蚂蚁开源Ray Flow Insight,解决分布式AI系统调试难题。通过多维度可视化,让强化学习等复杂系统的内部运作更透明,助力开发者快速定位问题。
原文标题:AI开源框架:让分布式系统调试不再"黑盒"
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章中提到了Ray Flow Insight的规模限制,仅适用于Actors和Tasks实例数相对有限的应用场景,如果在actor数量非常多的情况下,有什么优化的思路吗?
3、Ray Flow Insight 目前主要针对Python应用,未来如果扩展到Java和C++,会面临哪些挑战?
原文内容
作为面向AI计算的开源框架,Ray 已在深度学习训练、大规模推理服务、强化学习以及AI数据处理等领域构建了丰富而成熟的技术生态。基于Ray构建的上层AI框架(如RayData、RayTrain、RayServe、AReaL、OpenRLHF、veRL等)正在成为AI研发的关键工具,尤其在后训练时代的强化学习场景中,这些框架为复杂的任务提供了高效、可扩展的分布式执行环境。
在蚂蚁内部,我们基于业务实践,不断深化对Ray的应用和优化,积累了丰富的分布式系统建设经验。这些实践中沉淀的技术能力会推动Ray生态在实际场景中的应用深度和广度。我们激活的AntRay开源社区,会始终保持与官方Ray版本强同步(即AntRay会紧随Ray官方社区版本而发布),后续也会以系列文章形式同步蚂蚁推向开源的新特性。本文将首先重点介绍:Ray Flow Insight —— 让分布式系统调试不再"黑盒"。
ant-ray仓库地址:https://github.com/antgroup/ant-ray
一、后训练时代:复杂强化学习系统"黑盒"困境
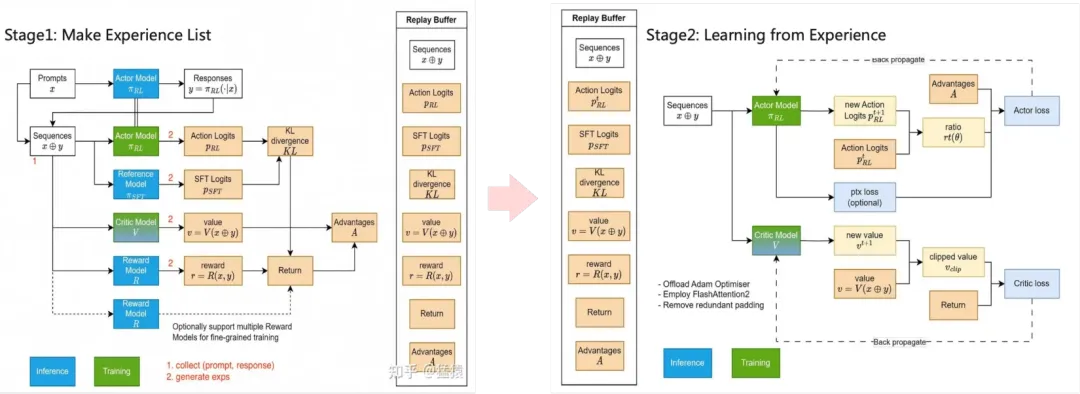
PPO算法两阶段流程: 图例来源参考资料[7]
局部视图下的可视性缺乏
性能瓶颈识别困难
资源利用率监控复杂
调试信息分散
分布式系统的日志和调试信息通常分散在多个节点上,收集和关联这些信息是一项耗时的工作。在强化学习系统中,这一问题更为突出,因为需要同时关注模型训练、环境交互、数据收集等多个方面的调试信息。缺乏集中式的调试视图,使得问题排查变得异常困难。
后训练时代的特殊挑战
后训练时代的强化学习正面临着日益复杂的系统需求,这些需求虽然推动了Ray分布式框架的广泛应用,但在系统全方位洞察方面仍面临诸多挑战:
-
多角色资源编排可视化:强化学习系统中通常存在多种具有不同功能的角色组件,如Actor、Critic、Reward、Reference、ReplayBuffer等。Ray虽提供了灵活的资源管理和调度策略(如PlacementGroup、NodeAffinity)来优化这些角色的分布部署,但缺乏直观工具来可视化这些复杂编排策略及其性能影响,开发者往往只能依靠经验而非数据驱动的方式来进行资源优化决策。
-
混合并行策略的协同理解:为应对大模型训练,现代系统同时采用专家并行、数据并行、模型并行、流水线并行等多维并行策略。这些并行维度在Ray分布式环境中交织形成复杂的执行网络,开发者迫切需要工具来可视化和理解这些并行策略的协同效果与潜在冲突。
