深入拆解DeepSeek-R1的训练方法、核心优势与市场影响,探讨其在模型蒸馏、自主推理和成本控制方面的突破,以及对AI生态的深远影响。
原文标题:三问一图万字拆解DeepSeek-R1:训练之道、实力之源与市场之变
原文作者:阿里云开发者
冷月清谈:
其次,文章分析了DeepSeek-R1的三个主要优势:蒸馏技术的巨大潜力,自主推理中涌现的“灵光乍现”,以及显著降低的成本投入。通过蒸馏,小模型也能获得逼近R1的推理能力,降低了AI应用门槛。此外,RL训练使得模型能够自主开发出高级问题解决策略。
最后,文章探讨了DeepSeek-R1对B端和C端用户以及整个AI行业生态的影响。在B端,企业对私有化部署的需求增加,定制化门槛降低;在C端,重新点燃了AI应用市场,降低了使用门槛。总体而言,DeepSeek-R1的出现推动了AI技术在降低成本的同时提升性能,为更广泛的用户群体带来了先进的AI体验。
怜星夜思:
2、DeepSeek-R1通过蒸馏技术,让小模型也能获得强大的推理能力,这种蒸馏的具体原理是什么?对于我们日常的模型训练和应用,有什么启发?
3、文章提到DeepSeek-R1的训练成本远低于OpenAI的o1,这主要归功于在AI infra上的持续探索。那么,AI infra具体包括哪些方面?DeepSeek在哪些方面做了优化,从而实现了如此显著的成本降低?
原文内容

阿里妹导读
本文是作者基于自己的学习经历重新组织的一篇更易于初心者理解的关于DeepSeek的文章,也可以说是作者阶段性的学习笔记。
前言
距离DeepSeek发布已近三个月,DeepSeek的热度仍在持续发酵当中,在网络上可以看到眼花缭乱的有关DeepSeek-R1的技术文章,不过很多都是对论文原文的摘要或者零碎知识点的拼接,阅读下来依然会有很多不解之处,于是我打算基于自己的学习经历重新组织一篇更易于初心者理解的文章,也作为自己阶段性的学习笔记。
为了能够让大家保持与文章行文逻辑之间的同频,我会先抛出几个问题,并按照解答这几个问题的顺序来组织文章。
这三个问题分别是:
-
DeepSeek-R1是如何训练而来的?——即DeepSeek-R1的训练过程
-
DeepSeek-R1强在何处?为何一时之间火爆全球?
-
DeepSeek-R1的出现能够给我们带来些什么?市场与行业是如何反应的?
想必大家刚接触到DeepSeek时脑中最先冒出的也会是这几个疑问,希望这篇文章可以帮助大家更好地梳理思路。
DeepSeek-R1是如何训练而来的?
