高德地图利用Redis Stream优化交通路况计算,成本和延时降低90%+,展现了Redis Stream在海量数据实时计算场景下的应用潜力。
原文标题:什么?!redis也可以是成本优化利器
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、Redis Stream不支持消息重试和延迟消息,这在实际应用中会不会成为一个很大的限制?
3、文章提到了Redis Stream的惰性删除机制,这个机制的具体实现原理是什么?对性能有什么影响?
原文内容

阿里妹导读
本文将从概念、设计、实现和适用场景等多个维度介绍Redis Stream在交通模块的应用。
一、背景
交通路况团队主要负责AMAP(高德地图)轨迹收容和实时计算,不仅承担了实时路况的计算和发布,而且利用海量用户轨迹,陆续推出红绿倒计时和V2X(道路预警)等重磅功能,作为海量数据实时计算的基础链路,自然少不了对消息中间件的使用,一直以来我们都是集团MQ团队的重要客户,随着业务的快速发展,数据规模和计算频次进一步提升,MQ成本急剧增加,替换更加合适的消息中间件成为了必然。
目前集团内部广泛使用的成熟的消息中间件有MQ、TT等,这些消息中间件通常具备高可用,高吞吐,低延迟等特点,同时具备相对完善的控制台和专业团队的支持,但是从成本的角度出发,现有的消息中间件并非合适的选择,经过前期调研,我们最终确定使用Redis Stream作为新的替换方案,截至目前,交通链路的主要环节已经完成了由MQ到Redis Stream的升级,并且取得了显著的成本和延时收益。接下来将从概念、设计、实现和适用场景等多个维度介绍Redis Stream在交通模块的应用。
二、Redis Stream概念
Redis Stream是Redis 5.0版本新增加的数据结构,主要用于消息队列。关于Redis Stream的具体细节,可以参照官网,阅读本篇文章中只需要理解以下概念即可。

图2.1 redis stream结构
-
Redis Stream数据结构的value是一个FIFO的队列,可以通过redis命令指定队列长度,当消息超出队列长度时会自动将最早的消息删除,出于性能的考虑,Redis Stream提供了惰性删除的选项,惰性删除不会在每次添加消息时严格地删除多余的消息,而是通过周期性、阈值触发等机制来删除旧消息;
-
Redis Stream中的每一条消息由id和content构成,id可以手动指定,默认规格是“UNIX时间戳_序号”,时间戳是消息在redis内存创建时的ms时间戳,序号用于区分同一时刻上的不同消息,content即为存储的消息体;
-
Redis Stream支持多个消费者组重复消费消息(广播消费),同一个消费者组下可以创建若干个消费者,多个消费者共同消费同一份数据(集群消费);
-
Redis Stream为每一个消费者组记录了消费位点 last_delivered_id;
-
Redis Stream同时提供了ACK机制,用于消费消息的确认。
三、设计与实现
在交通使用MQ的场景中,上游应用通过哈希规则计算数据的tag,往同一个topic写数据,下游应用的每台机器消费固定的tag,保证同一类数据在同一台机器上进行处理,本文基于这种生产消费模式介绍Redis Stream SDK(C++)的实现。
在现有版本的Redis Stream SDK中,生产者和消费者只需指定topic和tag等简单信息,就可以实现消息的生产和消费,无需关心实现细节,Redis Stream SDK支持多实例、线程配置、同步异步模式、消费位点重置、负载均衡、实时监控,断网重连等功能。
3.1负载均衡
在使用Redis Stream作为消息中间件时,我们需要考虑两个问题,一个是Redis Stream没有tag的概念,另一个是redis实例包含多个分片,同时使用多个实例的情况下,如何保证均匀的使用每个分片,防止数据倾斜。
3.1.1 topic拆分

图3.1 拆分示例
在MQ中,同一个topic下可以有若干个tag,每次发送需要携带topic和tag信息,消费者可以指定tag进行消费,这样既实现集群消费,又保证了同类数据被同一下游处理,而在Redis Stream中没有tag的概念,只有topic的概念,准确的说,只有key的概念,一个topic即为一个key,消息的队列即为key对应的value,为了保证原有功能不变,我们将topic进行拆分,生产者和消费者指定的topic实际上仅为topic的前缀,真正在redis内存中存储的topic(redis的key)实际上是topic和tag的完整信息,形式为“topic_tag”,上游发送消息指定topic和tag,SDK计算出完整的topic并将消息写入,下游消费指定topic和tag,SDK计算出完整的topic进行拉取,这样便实现了“tag”的功能。
3.1.2 分片哈希
在上一部分中,我们解决了tag的问题,接下来的问题是在已知topic和tag的前提下,如何确定消息需要被发送到哪个实例的那个分片,以及如何保证消息被写入到目标分片。