-
分布式反馈循环的依赖追踪:RLHF系统的核心在于其复杂的反馈循环机制,从人类偏好到奖励建模,再到策略优化,形成了多层嵌套的依赖网络。这些依赖在Ray分布式环境中分散执行,理解它们的时序关系和数据流向对系统优化至关重要,但现有工具提供的追踪能力有限。
-
分布式卡点分析:在复杂的强化学习系统中,执行卡点可能出现在任何节点,且常因组件间的跨节点依赖而难以追踪。不同于单机环境下可直接使用pstack等工具查看进程堆栈,分布式环境中的卡点诊断需要开发者手动连接各节点逐一检查,效率低下。
小结:虽然Ray Dashboard提供了基础集群监控功能,但在应对前述分布式强化学习系统的复杂挑战时仍显局限。Ray生态系统虽为强化学习算法提供了灵活易用的分布式执行环境,但缺乏能够深度透视系统内部结构、数据流向与资源分配的专业分析工具,导致开发者在优化过程中常依赖经验推断而非数据驱动决策。
二、Ray的分布式编程模型:Actor、Task与Object
在深入探讨Ray Flow Insight之前,我们需要先了解Ray框架的核心分布式编程模型。Ray通过三种基本原语(Actor、Task、Object)为开发者提供了构建复杂分布式系统的基础,这些概念是理解Ray Flow Insight设计理念的关键。
RAY的三大核心编程原语
Task:无状态分布式函数
@ray.remote
def process_data(data_ref):
data = ray.get(data_ref)
result = do_process(data)
return result
# 创建一个Normal Task处理数据并
result_ref = process_data.remote(some_data)
# 获取执行结果
result = ray.get(result_ref)
-
无状态性:每次调用都是独立的,不保留前一次执行的状态
-
并行执行:多个Task可以在集群中并行运行
-
自动调度:Ray调度器负责将Task分配到合适的节点执行
Actor:有状态分布式对象
@ray.remote class DataProcessor: def __init__(self): self.state = {} # 内部状态def process(self, data):
# 处理数据并更新内部状态
self.state[data.id] = data
return self.state创建Actor实例
processor = DataProcessor.remote()
调用Actor方法
future = processor.process.remote(data)
获取处理结果
state = ray.get(future)
Actor的关键特性:
-
状态保持:Actor可以在方法调用之间维护内部状态
-
串行执行:Actor的方法默认是串行执行的,确保状态一致性
-
资源绑定:Actor实例绑定到特定节点,避免状态转移开销
Object:分布式共享数据
@ray.remote def create_data(): return large_dataset # 返回Ray Object引用@ray.remote