为了更清晰地了解DeepSeek-V3/R1是如何训练而来的,我与Claude老师协作绘制了一个训练流程图(Claude老师画图好厉害)。目前网络上流传着诸多类似的流程图,不过有一个共同的问题在于,它们均未在图中体现DeepSeek-V3从而导致很多人会误以为DeepSeek-R1是基于DeepSeek-V3训练而来的。
此处要澄清的是,这两个模型是以相同的起始点DeepSeek-V3-Base基模训练而来的,这是一个在14.8万亿tokens上预训练得到的基模。同时V3/R1两者的训练思路十分相似,均是先训练一个质量优良的数据生成器来为自己“生产数据”,两者只是侧重点有所不同,且从论文上来看两者都用到了对方来为自己生成SFT数据(V3提到用R1生产推理数据,R1提到用V3生产非推理数据),这种“左脚踩右脚螺旋上天”的现象看起来有些矛盾,但实际上是两者在并行的探索训练当中,会用对方的某个检查点版本作为数据生成器,倒也不难理解。
下图尽可能简洁地展示了V3/R1两者的训练流程(如有纰漏欢迎指正):

由笔者与Claude老师共同绘制而成,赞扬一下Claude老师的审美
其过程也可用自然语言描述如下:
R1训练过程概述:
DeepSeek-V3-Base—>冷启动数据SFT—>基于GRPO的RL—>DeepSeek-R1-Zero-Teacher—>拒绝采样—>推理数据60W;
DeepSeek-V3 Pipeline + 部分V3 SFT数据—>非推理数据20W; DeepSeek-V3-Base—>推理数据+非推理数据80W SFT—>基于GRPO的RL—>DeepSeek-R1;
以DeepSeek-V3-Base作为基模,首先收集数千条高质量长CoT数据作为冷启动数据进行SFT微调,再采用GRPO作为强化学习方法进行RL训练,强化学习过程接近收敛时,对RL的Checkpoint进行拒绝采样(rejection sampling)来创建新的SFT数据,再结合DeepSeek-V3在写作、事实问答、自我认知等领域的监督数据,对DeepSeek-V3-Base进行重新训练。
第一阶段—训练一个高质量CoT提供者/老师
第一阶段第一步—冷启动(Cold Start)
目的:避免RL训练初期的不稳定,为模型建立具备良好可读性的思维链基础,从而后续可以提供高质量CoT数据。
做法:
1.收集数千条长思维链(CoT)数据作为冷启动数据;
收集过程中用到的几种方法:
-
以长思维链作为样例的少样本提示(Few-shot)生成方法,提示模型“照猫画虎”生成类似的长思维链数据;
-
直接要求模型生成自带反思与验证的详细答案;
-
整理DeepSeek-R1-Zero的原始输出为可读性更好的形式;
-
人工标注修正;
2.以DeepSeek-V3-Base作为基模,在冷启动数据上进行SFT微调,获得了后续大规模RL的训练起点。
相对于DeepSeek-R1-Zero加入【冷启动】的意义:
DeepSeek-R1-Zero是基于DeepSeek-V3-Base直接进行大规模RL所得到的模型,该模型的输出会出现 【可读性差】、【语言混杂】 的问题,冷启动阶段的数据通过 【|special_token|<reasoning_process>|special_token|<summary>】的输出格式 + 人工筛选读者友好响应 让DeepSeek-R1的输出可读性更好,避免了语言混杂问题。
增强可读性也是为了后续可以生成高质量的CoT数据。
第一阶段第二步—大规模强化学习(RL)
目的:增强模型推理能力
做法:
采用GRPO作为强化学习框架,进行数千步的RL训练,直至模型在推理任务上收敛,专注于增强模型的推理能力,尤其是在编码、数学、科学、逻辑推理等推理密集型任务上,这些任务通常是定义清晰、解法明确的。
