从输入网址到网页显示,一本书带你探索网络连接的全过程,图文并茂,轻松易懂!
原文标题:豆瓣9.1,畅销15万册,这本书被上千人评为计算机入门科普经典神作!
原文作者:图灵编辑部
冷月清谈:
首先,浏览器会解析URL,提取其中的域名、路径等信息,确定访问目标。然后,根据HTTP协议,浏览器生成请求消息,其中包含访问方法(GET、POST等)和URI。服务器收到请求后,进行相应处理,并将结果以响应消息的形式返回给浏览器。
书中以访问网页为例,详细讲解了使用GET方法获取网页数据以及处理网页中图片等资源的过程。此外,还介绍了其他HTTP方法,例如用于提交表单数据的POST方法,以及PUT和DELETE方法。
通过阅读本书,你将深入理解网络连接的本质,以及实际网络设备和软件的工作原理,从而更加熟练地运用网络技术。
怜星夜思:
2、书中提到根据服务器设置的不同,省略文件名时访问的默认文件名也不同。大家平时访问网站时,有没有遇到过一些特殊的默认文件名?
3、书中以GET和POST方法为例讲解了HTTP协议。除了这两个方法,大家觉得还有哪些方法比较重要,或者在实际应用中比较常见?
原文内容

从在浏览器中输入网址,到屏幕上显示出相关网页的内容,这个只有几秒钟的过程,却需要很多硬件和软件在各自的岗位上相互配合完成的一系列工作,你知道这个过程中究竟发生了什么么?
《网络是怎样连接的》这本书以探索之旅的形式,从在浏览器中输入网址开始,一路追踪了到显示出网页内容为止的整个过程,以图配文,讲解了网络的全貌,并重点介绍了实际的网络设备和软件是如何工作的。
目的是帮助读者理解网络的本质意义,理解实际的设备和软件,进而熟练运用网络技术。同时,专设了“网络术语其实很简单”专栏,以对话的形式介绍了一些网络术语的词源,颇为生动有趣。
号称“蹲马桶就能看懂的网络基础知识”。也被无数的读者喜欢并学习。
书名:《网络是怎样连接的》
作者:[日]户根勤
译者:周自恒
下面我们就以探索之旅的形式,探索这一系列工作中的其中一个环节——浏览器是怎么生成消息的。
在开始探索之旅之前,我们准备了一些和本文内容有关的小问题,请大家先试试看。这些题目是否答得出来并不影响接下来的探索之旅,因此大家可以放轻松。
下列说法是正确的(√)还是错误的(×)?
1. http://www.nikkeibp.co.jp/ 中的www 代表World Wide Web 协议(对通信操作规则所作的定义)。
2. 个人也可以申请注册互联网中的域名。
3. 浏览器等网络应用程序实际上并不具备网络控制功能。
答案:
1. ×。http://www.nikkeibp.co.jp/ 中的www 只是Web 服务器上的一种命名。而且,World Wide Web 也不是一个协议的名字,而是Web 的提出者最早开发的浏览器兼HTML 编辑器的名字。
