GPT-4 Turbo的128K上下文长度开启新机遇,但模型性能随上下文长度变化,需关注输入的有效性。
原文标题:GPT4 Turbo的128K上下文是鸡肋?推特大佬斥巨资评测,斯坦福论文力证结论
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、在使用GPT-4 Turbo时,有什么策略能够提升模型回答的准确性呢?
3、针对GPT-4 Turbo表现不佳的‘中间迷失’现象,大家觉得应该如何改进?
原文内容

本文约2300字,建议阅读5分钟
无论如何,GPT-4 Turbo 确实已经向我们开启了大模型“另一片新天地”的大门。

近期,AI 圈子里最火的事,莫过于 OpenAI 在他们的首届开发者日上重磅推出了 GPT-4 的加强 Plus 版 GPT-4 Turbo。随便摘出来几点 GPT-4 Turbo 对 GPT-4 的升级几乎都是王炸级别,譬如:
-
128K 的上下文长度!?GPT-4 的上下文长度是 32 k,GPT-4 Turbo 直接将上下文长度 x4,128k 的上下文长度完全足够塞进一部中篇小说……
-
知识库更新,GPT-4 Turbo 的记忆来到了 2023 年 4 月,它又知道了这半年来发生的大大小小的大事小事……
-
DALL·E3,文字转语音等等多模态能力向 API 开放……
-
每分钟 tokens 上限翻倍……
-
更快的推理速度……
-
价格直接跳水,降价一半还多……
-
……

凡此种种,似乎让目前这个 GPT-4 Turbo 成为了当前版本的“唯一真神”,难怪符尧大佬在修改了自己 GPT-4 的系统指令之后,得出了“just amazing”的结论:

暂且先将大佬怎么调整自己的系统指令的按住不表,仔细分析 GPT-4 Turbo 的功能,除却价格大幅下调、开放多模态功能这些,真正使得 GPT-4 Turbo 成为“Game Changer”的,还是当属这 128k 的上下文长度。

无疑,更长的上下文长度是能够完成更加复杂任务的必要条件,上下文长度从 32k 到 128k 的变化,不仅仅是“输入更多”的更新,更应该是“能做更多”的进化。而从“输入更多”到“能做更多”,其中一个核心问题便是:“GPT-4 Turbo 真有能力处理差不多近 300 页的长文本的阅读、理解与推理任务吗?”
面对这个问题,推特大佬 Greg Kamradt 针对 GPT-4 Turbo 进行了一场压力测试,流程很简单,Kamradt 使用硅谷创业教父 Paul Graham 的 218 篇文章(长度超过 128k)输入 GPT-4 Turbo,在总体输入的不同长度的段落随机植入下面这段话:
The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day
然后再去问 GPT-4 Turbo “在旧金山最美好的事情是什么?”,并且要求模型只根据上下文回答此问题,同时使用另一个模型(GPT-4)评估答案的质量。结果如下图所示:

简述这个小实验的结果,大概是以下三点:
-
当植入位置超过 73k 长度后,GPT-4 Turbo 的性能开始下降;
-
相对来说,当插入位置在文档深度的 7%~50% 之间时,模型表现不佳;
-
如果插入位置在文档开头,那么模型总能正确找到答案。
由此,Kamradt 认为这项价值 200 刀的实验似乎可以说明:
-
只要问题的答案不是包含在开头,那么 GPT-4 Turbo 并不能保证总能找到答案;
-
更少的上下文长度=更高的准确性,减少向 GPT-4 Turbo 的输入,总会提升其表现;
-
GPT-4 Turbo 还是偏好于在文档的开头与结尾寻找答案。
无独有偶,推特网友 Louis Knight-Webb 进行了另一项实验,通过在文档中随机插入:
My name is {randomCountry} and I have a pet ${randomAnimal}.
再让 GPT-4 Turbo 进行名称的问题回答,Louis 发现,相比 GPT-4,GPT-4 Turbo 的能力有巨大的提升,在上下文长度为 32k 的条件下,GPT-4 Turbo 的平均检索正确 2.4 个人名、城市名与动物名,而 GPT-4 仅为 1.1 个。但是,和 Kamradt 一样,Louis 同样发现,即使是 GPT-4 Turbo,在更大的上下文大小上仍然表现不佳:

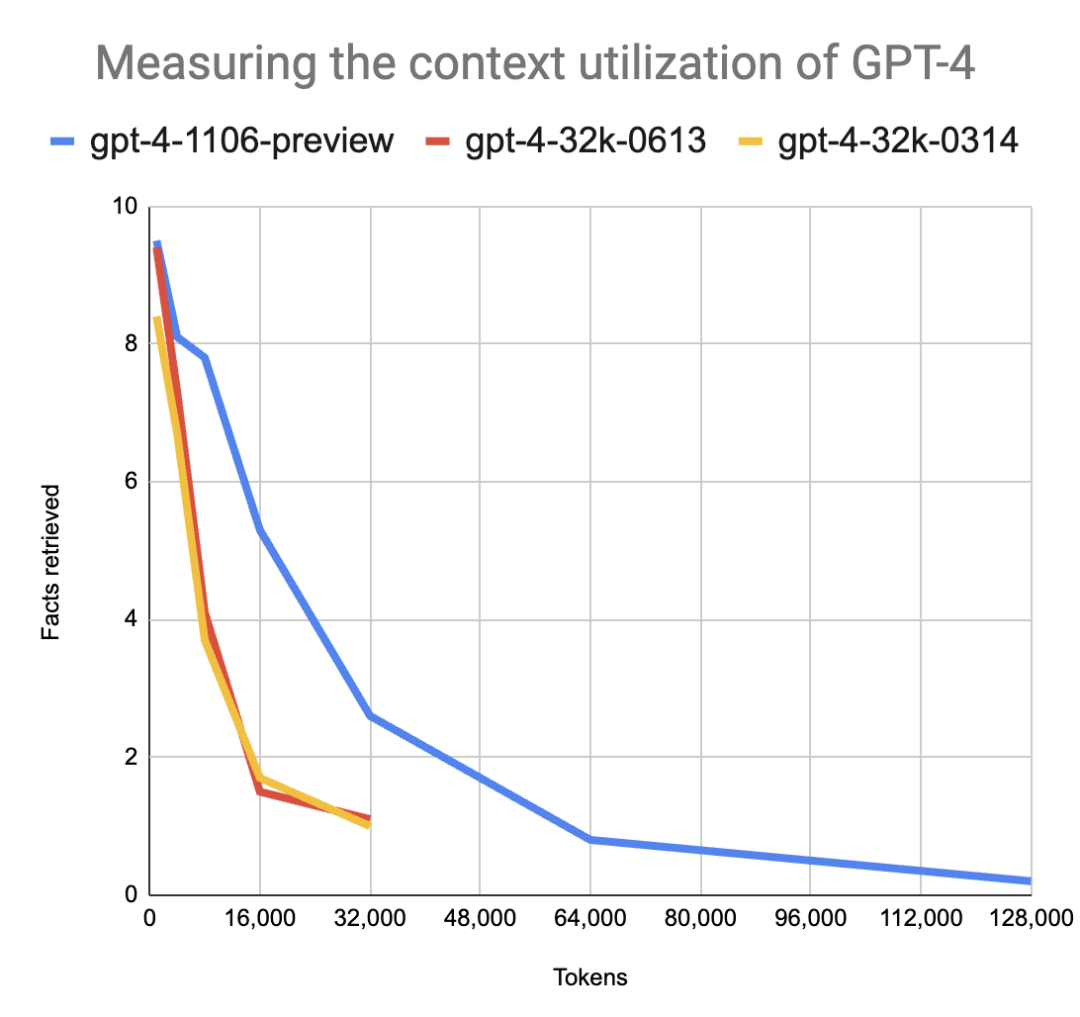
事实上,早在 7 月份,来自斯坦福的一篇论文《Lost in the Middle: How Language Models Use Long Contexts》便揭示了 GPT-4 的性能随着上下文长度以及答案在上下文中的位置发生的变化的现象,这篇论文的作者们发现相关信息的位置和提供的上下文的长度可以极大的影响大模型的性能,几乎所有大模型都出现了“Lost in the Middle”的现象,甚至在一些情况下,当问题答案在文档中间时,其性能甚至弱于 Zero-shot 的版本。:

那么为什么会出现这种模型性能随上下文长度出现 U 型曲线的现象呢?很遗憾目前这个问题还属于一个开放问题。

在论文中作者实验发现,采用 Transfomer 式的编-解码器模型对上下文长度的变化表现的更加稳健,而类似 GPT 这种仅使用 Decoder 的模型由于每一步只关注当前 token 之前的内容,导致出现了类似 RNN 一样的“遗忘”。因此,这篇论文也提出了一种名为“Query-aware contextualization”的技术辅助改善 GPT 的 Lost(详细信息可以查询下方原文~)。也有学者认为这一现象的出现与训练数据本身的偏差有关,即人类的大量语料一般都将重要信息放置于开头或结尾,间接导致了大模型无法很好的关注处于文档中间的内容。
论文题目:Lost in the Middle: How Language Models Use Long Contexts论文链接:https://arxiv.org/pdf/2307.03172.pdf
不过总结来看,这几项关于 GPT-4 Turbo 的实验可以为我们使用目前这个“版本答案”提供一些经验上的洞见:
-
目前 GPT-4 Turbo 的准确率与上下文长度哪怕是在 128k 的范围内也依然成反比,能利用各种手段少输入一些内容那么就少输入一些内容;
-
相比于在文档居中的部分,GPT-4 Turbo 还是更加擅长寻找开头与结尾的答案,我们不仅需要充分利用好比如论文摘要、引言与结论的结构化信息,还需要尽量把关键信息放置在上下文窗口的开头或结尾附近;
-
一般而言,当提供给 GPT-4 Turbo 的文档之间相关性很弱时,也会影响模型的性能,因此尽量给模型输入相关性比较强的内容;
-
提供更多的任务示例 maybe 相当于为模型提供了一个“便签”,有助于抵消随着上下文长度增加而导致的性能下降。
-
欢迎评论区的大家伙继续补充哇……
当然,除了模型性能受上下文长度影响的问题以外,当前版本的 GPT-4 Turbo 还被大家指出不少问题,比如有网友发现 GPT-4 Turbo 不能很好的识别文档里的公式:

也无法很好的描述论文里的图表:

甚至还有大佬自测实验,直接指出 GPT-4 Turbo 考 SAT (美国高考)考不过 GPT-4(尽管样本量不大):

当然,无论如何,GPT-4 Turbo 确实已经向我们开启了大模型“另一片新天地”的大门,128k 的上下文长度或许可以让我们之前无法想象的应用变成现实。同时,128k 也绝对不是上下文长度的极限,参考我们 7 月份报道过的在当时拥有 100k 上下文长度的 LongLLaMA(羊驼再度进化,“长颈鹿版”LongLLaMA 来啦,上下文长度冲向 100K ,性能不减),现在已经将模型的上下文长度扩展到 256k,未来 GPT 模型的上下文长度一定会再次出现飞跃,到那时,除了模型内部的问题以外,超长上下文背后可能的大规模数据传输、API 调用、网络协议等等“基础设施”都有可能成为新的问题。

让我们符尧大佬对 GPT-4 Turbo 调整后的系统指令和大佬给的一个与模型互动的例子作为结尾:

可以看到,GPT-4 Turbo 表现出的潜力,或许真如大佬所说:
I start to understand why such a thing can make a human 10x human

最后的最后,大家对 GPT-4 Turbo 有什么实用的使用经验,欢迎分享在评论区~