💡 看到这里,大家可能会对GRPO的具体原理有所疑惑,但出于对篇幅与主题聚焦的考虑,暂不在本文展开。如果大家感兴趣的话,这块梳理了一部分内容后续也可以更新;
GRPO的奖励机制:
奖励是训练信号的来源,决定了RL的优化方向。R1采用了一种基于规则的奖励系统,由以下两种奖励构成:
-
Accuracy Rewards 准确性奖励:评估模型的响应是否正确,适用于有确定性结果的数学问题(以指定格式提供答案),或可根据测试用例生成反馈的LeetCode编程问题。
-
Format Rewards 格式奖励:要求模型将思考过程放置于<think> </think>之间。
-
除了以上奖励之外,为了缓解语言混杂问题,R1相较于R1-Zero还额外引入了:
-
Language Consistency Rewards 语言一致性奖励:计算CoT中目标语言词汇所占比例;
RL所用到的训练模板,引导模型输出 推理过程 与 最终答案 两部分:
A conversation between User and Assistant. The user asks a question, and the Assistant solves it.The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>. User:
prompt. Assistant:
其中prompt用具体的推理问题代替,故意采取这种高度约束的模板结构是为了避免任何 内容特定 的偏见(例如强制反思性推理或提升特定问题解决能力的策略)。
💡 这种大规模RL的优势是直接让模型基于该训练模板生成长CoT答案,再根据奖励引导模型。
而如果采用SFT微调的形式,则需要大量的答案为长CoT的高质量数据,获取这类数据显然是困难的。
第二阶段—基于CoT老师收集微调数据
目的:收集足量的高质量CoT微调数据
做法:
1.利用拒绝采样(Rejection Sampling)收集推理数据(Reasoning data):
-
数据收集:利用RL训练收敛后的模型执行拒绝采样,对每个提示进行多次采样,以生成推理轨迹;
-
数据评估:
-
正确性奖励评估:每个提示会采样多个响应并仅保留正确答案。
-
生成式奖励评估:部分数据以DeepSeek-V3作为生成式奖励模型,将真实值和预测值输入V3进行质量评估;
-
数据过滤:过滤CoT中包含【语言混杂、过长段落、代码块】的低质量数据;
-
获得总计60W条的高质量推理数据。
2.复用DeepSeek-V3的Pipeline及其部分SFT数据获得非推理数据(Non-Reasoning Data):
-
DeepSeek-V3的Pipeline即为,用DeepSeek-V2.5为非推理数据生成回复再进行人工标注,所以此处采用V3 Pipeline的意思大概是,使用DeepSeek-V3针对这些问题生成回复再进行人工标注。
-
某几个特定任务会用提示词引导V3生成CoT响应,但简单查询(如“Hello”)不会在响应中提供CoT;
-
非推理数据包含写作、事实问答、自我认知和翻译等类型,总计20W条。
此处使用【拒绝采样】的核心目的在于,高效收集符合 RL收敛模型 分布的高质量CoT数据。
拒绝采样解决的问题是,当我们有一个无法直接采样的复杂分布p ( x ) p(x),我们可以借助一个代理分布q(x)进行采样(q(x)也被称为提议分布)。
其具体做法为,用大于1的常数M与代理分布q(x)相乘,使得Mq(x)的分布完全“罩住”p(x)分布,如下图所示:

拒绝采样算法的执行过程即大致如下:
1.从M q ( x ) 分布随机采样一次获得![]() ;
;
2.对于![]() 计算接受概率(Acceptance Probability):