2. √。如果是 “.com” “.net” “.org” “.jp” (除 “co.jp” “ne.jp” 等“xx.jp”格式的域名外)等没有对注册对象范围进行限制的域名,任何个人都可以申请注册。此外,也有一种“.name”域名是专门为个人申请者准备的。
3. √。应用程序并不是自己去控制网络,而是委托操作系统来控制网络。
探索之旅从输入网址开始
我们的探索之旅从在浏览器中输入网址开始,在介绍浏览器的工作方式之前,让我们先来介绍一下网址。网址,准确来说应该叫URL,如果我说它就是以http:// 开头的那一串东西,恐怕大家一下子就明白了,但实际上除了“http:”,网址还可以以其他一些文字开头,例如“ftp:”“ file:”“mailto:” 等。
之所以有各种各样的URL,是因为尽管我们通常是使用浏览器来访问Web服务器的,但实际上浏览器并不只有这一个功能,它也可以用来在FTP服务器上下载和上传文件,同时也具备电子邮件客户端的功能。可以说,浏览器是一个具备多种客户端功能的综合性客户端软件,因此它需要一些东西来判断应该使用其中哪种功能来访问相应的数据,而各种不同的URL 就是用来干这个的,比如访问Web 服务器时用“http:”,而访问FTP服务器时用“ftp:”。
图1.1 列举了现在互联网中常见的几种URL,根据访问目标的不同,URL 的写法也会不同。例如在访问Web 服务器和FTP 服务器时,URL 中会包含服务器的域名和要访问的文件的路径名等,而发邮件的URL 则包含收件人的邮件地址。此外,根据需要,URL 中还会包含用户名、密码、服务器端口号等信息。

尽管URL 有各种不同的写法,但它们有一个共同点,那就是URL 开头的文字,即“http:”“ftp:”“file:”“mailto:”这部分文字都表示浏览器应当使用的访问方法。比如当访问Web 服务器时应该使用HTTP协议,而访问FTP 服务器时则应该使用FTP 协议。因此,我们可以把这部分理解为访问时使用的协议类型。尽管后面部分的写法各不相同,但开头部分的内容决定了后面部分的写法,因此并不会造成混乱。
浏览器先要解析URL
浏览器要做的第一步工作就是对URL 进行解析,从而生成发送给Web服务器的请求消息。刚才我们已经讲过,URL 的格式会随着协议的不同而不同,因此下面我们以访问Web 服务器的情况为例来进行讲解。
