids
这些修改的主要目的是在attention计算过程中正确传递位置编码信息,确保模型能够准确处理未填充的序列数据。
在了解了必要的修改后,我们可以实现一个专门用于处理未填充序列的数据处理函数:
def collate_flatten(batch): # 直接连接所有序列,避免填充操作 input_ids = torch.concat([b['input_ids'] for b in batch]).unsqueeze(0) labels = torch.concat([b['labels'] for b in batch]).unsqueeze(0) # 为每个序列生成对应的位置编码 position_ids = [torch.arange(b['input_ids'].shape[0]) for b in batch] position_ids = torch.concat(position_ids)return {
‘input_ids’: input_ids,
‘labels’: labels,
‘position_ids’: position_ids
}使用无填充配置进行性能测试
print(f"HF GPT2 train with flash, no padding")
hf_main(config=flash_config, collate_fn=collate_flatten)
这种优化方案的性能表现令人瞩目:
-
步骤时间降至323毫秒
-
与使用填充数据的FlashAttention2相比,性能提升了约90%
-
相比原始基准测试,性能提升了约2.5倍
综合性能分析
通过一张图表来直观地比较不同优化策略的效果:

不同优化方法的步骤时间对比(数值越低表示性能越好)通过系统性的优化,我们实现了显著的性能提升:
-
相比未编译的基准版本:性能提升了约2.5倍
-
相比启用编译的版本:性能提升了约36%
这些优化成果充分展示了HuggingFace API的灵活性,它使我们能够轻松集成高效的注意力计算核心,显著提升模型在处理变长序列时的训练性能。
总结
随着AI模型在复杂度和应用范围上的持续扩展,性能优化变得越来越重要。本文着重探讨了注意力层的优化策略,并提供了一系列实用的工具和技术来提升Transformer模型的性能。主要的技术贡献包括:
-
数据处理优化:
-
提出了动态填充和无填充策略
-
优化了序列连接和位置编码的处理方式
-
计算效率提升:
-
利用FlashAttention2实现高效的注意力计算
-
通过编译优化提升执行效率
-
框架集成:
-
展示了如何在HuggingFace生态系统中实现这些优化
-
提供了具体的代码修改指南
这些优化策略不仅提供了显著的性能提升,还保持了实现的简洁性和可维护性。对于希望优化自己模型性能的开发者来说,这些方法提供了实用的参考方案。
为了深入了解更多AI模型优化相关内容,建议查阅本系列的第一篇文章以及其他相关技术文档。随着深度学习技术的不断发展,我们期待看到更多创新的优化方案出现。