计算接受概率(Acceptance Probability):![]() ;
;
3.从 均匀分布![]() 中随机采样一个值u;
中随机采样一个值u;
4.如果α ≥ u ,则接受![]() 作为一个来自p(x)的采样值,否则就拒绝
作为一个来自p(x)的采样值,否则就拒绝![]() ,回到第1步循环往复直至收集足够样本;
,回到第1步循环往复直至收集足够样本;
该算法依赖于一个基本原理,即高概率区域采样到的样本应该更多。
因此从直观上看,红色曲线和绿色曲线所示之函数更加接近的地方接受概率α较高,也即更容易大于u被接受,所以在这样的地方采样到的点就会比较多(目标分布p(x)在该点处的采样概率也较大),而在接受概率α较低(即两个函数差距较大)的地方采样到的点就会比较少(目标分布p(x)在该点处的采样概率也较小),从而保证最终采样到的点总体上逼近期望分布p(x)。
在当前场景中,理想的高质量CoT样本分布即为p(x),RL收敛模型生成的样本分布即为q(x),并利用 正确性奖励、生成式奖励 筛选出符合目标分布的样本。
💡 所谓生成式奖励模型,即为用DeepSeek-V3为真实值和预测值分别打分,生成式是相对于规则式而言的,规则式奖励即 判断其正确性(是否与参考答案一致)或格式合规性(是否符合预期格式)。
第三阶段—迭代微调
第三阶段第一步—SFT微调
基于DeepSeek-V3-Base在以上共计80W条的推理+非推理数据上进行SFT
💡 注意,此处我们重新以最初的基模DeepSeek-V3-Base为起点进行微调,前面步骤的训练操作均是为了收集 高质量CoT推理数据 而准备的,并不会作为后续训练的起点;
第三阶段第二步—大规模RL
全场景强化学习,以进一步对齐人类偏好(helpfulness and harmlessness),提升推理能力
该阶段结合奖励信号和多样化的提示分布来训练模型,从而获得推理能力出色,优先考虑有用性和无害性的模型,具体如下:
-
对于推理数据,遵循R1-Zero的方法,利用基于规则的奖励指导数学、代码和逻辑推理领域的学习过程。
-
对于通用数据,采用奖励模型(Reward Models)捕捉人类在复杂/微妙场景中的偏好,基于DeepSeek-V3的流程并采用类似的 偏好对和训练提示 分布。
-
对于有用性,专注于最终摘要,确保评估方式强调响应的实用性和相关性,同时最小化对底层推理过程的干扰。
-
对于无害性,评估模型的完整响应,包括推理过程及摘要,以识别并减轻生成过程中可能出现的任何潜在风险、偏见与有害内容。
经过以上步骤,我们便得到了DeepSeek-R1。
DeepSeek-R1强在何处?为何一时之间火爆全球?
若问强在何处,可以用它最具现象级影响的三个方面作为回答:
-
蒸馏的潜力原来这么大
-
自主推理中的“灵光乍现”(Aha moment)
-
显著降低的成本投入
R1老师的蒸馏课
第一强在于,在R1的研究中发现,将R1强大的推理能力迁移到通用模型存在超预期的巨大潜力。
为了让更高效的小模型具备类似R1的推理能力,研究者直接用基于R1蒸馏的80W条数据在Qwen/Llama系列开源模型上进行了SFT微调,结果表明蒸馏显著提升了小模型的推理能力。
参与实验的基模包括 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B 和 Llama-3.3-70B-Instruct。
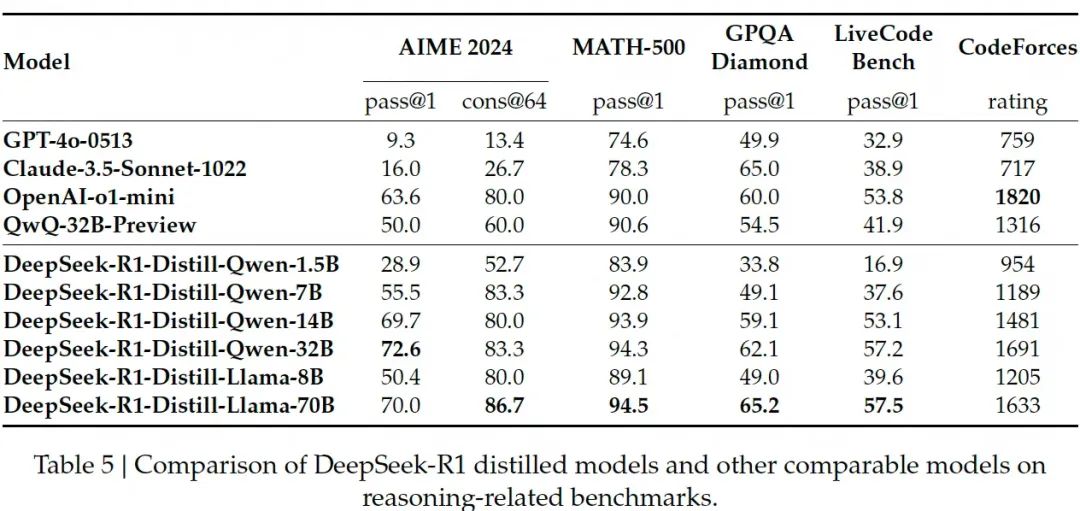
