原文标题:阿里开源语音处理模型 FunAudioLLM :50 种语言无缝翻译,还能识别语音情绪
原文作者:AI前线
冷月清谈:
- 多语言语音识别,支持 50 多种语言,中文和粤语准确度提升 50% 以上
- 情感识别,准确率达到或超过当前最佳模型
- 声音事件检测,识别音乐、掌声、笑声等多种情绪和交互事件
CosyVoice 关键特性
- 多语言合成,支持中英日粤韩 5 种语言,效果优于传统模型
- 极速音色模拟,仅需 3-10 秒原始音频,即可生成韵律、情感一致的模拟音色
- 细粒度控制,支持通过文本或自然语言控制生成语音的情感和韵律
应用场景
- 多语言语音翻译
- 情绪语音对话
- 互动播客
- 有声读物
怜星夜思:
2、CosyVoice 的音色模拟功能有哪些潜在的应用价值?
3、FunAudioLLM 的情感语音对话功能可以如何改变人机交互的方式?
原文内容

作者 | 赵明华
阿里巴巴通义实验室近日发布并开源了 FunAudioLLM,这是一个旨在增强人与大型语言模型(LLMs)之间自然语音交互的框架,代表了语音处理领域的最新进展。
这一框架的核心是两个创新模型:SenseVoice 和 CosyVoice。这两个模型不仅在多语言语音识别、情感识别、音频事件检测和自然语音生成方面表现出色,还展示了极高的成熟度和广泛的应用潜力。
● 多语言识别:采用超过 40 万小时的数据训练,支持超过 50 种语言,在中文和粤语上的识别准确度提升超过 50%。
● 情感辨识:具备出色的情感识别能力,在测试数据上达到或超过当前最佳情感识别模型的效果。
● 声音事件检测:能够识别多种情绪和交互事件,如音乐、掌声、笑声、哭声等。
● 模型架构:包括自动语音识别(ASR)、语言识别(LID)、情感识别(SER)以及音频事件检测(AED),能够适应不同应用场景。
● 多语言合成:采用了总共超 15 万小时的数据训练,支持中英日粤韩 5 种语言的合成,合成效果显著优于传统语音合成模型。
● 极速音色模拟:仅需要 3 至 10 秒的原始音频,即可生成模拟音色,包含韵律和情感等细节,甚至能够实现跨语言的语音生成。
● 细粒度控制:支持通过富文本或自然语言形式,对生成语音的情感和韵律进行细粒度控制,大大提升了生成语音在情感表现力上的细腻程度。
● 模型架构:包含回归变换器,用于生成输入文本的语音标记;基于 ODE 的扩散模型(流匹配),用于从生成的语音标记重建梅尔频谱;以及基于 HiFTNet 的声码器,用于合成波形。
FunAudioLLM 不仅在技术上有所突破,其应用前景也十分广泛。基于 SenseVoice 和 CosyVoice 模型,该项目可以支持多种人机交互应用场景,例如音色情感生成的多语言语音翻译、情绪语音对话、互动播客和有声读物等。

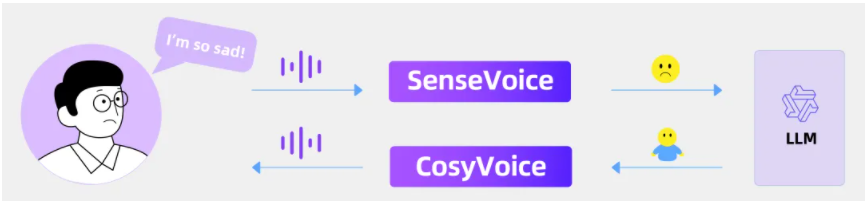
通过融合 SenseVoice、大语言模型(LLM)和 CosyVoice,FunAudioLLM 能够开发出一款情感语音聊天应用。

通过将 SenseVoice、基于 LLM 的实时知识多代理系统和 CosyVoice 整合,FunAudioLLM 可以创造一个互动式播客电台。

结合 LLM 的文本分析能力和 CosyVoice 的语音生成技术,FunAudioLLM 能够制作表现力更强的有声读物。
目前,与 SenseVoice 和 CosyVoice 相关的模型已在 ModelScope 和 Huggingface 上开源,同时在 GitHub 上发布了相应的训练、推理和微调代码。
参考链接:
https://fun-audio-llm.github.io/
论文链接:
https://fun-audio-llm.github.io/pdf/FunAudioLLM.pdf

在主题演讲环节,我们已经邀请到了「蔚来创始人 李斌」,分享基于蔚来汽车 10 年来创新创业过程中的思考和实践,聚焦 SmartEV 和 AI 结合的关键问题和解决之道。大会火热报名中,7 月 31 日前可以享受 9 折优惠,单张门票节省 480 元(原价 4800 元),详情可联系票务经理 13269078023 咨询。

今日荐文
