原文标题:我的原创图书《从零构建向量数据库》正式出版了!
原文作者:图灵编辑部
冷月清谈:
-
适用人群:
对向量数据库感兴趣,希望深入了解其构建过程和原理的初级程序员;对数据库领域感兴趣,希望了解其构建过程和核心技术的专业人士;AI 应用开发人员,希望优化 AI 应用,提升数据管理效率。 -
内容结构:
**第一部分:**认识向量数据库(第 1-3 章):介绍向量、向量数据库,以及腾讯云向量数据库的功能。**第二部分:**构建向量数据库(第 4-6 章):详细介绍从零构建单机向量数据库和分布式向量数据库的步骤,涉及索引系统、故障恢复、流量调度、元数据管理等技术要点。
**第三部分:**向量数据库的实践与展望(第 7-8 章):介绍向量数据库在 AI 应用中的使用方法,展望其未来发展趋势。
-
核心特色:
侧重实战,从代码段和原理解析入手,带领读者动手构建向量数据库;提供思维导图、版本信息、开源库列表等辅助资源,帮助读者快速掌握知识点;结合腾讯云向量数据库的实际功能,深入剖析行业技术。
怜星夜思:
2、对于向量数据库未来发展前景如何看待?
3、向量数据库在实际应用中,需要注意哪些挑战和瓶颈?
原文内容

因为封面主图是珊瑚
我知道,由于个人的理解和写作水平有限,本书无法做到面面俱到,也不能保证万无一失。但如果这本书能让正在阅读的你对向量数据库有更多了解,并能上手打造一个原始简略版的向量数据库,那么它之于我的价值将不可估量。
本书是一本实战类图书,也涉及简单的原理解析,书中的技术点都是初级程序员就可以理解的。如果你完全不了解编程,建议先打好编程基础,毕竟书里有不少需要你动手操作的源码。
-
如果你对向量数据库感兴趣,想深入了解向量数据库源码级别的构建过程,本书将教你从零打造一款分布式向量数据库。内容涉及:如何从单机数据库引擎开始构建索引系统,如何增强系统的故障恢复能力,以及如何实现数据库的分布式和集群运作,包括数据复制、流量调度和元数据管理等核心技术。
-
如果你对数据库领域感兴趣,想深入了解数据库源码级别的构建过程,本书同样适合你阅读——分布式向量数据库的完整构建过程涵盖了这一领域的核心知识。
-
如果你对 AI 应用开发感兴趣,想了解 AI 应用背后的向量数据是如何生成和管理的,本书将介绍向量数据与大模型的关系,并带你学习向量数据库查询的整个流程。这将帮助你更好地结合向量数据库优化 AI 应用,更新知识,更有效地应对 AI 应用落地过程中的挑战。
-
如果你是 AI 应用开发专家或数据库领域的专家,希望帮助本书发现改进之处,推动行业发展,本书也值得一读。阅读本书可能会激发你更多有价值的思考。向量数据库是一个较新的领域,更多的信息共享无疑会促进这一领域的进步。
作为本书的背景知识介绍篇,本部分旨在帮助你奠定必要的理论基础。
-
第 1 章:介绍向量及向量数据库的基础知识,普及关键概念——向量、数据库、向量数据库。
-
第 2 章:介绍向量数据库这一新兴技术的发展历程,包括关键技术的进展、相关企业与创业团队的成长历程,以及目前业界常见的几种架构模式。本章有助于你从宏观角度把握技术演进。
-
第 3 章:以腾讯云向量数据库(Tencent Cloud VectorDB)为例,带领你探索向量数据库核心功能的实现。如果你准备自行开发或深度使用向量数据库,本章属于基础知识。
-
第 4 章:从零开始构建单机向量数据库。本章基于模块化的设计理念,使用一些成熟的开源组件,逐步加入通用软件和数据库技术,并应用数据库行业的持久化和故障恢复技术,最终完成单机向量数据库的构建,使其小而完备,达到某些开源单机向量数据库的原型水平。
-
第 5 章:在单机向量数据库的基础上继续开发分布式向量数据库,涉及元数据的有效管理、流量调度和异常处理等。从本章开始,我们的向量数据库将具备支持一定规模的向量数据管理场景的原型水平。如果你希望理解分布式系统底层机制,以及想了解如何将单机系统扩展为分布式系统,一定不要错过这一章。
-
第 6 章:基于前两章构建的分布式向量数据库,本章将展示如何对数据库进行优化,包括性能、成本和易用性三个方面。性能优化方面将探讨如何利用 CPU/GPU 的计算能力提升性能;成本优化方面则关注简化业务部署模型以降低运营成本;最后讨论如何使向量数据库产品更易于开发者使用,如提供良好的 SDK 和数据备份机制,这对推广新技术至关重要。
本部分是本书的结束篇,围绕实践和展望进行阐述。通过本部分的学习,你不仅能够将书中的理论知识与实际操作相结合,还能展望技术未来,帮助自己为学习和职业生涯规划找明方向。
-
第 7 章:本章从实践角度出发,验证我们自行开发的向量数据库在 AI 应用中的使用方法。我们将实现第 1 章提到的以图搜图和知识库,这两个场景近年来在 AI 应用中使用广泛。
-
第 8 章:本章将回溯计算机行业的发展历程,以此为出发点,探索向量数据库的未来。一方面,聊一聊为何向量数据库有可能成为一项平台级的技术;另一方面,基于当前向量数据库在 RAG(retrieval-augmented generation,检索增强生成)场景中的应用,拓展讨论向量数据库未来的发展。本章旨在与你共同思考和展望向量数据库的长远趋势。