def process_data(data_ref):
# data_ref是对Ray Object的引用,获取实际数据
data = ray.get(data_ref)
return processed_result
#生成一个大的数据对象引用,对象实例存放在Object Store中
data_ref = create_data.remote()获取处理结果
result_ref = process_data.remote(data_ref)
Ray Object的特点:
-
透明序列化:自动处理Python对象的序列化和反序列化
-
分布式对象存储:数据存储在Ray的分布式内存中,可跨节点共享
-
引用传递:通过引用而非数据副本传递,减少数据移动开销
-
惰性求值:只有在需要时才会实际获取数据
分布式系统的交互复杂性
-
组件交互网络:数百甚至数千个Actor和Task之间形成复杂的调用关系网络
-
多层依赖:Actor可能依赖其他Actor的输出,形成多层嵌套的依赖链
-
资源分配:不同的Actor和Task可能分布在不同节点上,资源分配变得复杂
-
数据流向:大量Ray Object在节点间流动,形成复杂的数据流网络
分布式编程原语可视化
-
原语可视化:
-
将Actor实例转化为可视化节点,展示其内部状态和方法
-
将Task调用转化为可视化节点,展示其执行状态和依赖关系
-
将Object引用转化为数据流连接,展示数据在组件间的流动
-
多维度透视:
-
逻辑视图:抽象化Actor和Task的调用关系,展示系统拓扑结构
-
物理视图:展示Actor和Task在物理节点上的分布,反映资源使用情况
-
调用栈视图:提供类似传统调试器的调用堆栈,但跨越分布式边界
-
火焰图视图:展示系统性能热点,帮助识别瓶颈
-
零侵入设计:
-
不修改用户代码即可自动收集系统运行信息
-
基于Ray内部机制捕获Actor、Task和Object的交互数据
-
提供简单API接口支持高级定制需求(如上下文标记)
三、Ray Flow Insight:分布式应用可视化分析工具
Ray Flow Insight 是蚂蚁集团专为解决Ray分布式应用"黑盒"问题设计的可视化分析工具,为复杂分布式系统提供多维度透视能力,它采用"零侵入式"设计理念,大部分功能无需修改用户代码即可自动收集并可视化系统运行状态,同时提供灵活API接口支持高级定制需求。
Ray Flow Insight 通过四个互补的可视化视图,从不同角度解析分布式系统特性:
-
逻辑视图(Logical View):展示组件间的调用关系和数据依赖,帮助理解系统拓扑结构
-
物理视图(Physical View):展示组件在节点间的分布和资源使用情况,帮助优化部署策略
-
分布式调用栈(Distributed Stack):提供跨节点的调用链路追踪,快速定位执行卡点
-
分布式火焰图(Distributed Flame Graph):可视化系统性能热点分布,指导精准优化
这些功能相互配合,为开发者提供了从宏观到微观、从静态到动态的全方位系统洞察能力,使分布式强化学习系统的开发和调优从"盲目摸索"转变为"数据驱动决策"。