图3.2 哈希说明
以图3.2为例,图中共有4个32分片redis实例,每个实例都有实例idx,每个分片都有局部分片idx和全局分片idx,那么可以通过下列方式计算实例和分片信息。
全局idx = tag % 分片总数
实例idx = 全局idx / 单实例分片数
局部idx = 全局idx % 单实例分片数
redis集群作为一个分布式系统,整个数据库空间会被分为16384个槽(slot),每个数据分片节点将存储与处理指定slot的数据,例如3分片集群实例,3个分片分别负责的slot为:[0,5460]、[5461,10922]、[10923,16383],redis通过CRC算法计算出key所属的slot,进而确定key所属的分片,当key中包含{}字符串,redis仅会根据{}中的值计算slot,我们可以通过遍历的方式暴力计算得到所有slot的哈希字符串并进行存储,确定局部分片idx后可以直接查询,因此,完整的redis stream的topic格式为“topic_tag_{分片哈希字符串}”。
3.2跨机房读写
在使用消息中间件时,跨机房读写是不可避免的,对于跨机房读写的场景,在开发过程中对比了两种跨机房方案,一个是使用hiredis异步模式,另一种是使用集团redis提供的全球多活。

图3.3 跨机房部署
如图3.3所示,生产者部署在na610机房,消费者部署在su121机房,在异步方案中,消息生产采用异步模式,消息消费采用同步模式,在全球多活方案中,消息生产和消费均采用同步模式,在保证数据规模相同,且读写线程足够的情况下,异步模式的平均延迟在22~23ms,全球多活的平均延迟在51ms~57ms,异步模式延迟明显小于全球多活,除此之外,全球多活方案需要额外申请redis 实例,需要更多的redis资源。
3.3工程实现
现有的SDK版本支持灵活的配置,支持使用多个redis实例,可变的消费/生产/处理线程,主要配置如下:
-
生产者
-
实例信息:使用的redis实例信息,支持多个redis实例;
-
单个实例发送线程数:多个线程间遵循轮询的规则,保证每个线程负载均衡;
-
消费者
-
实例信息:使用的redis实例信息,支持多个redis实例;
-
tag信息:订阅的tag列表,用于初始化消费线程;
-
单个线程消费tag数量上限:redis stream支持单次从若干个tag拉取数据(redis限制:tag必须在同一分片),如果单次拉取tag数量过大,会导致消费积压;
-
处理线程数量:单个消费线程对应的处理线程数量,处理线程调用注册的回调函数,当回调函数比较耗时,需要配置较多的处理线程。
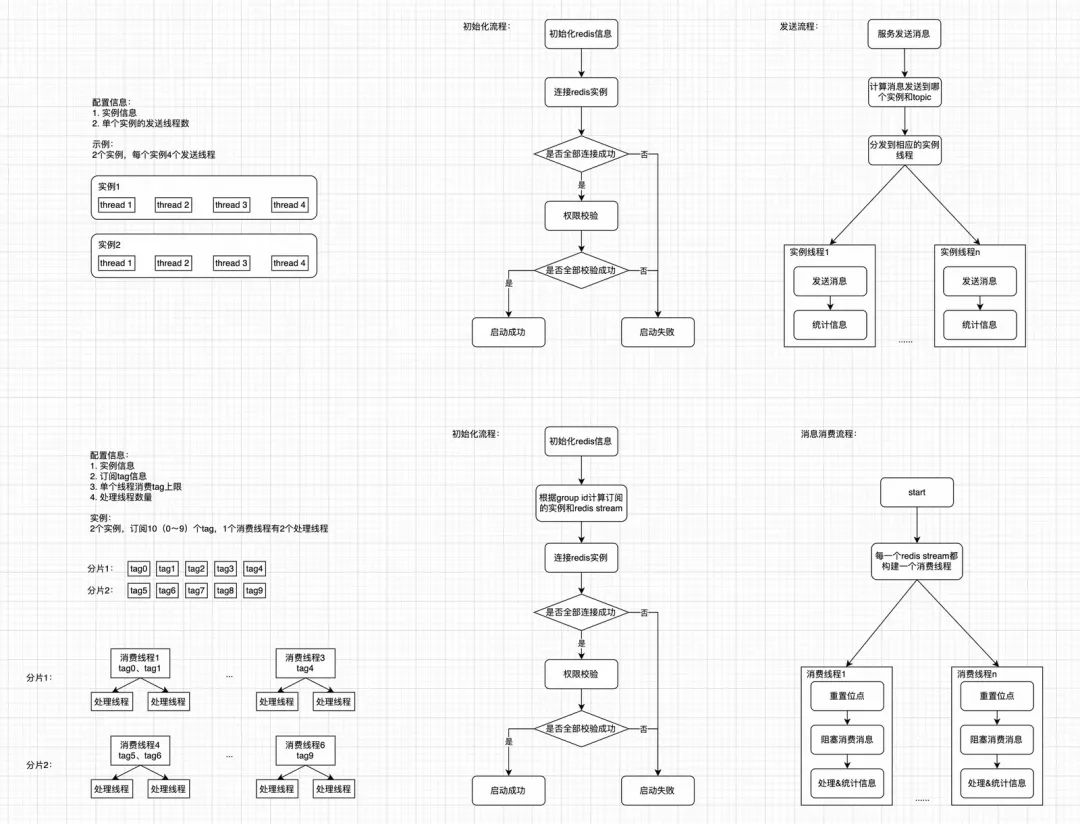
图3.4 Redis Stream流程图
3.4实时监控
集团现有的消息中间件通常具有完善的监控能力和告警机制,可以实时查看和监测消息链路的异常。集团redis实例集群本身提供了CPU、内存、带宽等诸多维度的监控,但是对于消费延迟/积压,却没有现成的支持,因此,使用Redis Stream作为中间件时使用以下多个指标来综合监控消息延迟/积压:
-
生产消费消息量级:在没有积压的情况下,生产者和消费者的消息量级大致是相同的。
-
单次拉取数量:目前消费者只采用了同步消费的模式,在单次拉取消息时,需要指定单次拉取的最大消息数量,当出现积压时,拉取数量会持续接近最大阈值。
-
延时统计:通过对单次写入读取延迟的监控,可以监控由网络问题可能造成的消息积压。
3.5压测表现