蒸馏实验结果表明,通过蒸馏DeepSeek-R1的输出所获得的DeepSeek-R1-Distill系列模型性能强大,DeepSeek-R1-Distill-Qwen-7B依靠仅7B的参数规模即可全面超越GPT-4o-0513等非推理模型,而DeepSeek-R1-Distill-Qwen-32B和DeepSeek-R1-Distill-Llama-70B则在大多数基准测试中显著超越o1-mini,这似乎意味着行业的一个新范式正在来临,在我们拥有像R1这样顶尖的推理模型后,可通过蒸馏技术快速以低成本方式让基模获得逼近R1老师的推理能力。
另外,研究中还进行了一场 蒸馏Distillation v.s. 强化学习Reinforcement Learning 的PK实验,利用数学、代码和STEM数据在Qwen-32B-Base上进行超过10K步的大规模RL训练获得DeepSeek-R1-Zero-Qwen-32B,发现其性能与QwQ-32B-Preview相当,但全方位弱于DeepSeek-R1-Zero-Qwen-32B。

换句话说,在相同基模的前提下,基于DeepSeek-R1输出蒸馏(SFT)的性能显著好于基于推理数据RL训练,而蒸馏模型的基础上再进行RL又会获得显著提升,从而体现了蒸馏这一技术的重要性。
基于以上实验结果也可以得出两个结论:
-
蒸馏相比于RL的性能提升更大,成本更低:将更强大的模型蒸馏到较小的模型中能够产生优异的结果,而依赖本文中提到的大规模 RL 的小模型需要巨大的计算资源,甚至可能无法达到蒸馏的性能。
-
蒸馏建立在基模与RL迭代优化的基础之上:尽管蒸馏策略既经济又有效,但要突破智能的边界,可能仍然需要更强大的基模和更大规模的强化学习。
不难看出,对于大多数用户和企业来说这种方式相比传统自行SFT+RL的方式来说不仅成本更低而且可以获得具备更优异推理能力的模型,可谓大大降低了门槛,意义非凡。
同时研究中还提到,对这些蒸馏模型应用强化学习可以带来显著的进一步收益,这部分报告中并未给出具体的实验结果,留给未来社区探索。
很快,这一想法便被来自UC伯克利的研究团队验证,他们基于DeepSeek-R1-Distill-Qwen-1.5B进行RL微调获得了,以仅1.5B的参数规模在数学权威基准AIME2024上超越了o1-preview。
其采用的训练策略是——先短后长(Think shorter, then longer)
先短:首先模型会被训练进行短思考,基于GRPO方法与8k的上下文长度来训练模型,以鼓励高效思考。经过1000步训练后,模型的Token使用量减少了3倍,性能相比基模提升了5%。
后长:其次模型会被训练进行长思考,强化学习训练扩展到16K和24K Token,以解决更具挑战性、以前无法解决的问题。
随着响应长度的增加,平均奖励也随之提高,使得模型超越o1-preview。
以上成果均可表明,蒸馏+RL微调 可以让参数规模较小的模型同样获得o1级别的推理能力,未来趋势或许会是大模型的高效低成本应用,我们与大模型之间或许可以不再间隔无数个高端显卡的壁垒。
RL加持下的Aha moment降临
第二强在于,在R1的研究中有提到,他们观察到了Aha moment的降临,模型在训练过程中自行涌现出了多种解题方法,如"解数学题时写下步骤、自动检查每一步是否正确、解题中间如果意识到错误会中断思考并重新推导等"。这些能力都是模型自己摸索出来的,训练者并未进行干预。
这告诉我们:我们无需明确教导模型如何解决问题,只需提供正确的激励,它便能自主开发出高级的问题解决策略。RL 有潜力解锁人工智能的下一个智能水平,为未来更自主和自适应的模型铺平道路。
通过对DeepSeek-R1-Zero的RL训练结果的观察发现,DeepSeek-R1-Zero 的思考时间在整个训练过程中持续增长,这种增长不来自于外部调整,而是来自于模型内的本质发展。DeepSeek-R1-Zero通过利用在测试时计算(test-time computation)上的扩展(Scaling)自然地获得了解决越发复杂的推理任务的能力。