根据HTTP 的规格,URL 包含图1.2(a)中的这几种元素。当对URL进行解析时,首先需要按照图1.2(a)的格式将其中的各个元素拆分出来,例如图1.2(b)中的URL 会拆分成图1.2(c)的样子。然后,通过拆分出来的这些元素,我们就能够明白URL 代表的含义。例如,我们来看拆分结果图1.2(c),其中包含Web 服务器名称www.lab.glasscom.com,以及文件的路径名/dir1/file1.html,因此我们就能够明白,图1.2(b)中的URL 表示要访问www.lab.glasscom.com 这个Web 服务器上路径名为/dir/file1.html 的文件,也就是位于/dir/ 目录下的file1.html 这个文件(图1.3)。
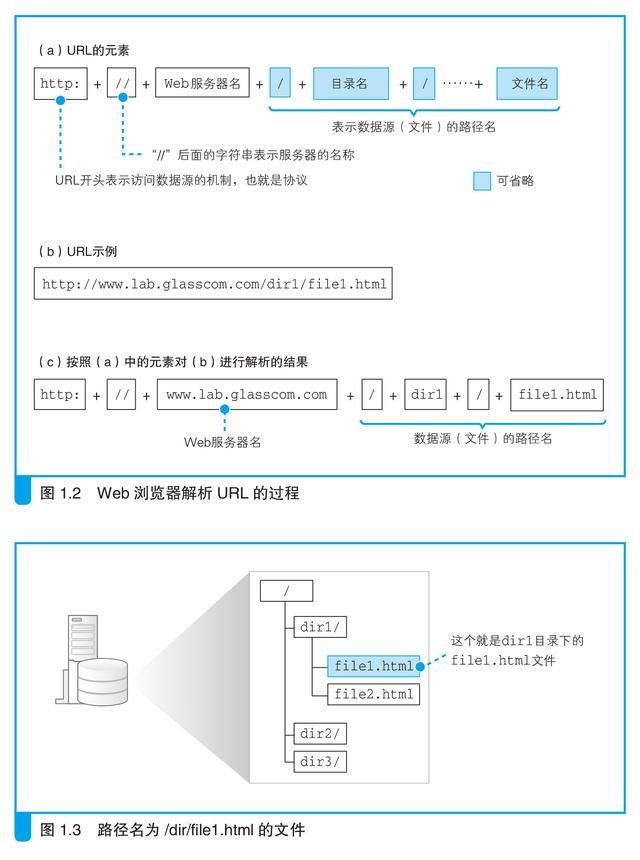
省略文件名的情况
图1.2(b)是一个以“http:”开头的典型URL,但有时候我们也会见到一些不太一样的URL,例如下面这个URL 是以“/”来结尾的。
(a)http://www.lab.glasscom.com/dir/
我们可以这样理解,以“/”结尾代表/dir/ 后面本来应该有的文件名被省略了。根据URL 的规则,文件名可以像前面这样省略。
不过,没有文件名,服务器怎么知道要访问哪个文件呢?其实,我们会在服务器上事先设置好文件名省略时要访问的默认文件名。这个设置根据服务器不同而不同,大多数情况下是index.html 或者default.htm 之类的文件名。因此,像前面这样省略文件名时,服务器就会访问/dir/index.html或者/dir/default.htm。
还有一些URL 是像下面这样只有Web 服务器的域名的,这也是一种省略了文件名的形式。
(b)http://www.lab.glasscom.com/
这个URL 也是以“/”结尾的,也就是说它表示访问一个名叫“/”的目录。而且,由于省略了文件名,所以结果就是访问/index.html 或者/default.htm 这样的文件了。那么,下面这个URL 又是什么意思呢?
(c)http://www.lab.glasscom.com
这次连结尾的“/”都省略了。像这样连目录名都省略时,真不知道到底在请求哪个文件了,实在有些过分。不过,这种写法也是允许的。当没有路径名时,就代表访问根目录下事先设置的默认文件,也就是/index.html 或者/default.htm 这些文件,这样就不会发生混乱了。不过,下面这个例子就更诡异了。
(d)http://www.lab.glasscom.com/whatisthis
前面这个例子中,由于末尾没有“/”,所以whatisthis 应该理解为文件名才对。但实际上,很多人并没有正确理解省略文件名的规则,经常会把目录末尾的“/”也给省略了。因此,或许我们不应该总是将whatisthis 作为文件名来处理。一般来说,这种情况会按照下面的惯例进行处理:如果Web 服务器上存在名为whatisthis 的文件,则将whatisthis 作为文件名来处理;如果存在名为whatisthis 的目录,则将whatisthis 作为目录名来处理。