接下来我们以一个基于Ray构建的分布式应用为例,详细介绍Ray Flow Insight的核心功能模块:
import ray import random import timeray.init(address=“auto”)
@ray.remote
class Worker:
“”"
Create a tree of workers in which each worker spawns multiple children.
“”"
def init(self, depth, is_bottleneck=False):
# Whether this worker should mock delay
self.is_bottleneck = is_bottleneck
# Current depth in the worker tree (root = highest number)
self.depth = depth
# List to store child worker actor references
self.children =# Create child workers if we’re not at a leaf node (depth > 0)
if self.depth > 0:
# Create 1-2 children randomly for each worker
for _ in range(random.randint(1, 2)):
# Recursively create child workers with decreased depth
# Randomly decide if the child will be a bottleneck
self.children.append(
Worker.remote(
depth=self.depth - 1,
is_bottleneck=random.randint(0, 1) == 1
)
)def process(self):
“”"
Process work and delegate to child workers.
Bottleneck workers at leaf nodes introduce significant delays.
“”"
# List to collect all async task references from children
futures =# For each child worker
for child in self.children:
# Submit 10 process tasks to each child
for _ in range(10):
# If this is a bottleneck worker at a leaf node (or just above),
# introduce a significant delay (20 seconds)
if self.is_bottleneck and self.depth - 1 <= 0:
time.sleep(20.0)# Standard processing time for all workers (2 seconds)