(本书目录,可放大)
1.层次结构式思维导图
在部分章节,为了帮助你快速掌握向量数据库的核心功能和模块的组成,本书以层次结构的形式给出了相关知识点的思维导图。无论你是希望理解还是实现向量数据库,阅读之前,记得先浏览思维导图,以做到胸中有数。比如,单机版向量数据库的偏平索引实现如下所示:

2.迭代与升级
本书中,我们一起构建的向量数据库将经历从 v0.0.1 到 v0.6 多个版本的迭代与升级。从 v0.0.1升级到 v0.0.2 这种小版本号变化,本书称为一次版本迭代;而从 v0.0.2 升级到 v0.1 这种大版本号变化,本书称为一次版本升级。每个版本都会实现特定功能的添加或者更新。为了方便你实现对应版本的功能,同时能够随时了解或者回顾,本书在目录中加入了版本号的迭代与升级。
另外,对于重大版本更新,我们还在相应章的“小结”一节提供了版本架构图,这将有助于你全面理解向量数据库的实现方式和架构变化。比如 v0.6 版本迭代之后的架构图如下所示:

3.新增 / 更新的模块和引入的功能列表
本书以表格形式列出了各版本中新增 / 更新的模块和引入的功能列表,这样做的目的是帮助你更好地理解向量数据库的核心能力,最终自己动手实现代码。在阅读过程中,请充分利用书中提供的源码、思维导图、架构图、版本信息模块及功能列表这些资源。这些都是我精心设计的重要工具,来帮助你更有效地学习本书内容。比如,v0.2版本新增/更新的模块和引入的功能如下所示:

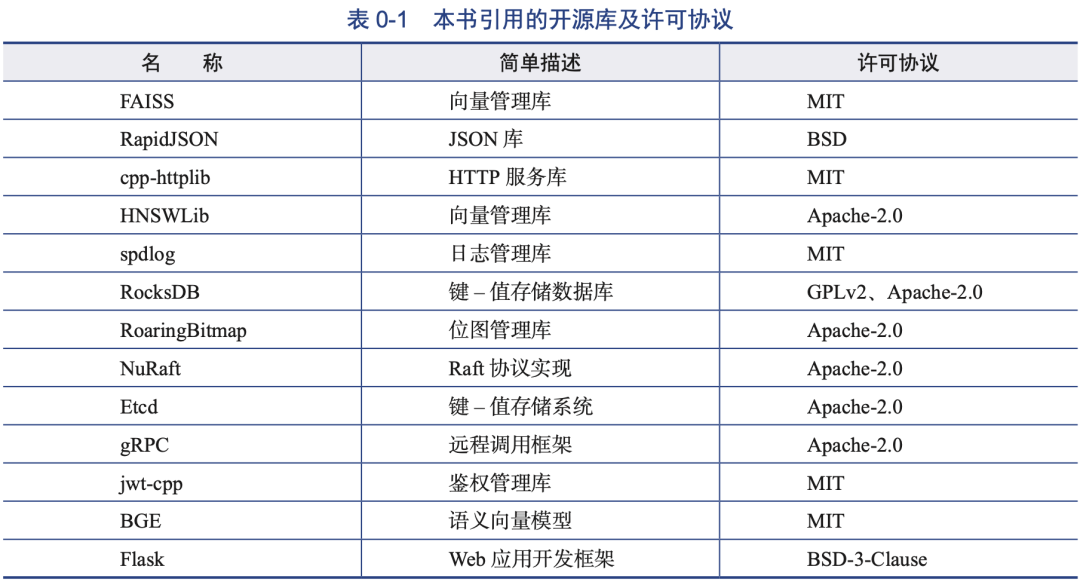
4.开源库

18 楼可获得瑞幸联名《黑神话:悟空》之