浏览器的第一步工作就是对URL 进行解析。
HTTP 的基本思路
解析完URL 之后,我们就知道应该要访问的目标在哪里了。接下来,浏览器会使用HTTP 协议来访问Web 服务器,不过在介绍这一环节之前,我们先来讲一讲HTTP 协议到底是怎么回事。

HTTP 协议定义了客户端和服务器之间交互的消息内容和步骤,其基本思路非常简单。首先,客户端会向服务器发送请求消息(图1.4)。请求消息中包含的内容是“对什么”和“进行怎样的操作”两个部分。其中相当于“对什么”的部分称为URI。
一般来说,URI 的内容是一个存放网页数据的文件名或者是一个CGI 程序的文件名,例如 “/dir1/file1.html”“/dir1/program1.cgi”等。不过,URI 不仅限于此,也可以直接使用 “http:”开头的URL 来作为URI。换句话说就是,这里可以写各种访问目标,而这些访问目标统称为URI。
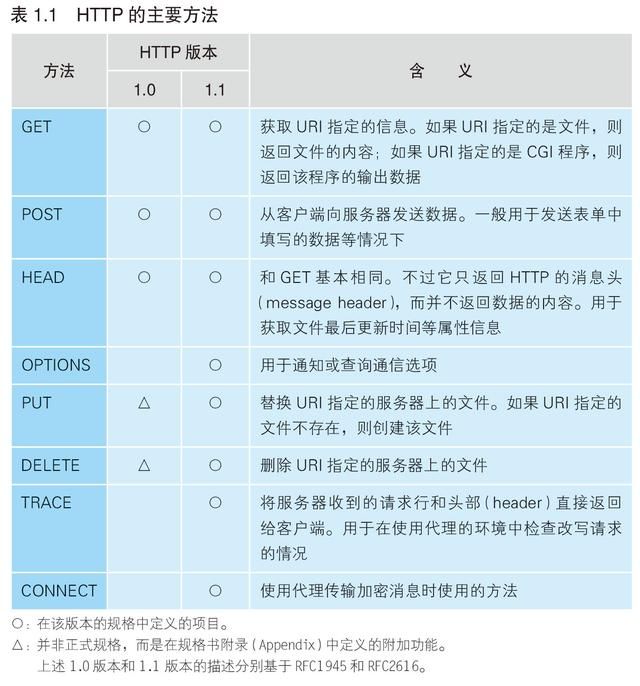
相当于接下来“进行怎样的操作”的部分称为方法。方法表示需要让Web 服务器完成怎样的工作,其中典型的例子包括读取URI 表示的数据、将客户端输入的数据发送给URI 表示的程序等。表1.1 列举了主要的方法,通过这张表大家应该能够理解通过方法可以执行怎样的操作。
除了图1.4 中的内容之外,HTTP 消息中还有一些用来表示附加信息的头字段。客户端向Web 服务器发送数据时,会先发送头字段,然后再发送数据。不过,头字段属于可有可无的附加信息,因此我们暂时跳过。
收到请求消息之后,Web 服务器会对其中的内容进行解析,通过URI和方法来判断“对什么”“进行怎样的操作”,并根据这些要求来完成自己的工作,然后将结果存放在响应消息中。在响应消息的开头有一个状态码,它用来表示操作的执行结果是成功还是发生了错误。当我们访问Web 服务器时,遇到找不到的文件就会显示出404 Not Found 的错误信息,其实这就是状态码。状态码后面就是头字段和网页数据。响应消息会被发送回客户端,客户端收到之后,浏览器会从消息中读出所需的数据并显示在屏幕上。到这里,HTTP 的整个工作就完成了。
现在大家应该已经了解了HTTP 的全貌,下面我们再补充一些关于HTTP 方法的知识。表1.1 列出的方法中,最常用的一个就是GET 方法了。一般当我们访问Web 服务器获取网页数据时,使用的就是GET 方法。所谓一般的访问过程大概就是这样的:首先,在请求消息中写上GET 方法,然后在URI 中写上存放网页数据的文件名“/dir1/file1.html”,这就表示我们需要获取/dir1/file1.html 文件中的数据。当Web 服务器收到消息后,会打开/dir1/file1.html 文件并读取出里面的数据,然后将读出的数据存放到响应消息中,并返回给客户端。最后,客户端浏览器会收到这些数据并显示在屏幕上。