time.sleep(2)# Submit the process task to the child worker
# This creates a nested tree of task calls
futures.append(child.process.remote())# Wait for all child tasks to complete before returning
# This ensures the full tree of tasks must complete
ray.get(futures)Create the root worker with depth 5
This will create a tree of workers with maximum depth of 5
worker = Worker.remote(depth=5, is_bottleneck=False)
Start processing and wait for the entire tree to complete
ray.get(worker.process.remote())
逻辑视图
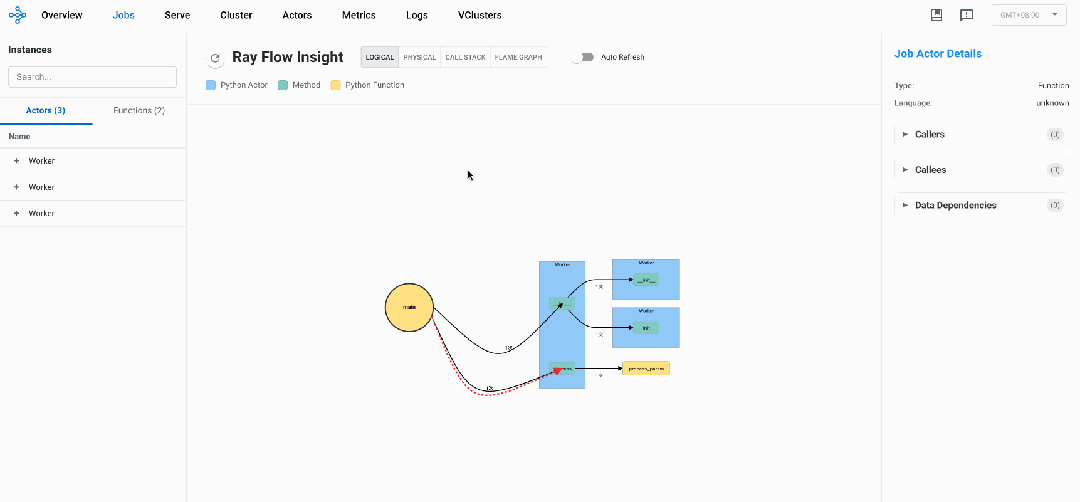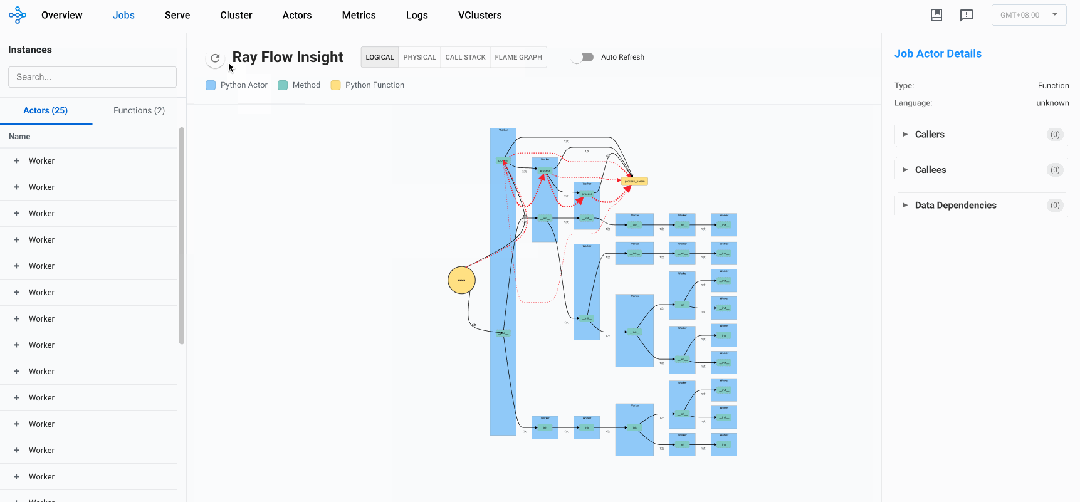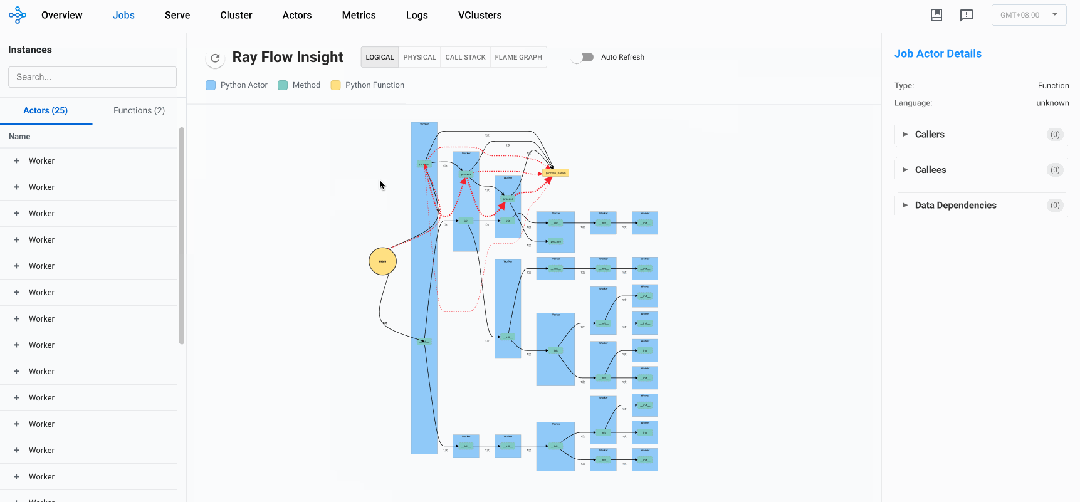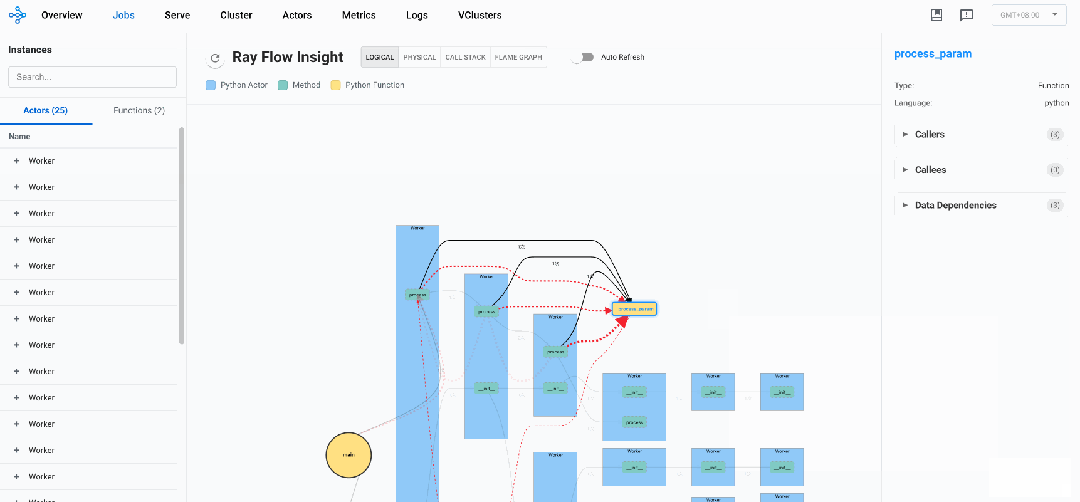
逻辑视图说明:
-
黄色圆形框:代表Driver入口方法
-
黄色矩形框:代表Ray Normal Task
-
蓝色矩形框:代表Ray Actor实例
-
绿色矩形框:代表Ray Actor Method方法
-
黑色实线边:代表任务控制流,两端分别连着 Caller 和 Callee,箭头代表调用关系,线上数字代表调用次数
-
红色虚线边:代表数据流,可以是方法的入参,也可以是任务的返回值(目前仅记录含Ray Object的数据),粗细代表最后一次数据传输速率(选中后右侧可观测详细信息),箭头代表流向
通过Ray Flow Insight的逻辑视图,研发人员能够直观把握整个分布式系统的组件拓扑结构与交互模式,实现对复杂分布式系统的全局理解。这种可视化不仅展现了静态的组件间关系,更揭示了动态的控制流和数据流的流转路径,使开发者能够精确定位通信瓶颈、识别数据依赖热点、发现冗余调用模式,并洞察组件间的负载分布不均衡现象。
物理视图
与逻辑视图展示Actors及Normal Tasks之间调用关系不同的是,物理视图主要用于展示Ray作业内Actors及NormalTasks在不同节点上的分布及资源使用情况,帮助研发人员快速定位热点实例及节点。
下图是通过上述代码实力渲染出的物理视图:
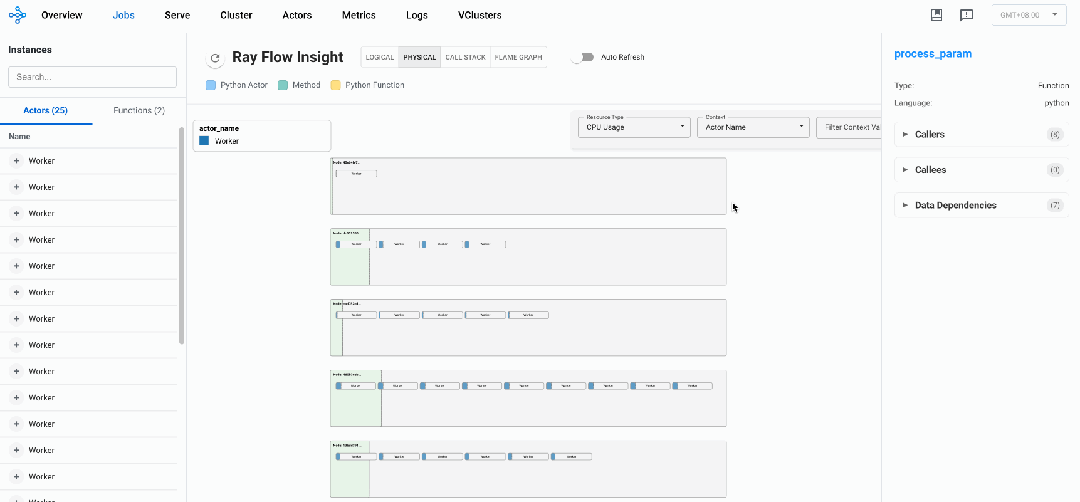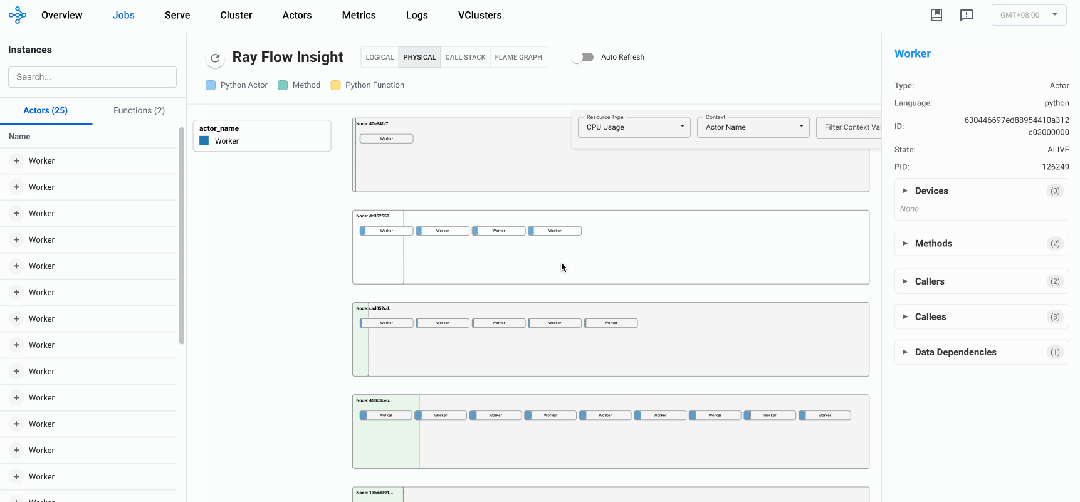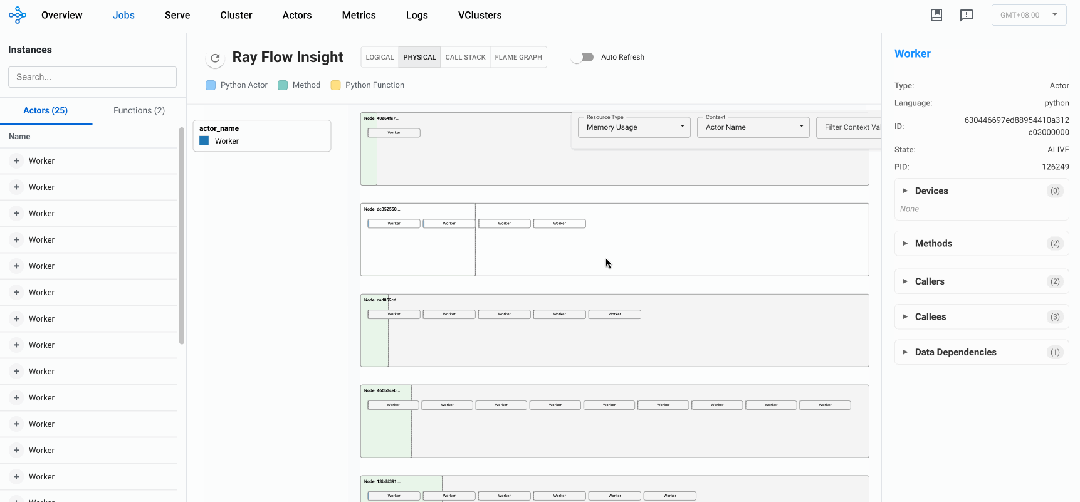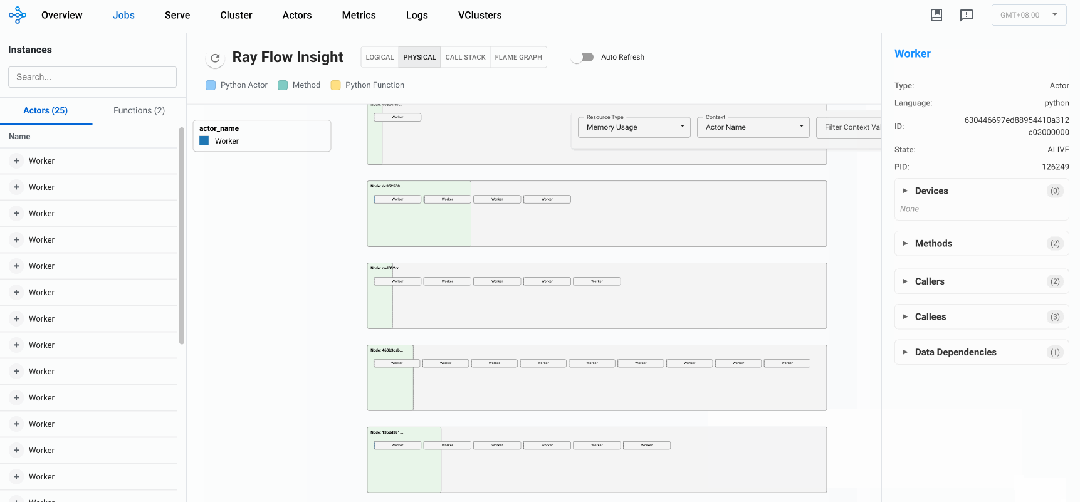