换句话说:随着RL训练,DeepSeek-R1-Zero自然而然地学会了使用更多的思考时间来解决复杂的推理任务。
而这种自我进化最显著的体现是,随着测试时计算的增加,复杂行为的涌现。
哪些复杂行为呢?比如,反思行为,模型重新审视和评估先前的步骤,探索解决问题的替代方法,而这些行为均为自发产生,而非显式编程而来,是模型与RL环境交互的结果。
以上发现,充分表明了RL训练方法之强大。
另外,在开源项目VLM-R1中将R1的RL思路应用到视觉领域后发现,RL训练得到的模型比起SFT训练的模型,其在领域外数据上的泛化能力明显更强,这也验证了他们的想法,RL是大模型自我进化的奥秘,是解锁下一个智能水平的钥匙。
有趣的是,DeepSeek团队早在DeepSeekMath中便提出了统一的学习范式,将SFT视为RL的特例——从理论角度看,SFT不过是期望模型"死记硬背"答案的一种特殊RL方法。

这一现象,谷歌也在他们的研究《SFT Memorizes,RL Generalizes:A Comparative Study of Foundation Model Post-training》中用论文标题“SFT Memorizes,RL Generalizes”直白地进行了总结,该研究设计了两个任务来评估SFT和RL的泛化能力,最终发现RL在规则和视觉领域的泛化能力优于SFT,能够学习到可迁移的原则,而SFT则倾向于记忆训练数据,而且SFT对于有效的RL训练是必要的,它能够稳定模型的输出格式,为RL训练提供支持。
成本优势,在AI infra上的厚积薄发
除了以上模型能力的强大,第三强在于其相较以OpenAI o1为首的一众推理模型无比低廉的训练成本。
他们仅以约600万美元的价格,训练出与OpenAI o1相当水准的模型,而OpenAI训练GPT-4的成本就要约6300万美元,更不要说o1,这意味着DeepSeek-R1仅用了不到十分之一的成本就达到了与其相抗衡的性能效果。在服务定价方面,DeepSeek的API成本每百万tokens输出只要16元(尽管如此还可以有545%的理论成本利润率…),而GPT o1则高达约420美元,相差26倍!这自然对于美国硅谷的投资人们和底层算力提供商英伟达一时间造成了巨大的打击,造成了AI泡沫的短暂性破裂,导致英伟达一天蒸发近2000亿美元,创下美股历史最大单日市值蒸发纪录。
它告诉我们,拥有一个顶尖能力的模型,并不是那些拥有海量显卡大公司的专属,显然是投入AI市场的一枚巨大炸弹。
当然,如此低的成本自然也归功于DeepSeek在AI infra上的持续探索与厚积薄发,通过DeepSeek的开源周可以看出,他们在 底层的推理加速、节点通信、算子优化、并行策略、分布式存储 层面均做了很多的工作,这些工作从宏观层面上看都是有利于 降低 训练/推理 成本,提高资源利用率、模型吞吐量的,由此可以看出他们一以贯之的发力方向。
而这也是他们一经出世可以对英伟达股价造成如此之大影响的原因,当然这也不过是市场的第一反应,推理成本降低的背后确实是显卡算力需求的降低,但随之而来的也是对AI市场需求的又一次强力刺激,并为AI部署推理市场带来了新的活力,最终来看是利好还是利空尚不得而知,毕竟像DeepSeek开源的DeepGEMM等优化框架仍然是基于英伟达的Hopper架构进行的优化,短期内AI领域仍将对N卡有较强的依赖。但从长远看,DeepSeek的创新对整个AI基础设施领域的发展具有重要启示意义。
总之,在AI infra上的极致优化所带来的低成本训练与推理,一直都是DeepSeek在持续探索的方向,也将是引领开源力压闭源的重要法宝。
DeepSeek-R1的出现能够给我们带来些什么?市场与行业是如何反应的?