图3.5 单线程生产

图3.6 单线程消费
线上环境同步模式下,单线程生产消费TPS上限随着消息大小的增加而减小,消息10k以下TPS上限为3000以上,消息增加到100k时,TPS上限降低为1500。
四、实践经验
4.1线上表现
目前交通链路各个环节MQ升级为Redis Stream已经基本完成,已持续稳定运行一段时间,并取得了显著的成本收益和时延收益,相较于MQ,成本和时延均下降90%+。以某一环节为例,该环节高峰期间消息量级约2000w/min,平均消息大小1k,使用4个 64G 64分片 redis实例,集群日常水位如下:

图4.1 redis集群水位
4.2适用场景
|
MQ |
TT |
Redis Stream |
|
|
优点 |
1.专业的消息中间件产品,功能强大,具备消息不丢、消息重试、延迟消息、集群/广播订阅等特性 2.高可用,高吞吐,低延迟 3.完善的控制台能力,具备报表、报警和消息追踪/验证等特性 |
1.专业的消息中间件产品,除消息重试、延迟消息外与MQ功能基本一致 2.具备更丰富的生产者能力,如sdk、日志采集、binlog同步等 3.高可用,高吞吐,低延迟 4.完善的控制台能力,具备报表、报警等能力 |
1.成本特别低
2.高可用,高吞吐,低延迟
3.支持集群/广播消费、位点重置等基本的消息中间件功能
|
|
缺点 |
1.费用高,读写均收费 |
1.费用高,读收费 2.弹内缺乏C++客户端 |
1.redis持久化问题,服务端异常时,队列数据可能丢失; 2.缺乏消息中间件运维平台 |
4.3踩过的坑/经验分享
-
C++建议使用hiredis的最新版本(1.2.0),最新版本异步模式支持设置连接超时时间,方便异步连接成功的判断;
-
使用Redis Stream作为中间件,消息不宜过大(100k以下),否则消息过大,单线程读写TPS会有明显的下降;
-
在大量数据的业务场景中,tag的数量不宜太少,大量数据通常要使用较多的redis资源,如果tag数量太少,容易导致数据倾斜甚至某些分片无法利用;
-
redis实例资源预估主要考虑的因素是CPU,而不是内存和带宽,Redis Stream可以灵活的设置队列长度,内存通常是可控的, CPU与消息数量有关,具体相关性需要具体实践。
一键训练大模型及部署GPU共享推理服务
通过创建ACK集群Pro版,使用云原生AI套件提交模型微调训练任务与部署GPU共享推理服务。
点击阅读原文查看详情。