物理视图所有元素均采用矩形框表示,每一个矩形框都采用「血槽」填充的方式表示其资源用量:
-
Ray Node:单个Ray节点,采用浅绿色血槽表示资源用量
-
Placement Group:通过Ray接口预留的资源组,采用淡蓝色血槽表示资源用量,可以装载Actors或者Tasks
-
Actor:Ray的Actor实例,内层矩形框,采用Actor Name随机颜色血槽表示其真实资源用量
-
Normal Task:物理视图暂未支持Normal Task(开发中)
-
Resource Usage:当前默认提供CPU、MEM、GPU资源使用情况透出,选择不同资源,对应血槽也会改变
-
Actor Context:需要用户显示地使用insight接口给实例注册label,物理视图可以根据label进行过滤筛选(如强化场景显示地给Actor注册EP、PP、DP并行策略对应的RANK ID)
分布式火焰图
火焰图(Flame Graph)是单机性能剖析的重要工具,通过可视化调用栈的执行时间分布,帮助开发者直观识别程序中的性能热点。然而,在Ray分布式环境中,性能问题往往分散在多个节点和组件之间,传统火焰图无法展现这种跨节点的性能特征。
Ray Flow Insight提供的分布式火焰图(Distributed Flame Graph)能够自动收集和汇总单个Ray作业的全生命周期所有组件的执行时间数据,构建一个覆盖全系统的统一火焰图,使开发者能够一目了然地看到分布式组件调用关系以及各环节耗时情况,进而分析整个分布式系统中的性能瓶颈。
同样,针对上述代码示例,从FlameGraph视图我们可以观察到其中某个process执行时间timeline为26.24s,占了绝大多数执行时间。
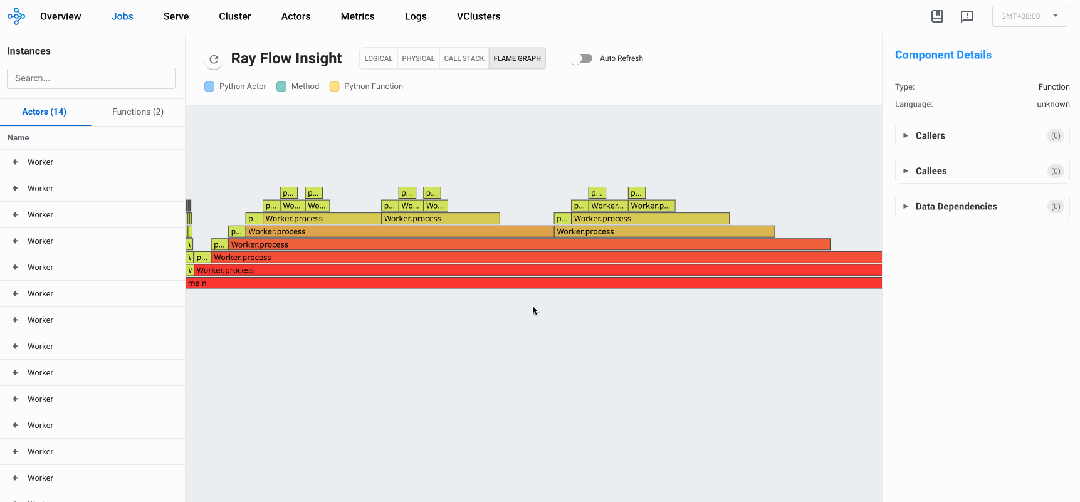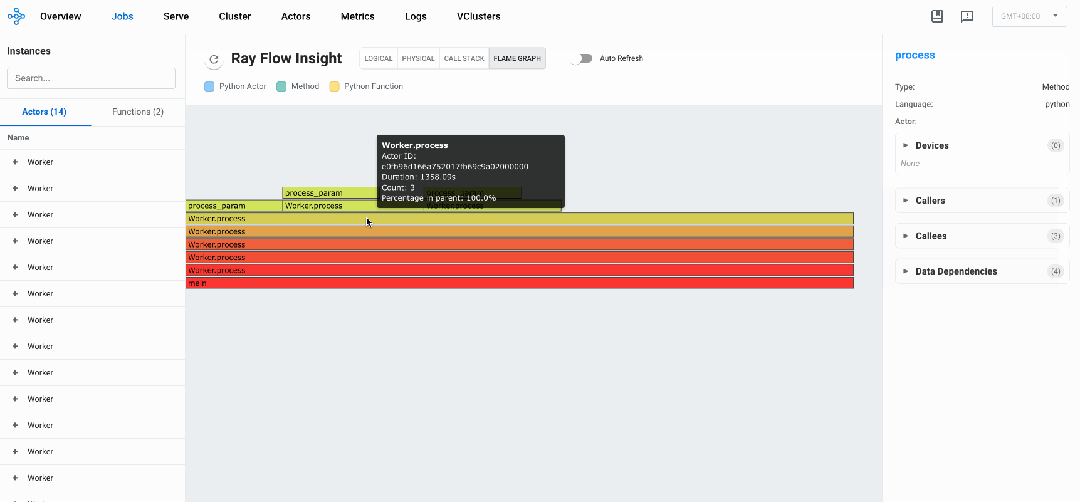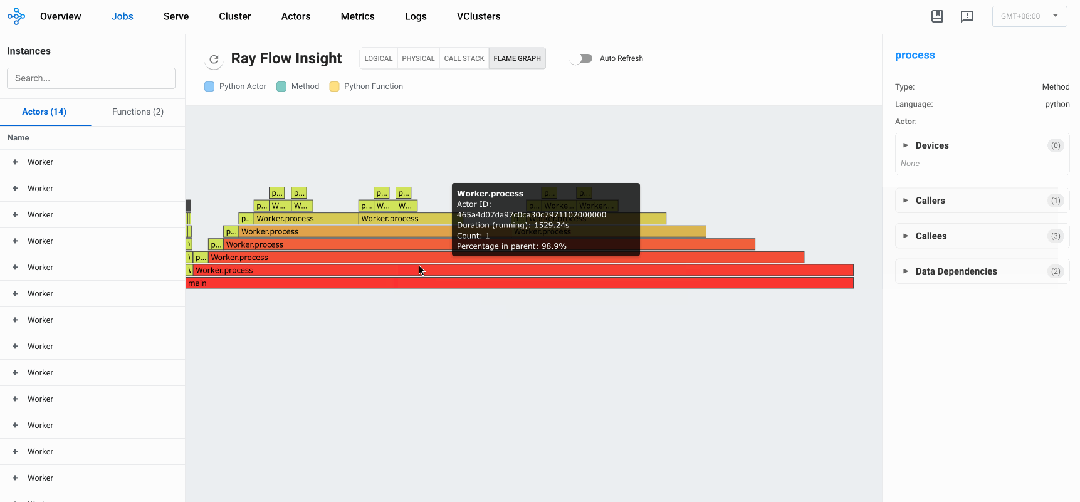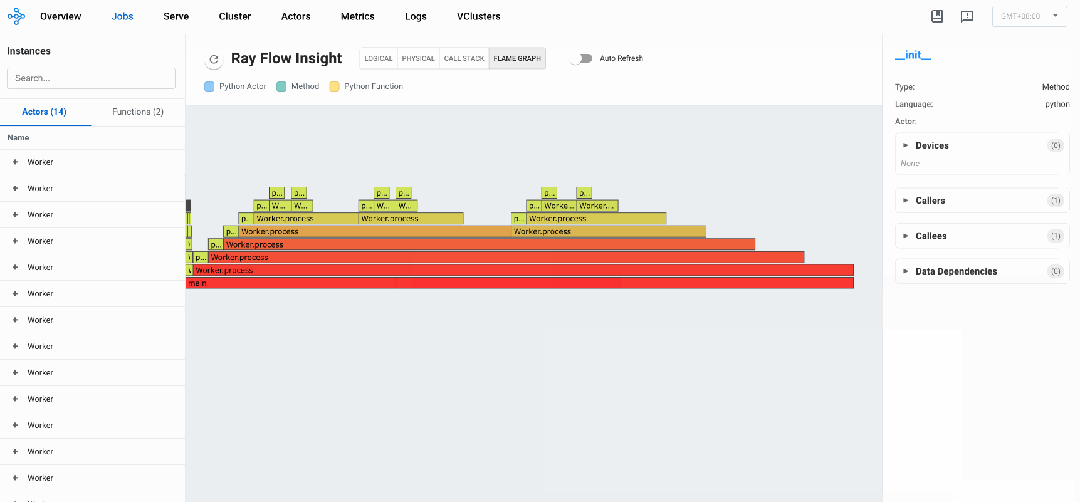
分布式调用栈
在单机环境中,当应用程序出现卡顿或死锁时,开发者通常会使用pstack等工具打印进程的调用栈信息,快速定位问题所在。然而,在Ray分布式系统中,特别是复杂的强化学习应用场景,问题排查变得异常困难。当系统中某个组件卡住时,传统方法需要开发者逐一登录每个节点,挨个检查进程状态,不仅效率低下,更难以发现跨节点交互导致的复杂问题。
Ray Flow Insight提供的DStack(Distributed Stack),能够自动收集并可视化整个Ray集群中所有Actor和Task的调用关系,呈现一个统一的、跨节点的"调用栈视图",让开发者能够:
-
无感接入:无需用户主动注入,只需使用ray api native方式编写分布式程序
-
一览全局:在单一界面中查看整个分布式系统的调用栈状态
-
追踪依赖:识别组件间的调用依赖关系,发现潜在的死锁或性能瓶颈
-
定位阻塞:快速定位哪些组件被阻塞,以及它们被阻塞的原因
针对上述示例代码的运行过程中的DStack视图如下:
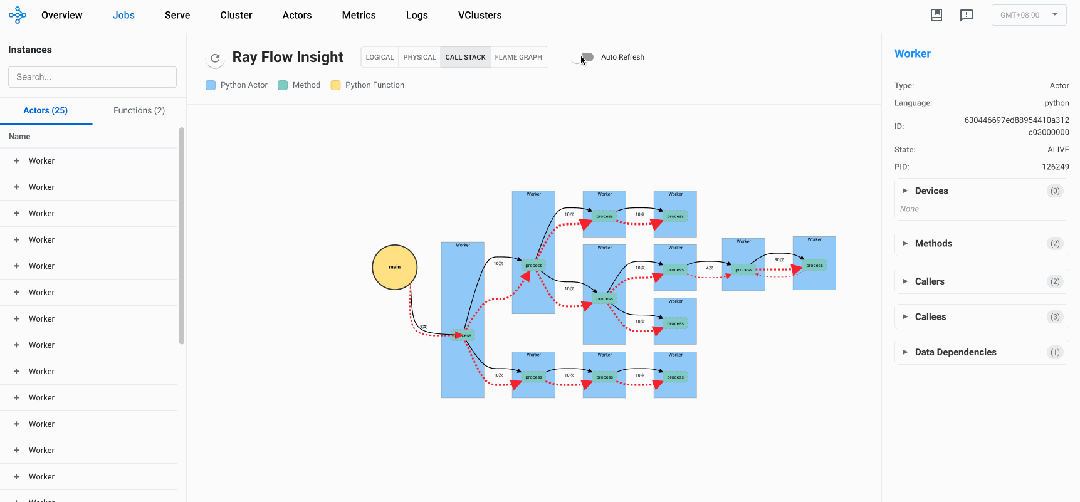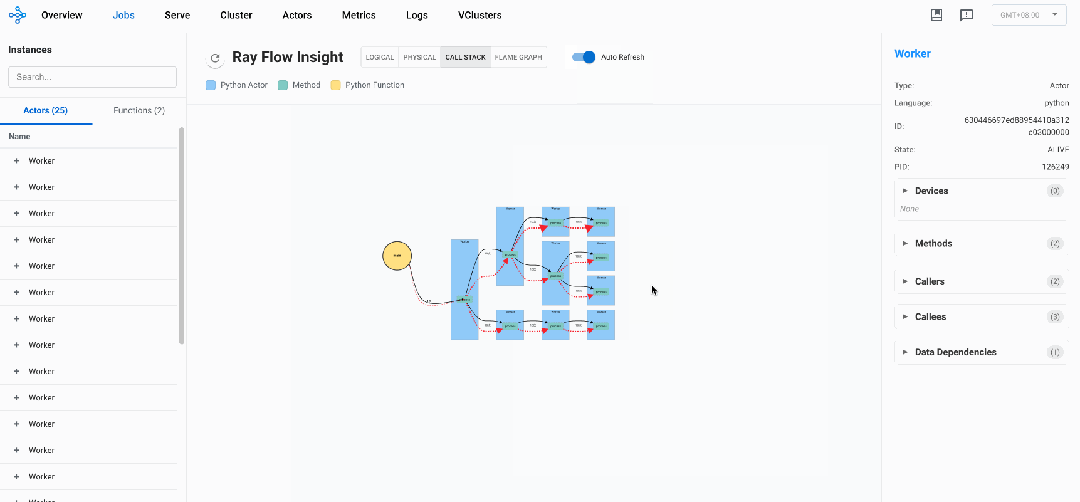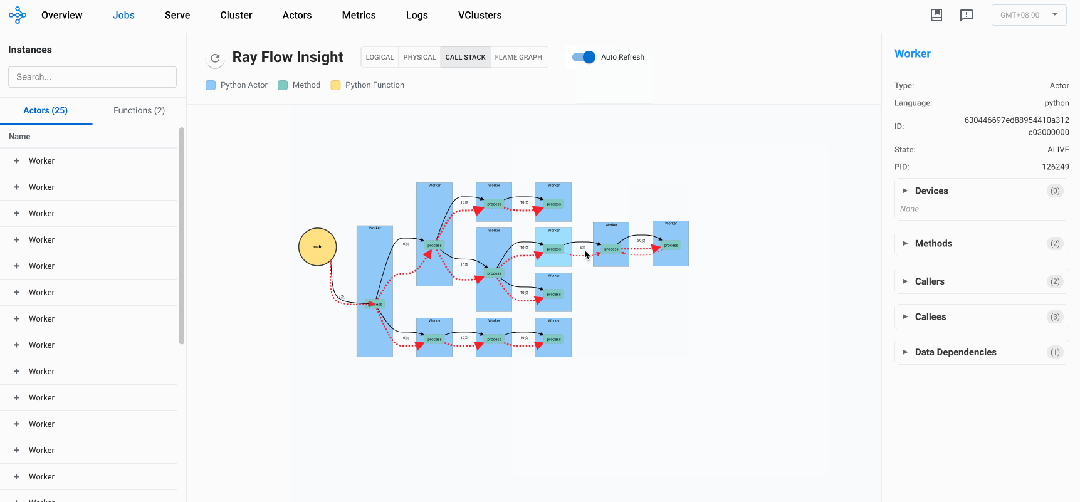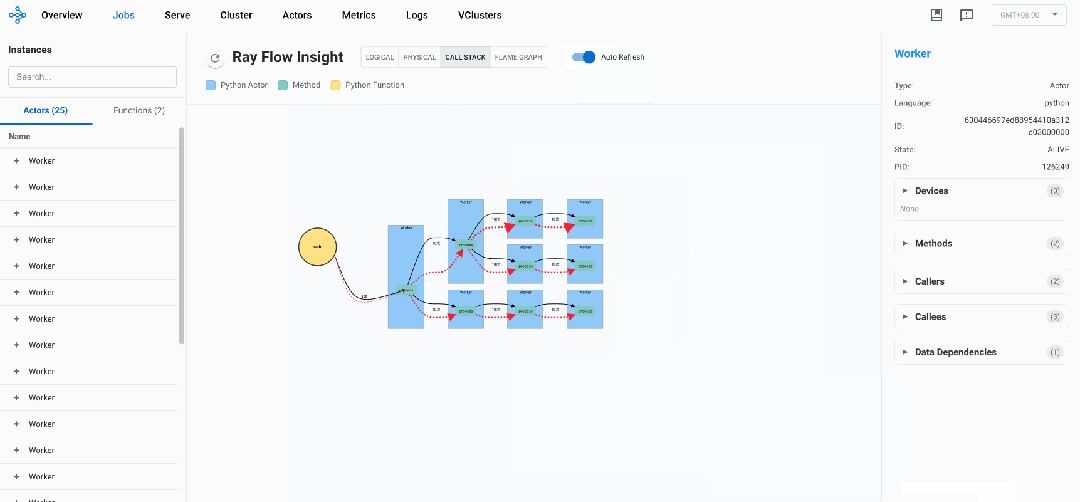
在DStack视图中,可以认定那些调用次数长期不变的节点为卡钝节点,以此可以定位系统瓶颈,识别潜在的问题。
实例列表
整个面板的左侧是instances列表,它包含了所有的Actor和Normal Task,提供了搜索和定位功能。
-
搜索:在四种视图下,当我们搜索某个关键字,对应的元素会在视图中高亮显示出来 ,其他不匹配的元素则会隐藏/透明显示。
-
定位:在逻辑视图和DStack视图下,当我们点击某一个元素(Actor,Normal Task或者Method)时,会自动定位并放大图中的特定元素。
组件详情
整个面板的右侧是Component Details,它包含了具体元素的具体信息,在每个视图中,当我们点击不同元素,右侧视图会显示不同信息:
-
Actor:显示Actor ID、PID、Devices、Methods、Caller、Callee及数据依赖等信息
-
Method:显示对应的Actor、Caller、Callee以及数据依赖等信息
-
Normal Task:显示Caller、Callee以及数据依赖等信息
适用场景及局限性
规模限制:目前Ray Flow Insight会收集所有Actors和Tasks实例的调用及数据流转关系,所以目前仅适用于Actors和Tasks实例数相对有限的应用场景,如果基于Ray构建的应用,存在不断创建和销毁Actor的情况,随着时间的推移,会导致Flow Insight的渲染压力较大,影响Dashboard的稳定性。
语言限制:当前Release的Flow Insight版本仅支持Python应用的渲染,Java和C++待支持
四、实战案例:AReaL、OpenRLHF与veRL强化学习框架Profiling
为了展示Ray Flow Insight在实际应用中的能力,我们以蚂蚁和清华大学联合开源的强化学习框架AReaL以及另外两个业界熟知的强化学习框架OpenRLHF和veRL为例,详细介绍工具的使用方法和实际效果。
安装与配置
我们在ant-ray的2.44.1.1版本中正式Release了Ray Flow Insight功能,只需在启动Ray集群前设置相应的环境变量即可启用Ray Flow Insight功能。
# Using --target and setting PYTHONPATH is to solve the package conflict problem
# caused by relying on both ant-ray and ray. For example, if the user relies on
# ant-ray and vllm (which relies on ray) at the same time
pip install ant-ray==2.44.1.1 --target /home/admin/ant-ray