B端
对企业用户而言,DeepSeek-R1的出现产生了多方面效应:
1.私有化部署需求显著膨胀:但可能一定程度上源于客户对跟进技术趋势的任务需要,而未必有明确的业务价值;
2.传统B端大模型应用场景受影响有限:对于意图识别、信息提取等常见的B端落地场景,R1由于 推理耗时较长、幻觉现象严重 等问题优势并不十分明显;
3.降低定制化门槛:R1自身的强大基础能力与较低成本,使得企业特定场景的AI定制变得更加经济可行;
4.重新激发创新探索:R1展示的成本降低与能力提升,促使企业重新评估AI应用策略,探索更多可能性;
C端
核心贡献在于C端继ChatGPT刚出世时的又一次全民AI普及,对市场需求的又一次强力刺激;
对普通用户和消费级应用,R1的影响更为直接:
1.重新点燃C端AI应用市场:众多网友们纷纷基于DeepSeek构建AI应用,其卓越的文学表达能力与独树一帜的创造力很容易引发广泛共鸣,从小红书等社交媒体上的话题度可见一斑;
2.使用门槛显著降低:"DeepSeek的提示词技巧,就是没有技巧",用户只需自然准确地表达需求,无需掌握复杂的提示词工程技巧,可以抛弃过往的结构化框架,将AI视为一个能力强大的员工,这种方法也大大降低了AI的使用门槛。——对于未来提示词工程是否会消亡预计会在另一篇文章《Way To Prompt(2)》中进行分析;
3.开源带来的高性能AI体验:对于普通用户而言,DeepSeek-R1的开源特性使得众多厂商均可接入该模型对外提供免费服务,实际上是变相为所有用户均提供了更为便捷的高性能AI体验,同时也意味着未来会有更多基于它的应用出现。
行业生态影响
DeepSeek-R1的出现对整个AI行业生态产生了深远影响:
1.重塑价格预期:打破了“高性能AI必然昂贵”的市场固有认知,迫使其他提供商重新考虑定价策略;
2.开源比肩闭源:以此为契机,终于表明开源模型在性能上可以比肩甚至超越闭源商业模型,也促使个别公司开始重新思考未来策略;
3.推动技术路线多元化:证明了强化学习在大模型训练中的关键价值,可能影响未来AI研究方向;
4.激发AI infra创新:让更多人见识到了AI infra上的技术积累所能带来的实际价值;
总的来说,DeepSeek-R1的出现不仅展示了中国AI技术的进步,也为全球AI市场带来了新的活力和可能性。它将继续推动AI技术在降低成本的同时提升性能的方向发展,为更广泛的用户群体带来先进的AI体验。
参考:
[1] DeepSeek-AI et al. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” ArXiv abs/2501.12948 (2025): n. pag.
[2] DeepSeek-AI et al. “DeepSeek-V3 Technical Report.” ArXiv abs/2412.19437 (2024): n. pag.
[3] Shao, Zhihong et al. “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.” ArXiv abs/2402.03300 (2024): n. pag.
[4] Chu, Tianzhe et al. “SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training.” ArXiv abs/2501.17161 (2025): n. pag.
[5] https://mloasisblog.com/blog/ML/deepseek-v3-r1-2
[6] https://zhuanlan.zhihu.com/p/649731916
[7] http://www.twistedwg.com/2018/05/30/MC-reject-sampling.html
[8] https://turningpointai.notion.site/the-multimodal-aha-moment-on-2b-model
[9]
[10]
[11]
AI 时代的分布式多模态数据处理实践
在AI多模态数据处理中,企业面临海量文本、图像及音频数据的高效处理需求,本地受限于单机性能,难以满足大规模分布式计算要求。本方案介绍了基于分布式计算框架 MaxFrame,依托 MaxCompute 的海量计算资源,对多模态数据进行分布式处理、模型离线推理。
点击阅读原文查看详情。