还有一个经常使用的方法就是POST。我们在表单中填写数据并将其发送给Web 服务器时就会使用这个方法。当我们在网上商城填写收货地址和姓名,或者是在网上填写问卷时,都会遇到带有输入框的网页,而这些可以输入信息的部分就是表单。
使用POST 方法时,URI 会指向Web 服务器中运行的一个应用程序的文件名,典型的例子包括“index.cgi”“index.php”等。然后,在请求消息中,除了方法和URI 之外,还要加上传递给应用程序和脚本的数据。这里的数据也就是用户在输入框里填写的信息。
当服务器收到消息后,Web 服务器会将请求消息中的数据发送给URI 指定的应用程序。最后,Web 服务器从应用程序接收输出的结果,会将它存放到响应消息中并返回给客户端。
前面两个方法属于HTTP 的典型用法,除此之外的其他方法在互联网上几乎见不到使用的例子。因此,只要理解了这两个方法,就能够应付大部分情况了,但如果可以,还是推荐大家看一看表1.1 中所有方法的说明,思考一下它们的含义,以便理解HTTP 协议具备的所有功能。
如果只有GET 和POST 方法,我们就只能从Web 服务器中获取网页数据,以及将网页输入框中的信息发送给Web 服务器,而有了PUT 和DELETE 方法,就能够从客户端修改或者删除Web 服务器上的文件。有了这些功能,我们甚至可以将Web 服务器当成文件服务器来用。当然,出于安全上的原因,或者是支持GET 和POST 之外的方法的客户端没有广泛普及之类的原因,一般我们并不会碰到这样的用法,但大家应该能够看出,HTTP 协议其实蕴藏着很多的可能性。
生成HTTP 请求消息
理解了HTTP 的基本知识之后,让我们回到对浏览器本身的探索中来。
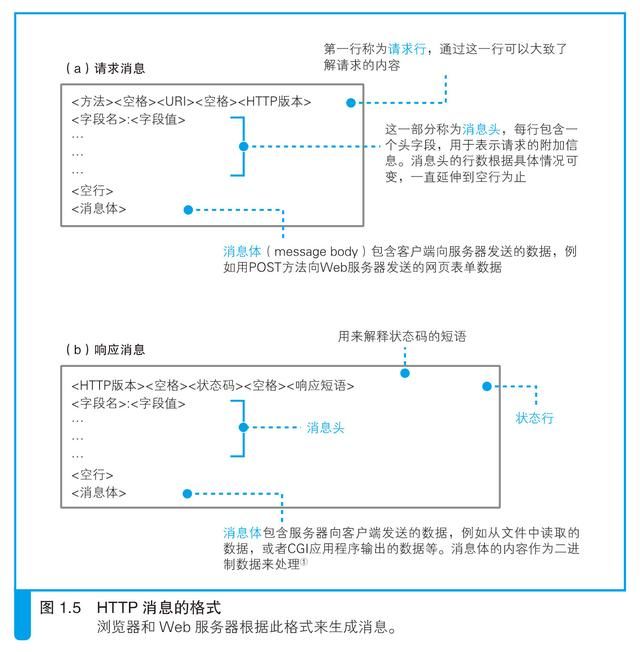
对URL 进行解析之后,浏览器确定了Web 服务器和文件名,接下来就是根据这些信息来生成HTTP 请求消息了。实际上,HTTP 消息在格式上是有严格规定的,因此浏览器会按照规定的格式来生成请求消息(图1.5)。
首先,请求消息的第一行称为请求行。这里的重点是最开头的方法,方法可以告诉Web 服务器它应该进行怎样的操作。不过这里必须先解决一个问题,那就是方法有很多种,我们必须先判断应该选用其中的哪一种。
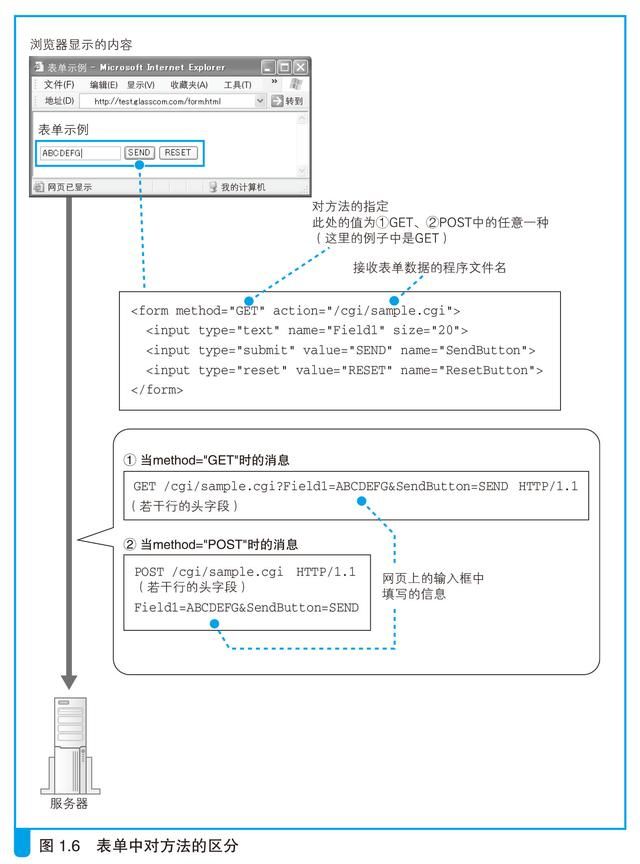
解决这个问题的关键在于浏览器的工作状态。这次探索之旅是从在浏览器顶部的地址栏中输入网址开始的,但浏览器并非只有在这一种场景下才会向Web 服务器发送请求消息。比如点击网页中的超级链接,或者在表单中填写信息后点击“提交”按钮,这些场景都会触发浏览器的工作,而选用哪种方法也是根据场景来确定的。
我们的场景是在地址栏中输入网址并显示网页,因此这里应该使用GET方法。点击超级链接的场景中也是使用GET 方法。如果是表单,在HTML源代码中会在表单的属性中指定使用哪种方法来发送请求,可能是GET 也可能是POST(图1.6)。
写好方法之后,加一个空格,然后写URI。URI 部分的格式如下,一般是文件和程序的路径名。
/< 目录名>/…/< 文件名>
前面已经讲过,路径名一般来说已经包含在URL 中了,因此只要从URL 中提取出来原封不动地写上去就好了。
第一行的末尾需要写上HTTP 的版本号,这是为了表示该消息是基于哪个版本的HTTP 规格编写的。到此为止,第一行就结束了。
第二行开始为消息头。尽管通过第一行我们就可以大致理解请求的内容,但有些情况下还需要一些额外的详细信息,而消息头的功能就是用来存放这些信息。消息头的规格中定义了很多项目,如日期、客户端支持的数据类型、语言、压缩格式、客户端和服务器的软件名称和版本、数据有效期和最后更新时间等。这些项目表示的都是非常细节的信息,因此要想准确理解这些信息的意思,就需要对HTTP 协议有非常深入的了解。表1.2中列举了主要的头字段供大家参考,但不必全部弄明白。消息头中的内容随着浏览器类型、版本号、设置等的不同而不同,大多数情况下消息头的长度为几行到十几行不等。
写完消息头之后,还需要添加一个完全没有内容的空行,然后写上需要发送的数据。这一部分称为消息体,也就是消息的主体。不过,在使用GET 方法的情况下,仅凭方法和URI,Web 服务器就能够判断需要进行怎样的操作,因此消息体中不需要填写任何数据。消息体结束之后,整个消息也就结束了。

当使用POST 方法时,需要将表单中填写的信息写在消息体中。到此为止,请求消息的生成操作就全部完成了。
发送请求后会收到响应
当我们将上述请求消息发送出去之后,Web 服务器会返回响应消息。关于响应消息我们在这里先粗略地了解一下。响应消息的格式以及基本思路和请求消息是相同的(图1.5(b)),差别只在第一行上。在响应消息中,第一行的内容为状态码和响应短语,用来表示请求的执行结果是成功还是出错。状态码和响应短语表示的内容一致,但它们的用途不同。状态码是一个数字,它主要用来向程序告知执行的结果(表1.3);相对地,响应短语则是一段文字,用来向人们告知执行的结果。

返回响应消息之后,浏览器会将数据提取出来并显示在屏幕上,我们就能够看到网页的样子了。如果网页的内容只有文字,那么到这里就全部处理完毕了,但如果网页中还包括图片等资源,则还有下文。
当网页中包含图片时,会在网页中的相应位置嵌入表示图片文件的标签的控制信息。浏览器会在显示文字时搜索相应的标签,当遇到图片相关的标签时,会在屏幕上留出用来显示图片的空间,然后再次访问Web 服务器,按照标签中指定的文件名向Web 服务器请求获取相应的图片并显示在预留的空间中。这个步骤和获取网页文件时一样,只要在URI 部分写上图片的文件名并生成和发送请求消息就可以了。
由于每条请求消息中只能写1 个URI,所以每次只能获取1 个文件,如果需要获取多个文件,必须对每个文件单独发送1 条请求。比如1 个网页中包含3 张图片,那么获取网页加上获取图片,一共需要向Web 服务器发送4 条请求。
判断所需的文件,然后获取这些文件并显示在屏幕上,这一系列工作的整体指挥也是浏览器的任务之一,而Web 服务器却毫不知情。Web 服务器完全不关心这4 条请求获取的文件到底是1 个网页上的还是不同网页上的,它的任务就是对每一条单独的请求返回1 条响应而已。
到这里,我们已经介绍了浏览器与Web 服务器进行交互的整个过程。作为参考,图1.7 展示了浏览器与Web 服务器之间交互消息的一个实例。在这个例子中,我们需要获取一张名为sample1.htm 的网页,网页中包含一张名为picture.jpg 的图片,图中展示了这个过程中产生的消息。
1 条请求消息中只能写1 个URI。如果需要获取多个文件,必须对每个文件单独发送1 条请求。

......
上面内容是网络连接内容的一个小小的点,继续学习网络是怎样连接的,可以读《网络是怎样连接的》,本文内容就节选自它,它是日系图解版“计算机网络概论”,在豆瓣收获9.1分好评,它涵盖了网络的全貌。
即便不提互联网(Internet),大家也都知道网络是一个巨大而复杂的系统,因此用一本书的篇幅涵盖所有的知识是不可能的。
不过,我们可以开启探索之旅,从在浏览器中输入网址(比如 http://www.nikkeibp.co.jp/)开始,一路追踪到显示出网页内容为止的整个过程,这样就能够用一本书的篇幅讲清楚网络的全貌了。
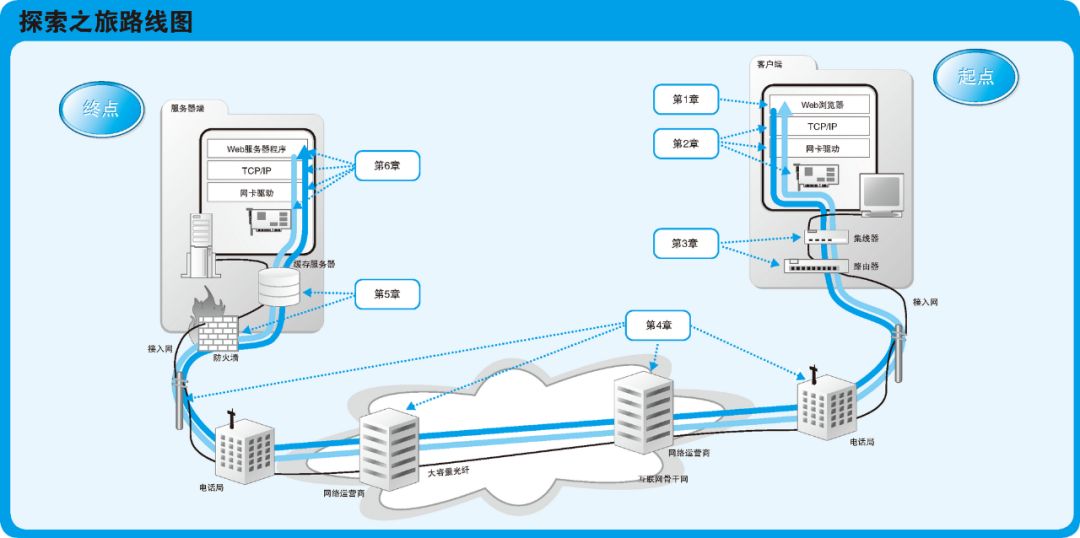
之所以要控制在一本书的篇幅,是因为:如果只是讲解 TCP/IP、以太网这些单独的技术,读者就无法理解网络这个系统的全貌;如果无法理解网络的全貌,也就无法理解每一种网络技术背后的本质意义;而如果无法理解其本质意义,就只能停留在死记硬背的程度,无法做到实际应用。为了避免这一点,即便一本书的篇幅只能介绍有限的一些场景,我们也依然可以涵盖网络系统的全貌。
其次,本书重点介绍了实际的网络设备和软件是如何工作的。TCP/IP、以太网等技术,可以理解为规定网络设备和软件如何工作的一种规则。尽管理解这些规则很重要,但仅仅学习这些规则是无法看到设备和软件的内部构造的。这是因为,为了减少设备生产和软件开发上的制约,网络中的规则将设备和软件的内部构造看作一个黑箱,只从外部视角规定了这些设备和软件的工作方式。而且,实际的设备和软件中还包含很多规则中所没有规定的要素。要想熟练运用网络技术,理解实际的设备和软件是非常重要的,但这一点单靠学习规则本身是无法做到的。考虑到上述原因,本书将重点介绍设备和软件的内部工作方式。
推荐阅读

《网络是怎样连接的》
作者:[日]户根勤
译者:周自恒
日文版重印32次!“计算机网络概论”图解趣味版
本书以探索之旅的形式,从在浏览器中输入网址开始,一路追踪了到显示出网页内容为止的整个过程,以图配文,讲解了网络的全貌,并重点介绍了实际的网络设备和软件是如何工作的。目的是帮助读者理解网络的本质意义,理解实际的设备和软件,进而熟练运用网络技术。
“怎样”系列
01

《机器人是怎样工作的(图解版)》
作者:[日] 濑户文美
译者:许永伟
智能机器人是如何思考的,如何感知周围环境,又是如何运动的。
1.本书包含大量图片讲解机器人的构造和原理。既有真实机器人照片,也有可爱的插画,通过图文并茂讲解机器人的各种形态、动作和零部件工作原理,不仅生动有趣、易读好懂,而且风格独特,令人耳目一新。
2.本书旨在引导读者了解机器人的概貌,对机器人行动的基本原理建立起整体印象,因此在讲解时并未使用深奥的术语和复杂的数学公式,即使小朋友也能看懂。
机器人工程学的超简单入门指南,海量有趣的插图,所有的“结构”仅凭图画就能明白。
03

《计算机是怎样跑起来的(第2版)》
作者:[日]矢泽久雄
译者:胡屹
本书倡导在计算机迅速发展、技术不断革新的今天,回归到计算机的基础知识上。通过探究计算机的本质,提升工程师对计算机的兴趣,在面对复杂的最新技术时,能够迅速掌握其要点并灵活运用。
本书以图配文,以计算机的三大原则为开端、相继介绍了计算机的结构、手工汇编、程序流程、算法、数据结构、面向对象编程、数据库、TCP/IP 网络、数据加密、XML、计算机系统开发以及SE 的相关知识。
04

《程序是怎样跑起来的(第3版)》
作者:[日]矢泽久雄
译者:胡屹
日文版重印50次 中文版重印38次,蹲马桶就能看懂的编程基础知识
本书从计算机的内部结构开始讲起,以图配文的形式详细讲解了二进制、内存、数据压缩、源文件和可执行文件、操作系统和应用程序的关系、汇编语言、硬件控制方法等内容,目的是让读者了解从用户双击程序图标到程序开始运行之间到底发生了什么。书中还专设了“如果是你,你会怎样讲呢?”专栏,以小学生、老奶奶等为对象讲解程序的运行原理,颇为有趣。