export PYTHONPATH=/home/admin/ant-ray:$PYTHONPATH
# Enable Ray Flow Insight
export RAY_FLOW_INSIGHT=1
# For head node
ray start --head xxx
# For work node
# ray start --address=xxx
AReaL框架案例分析
AReaL是蚂蚁技术研究院和清华大学联合发布的开源强化学习系统,基于SGLang推理引擎,以高效率高稳定性为特点。在最新的 AReaL v0.2 版本 AReaL-boba 中,其 7B 模型数学推理分数刷新同尺寸模型 AIME 分数纪录,并且仅仅使用 200 条数据复刻 QwQ-32B,以不到 200 美金成本实现最强推理训练效果。
详见: 200美金,人人可手搓QwQ,清华、蚂蚁开源极速RL框架AReaL-boba
https://zhuanlan.zhihu.com/p/1889988181006467307
在蚂蚁集团的AI基础设施生态中,AReaL强化学习框架聚焦于大模型强化学习训练的高效实现和成本降低,Ray聚焦于分布式及AI计算的异构资源管理及任务调度协调,高效的强化学习系统与灵活的AI计算框架,相互协同共同支撑强化学习相关业务,旨在降低后训练时代技术门槛。
下面简单介绍我们基于AReaL开源的数据集和7B模型训练脚本,采用双节点16H800计算卡进行测试案例分析。
测试环境
-
算法:使用veRL框架执行GRPO算法
-
节点数:2 个节点,共16张H800计算卡
-
BaseModel:qwen2.5 7B
-
Rollout:SGLang
-
精度:FF16
逻辑视图: AReaL系统透视
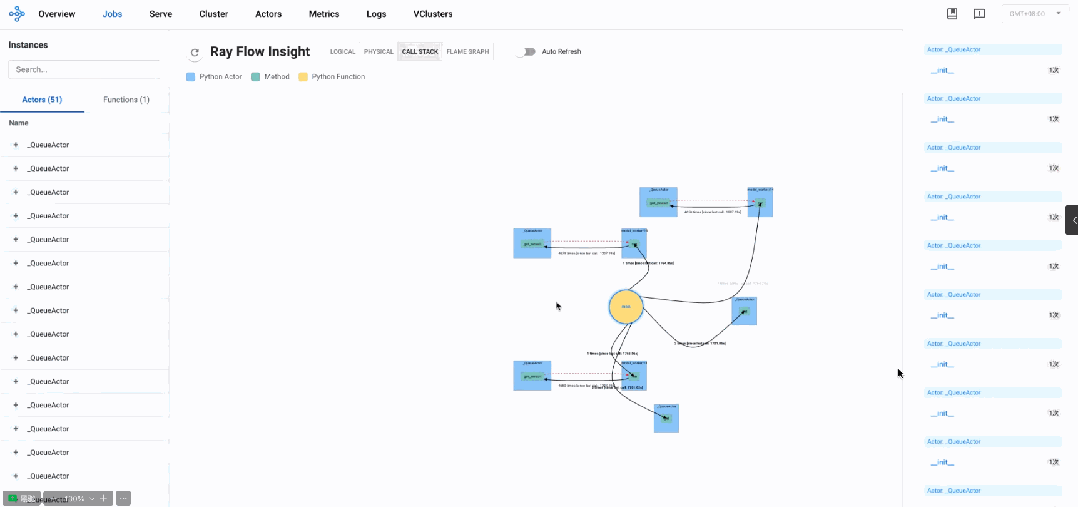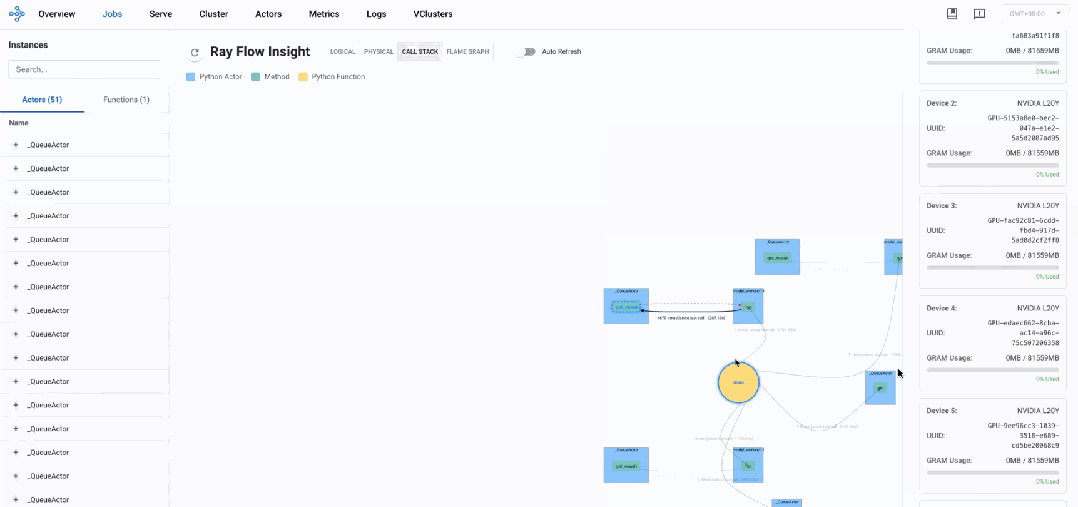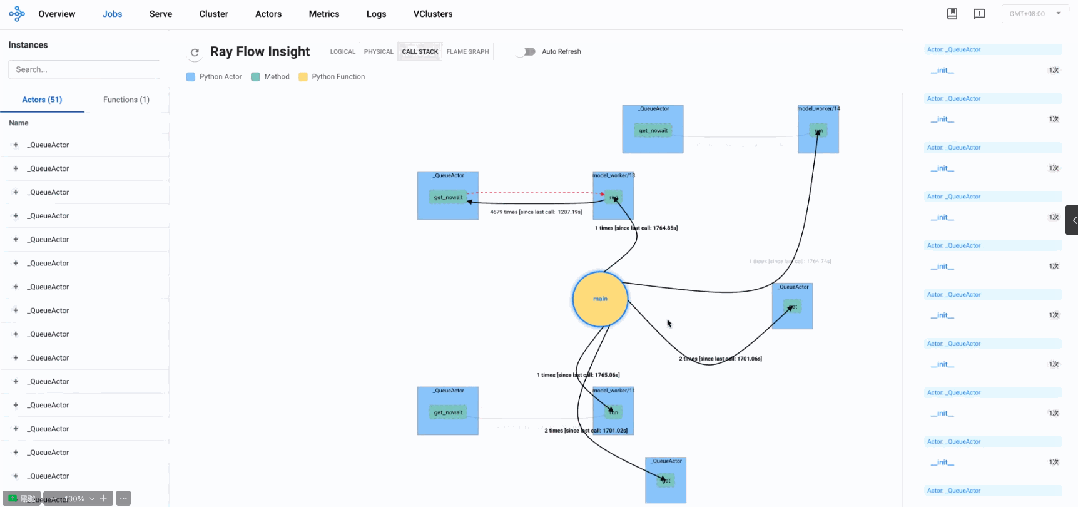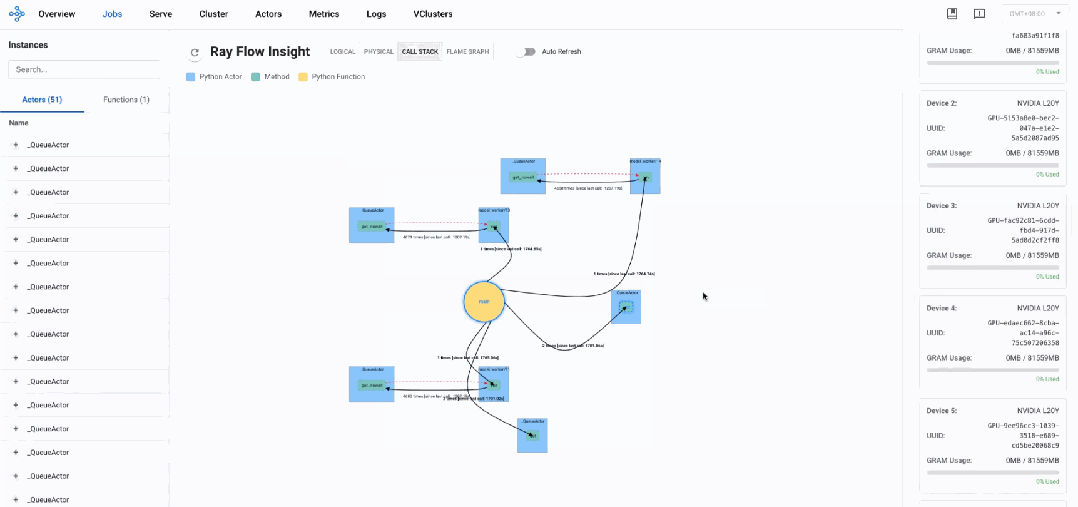
通过逻辑视图分析发现,AReaL系统主要由多个_QueueActor、model_worker以及master_worker组成。整体呈现出典型的生产者-消费者架构模式,通过队列进行通信和任务分发。
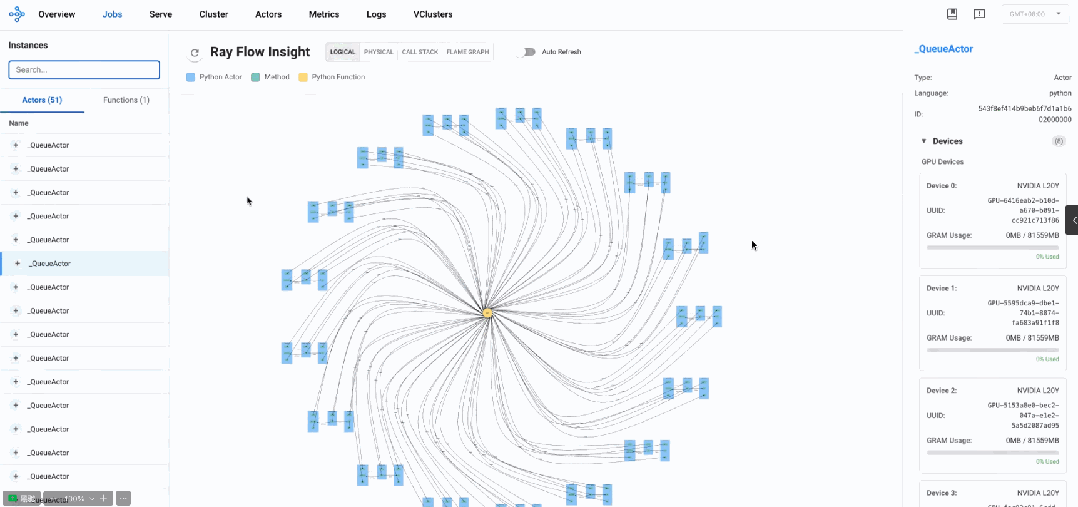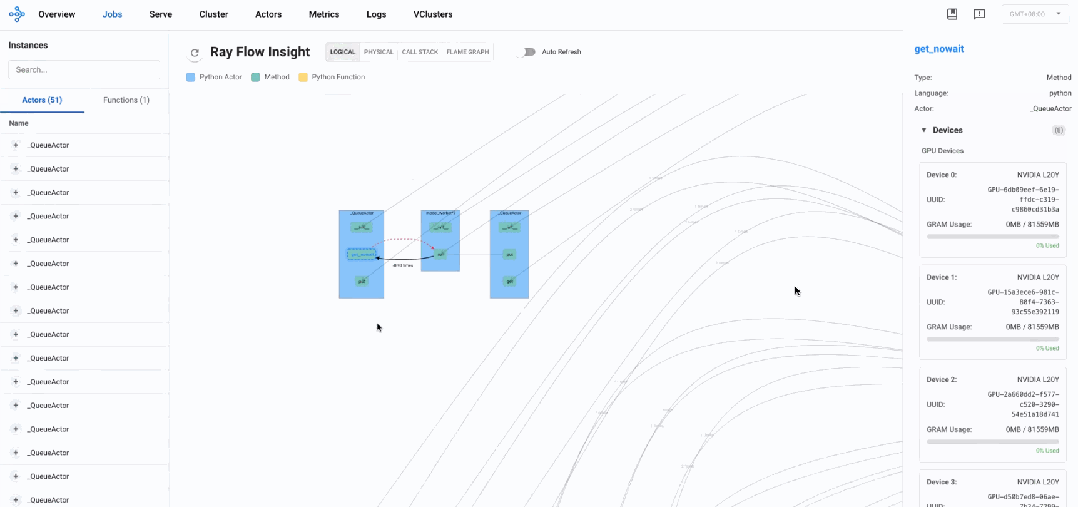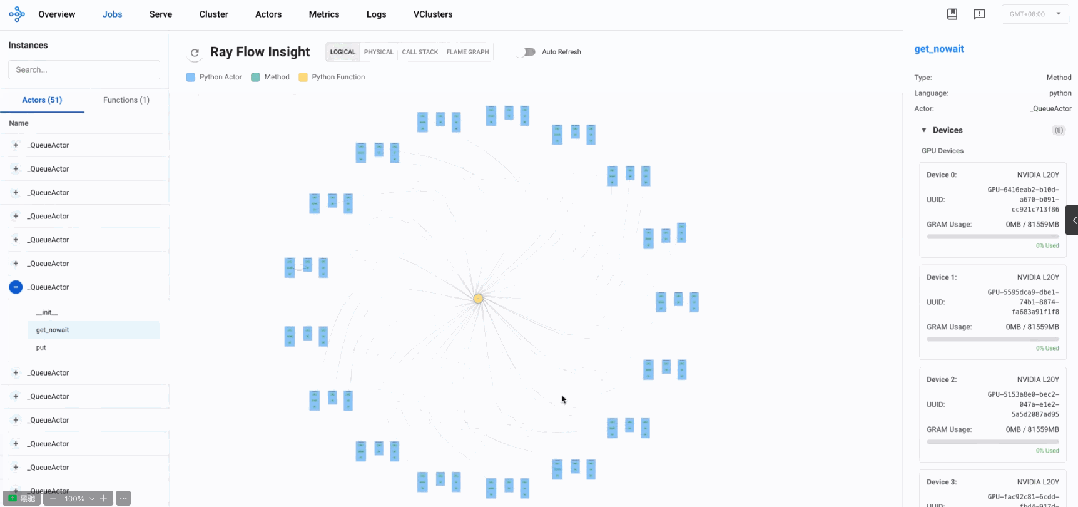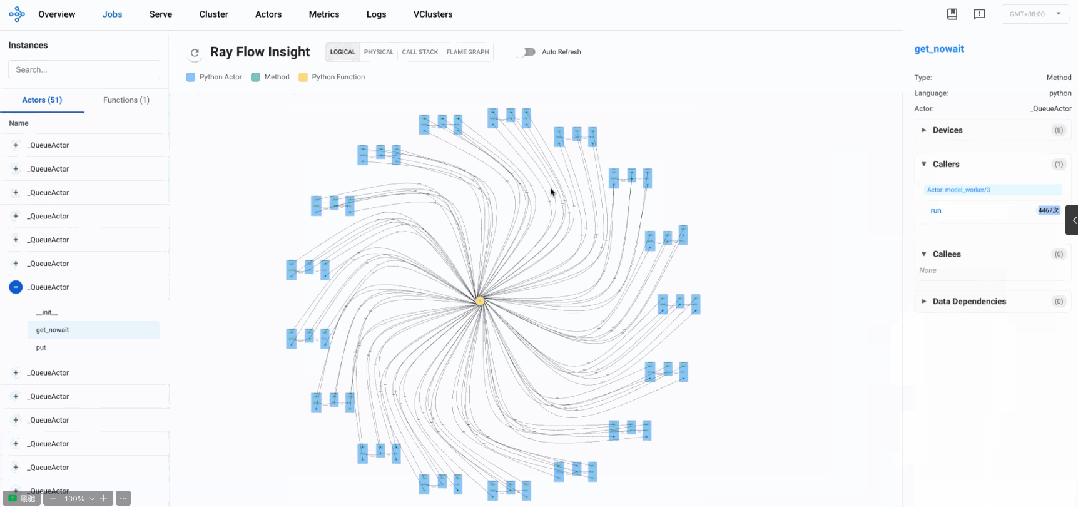
架构透视
-
分布式Actor模型架构
-
Actor组件设计:基于Ray Actor模型构建,由多个QueueActor和ModelWorker组成
-
主从协调模式:主控工作器(MasterWorker)负责协调和调度其他ModelWorker
-
生产者-消费者工作模式
-
队列通信机制:通过队列实现组件间任务分发和结果返回
-
非阻塞设计:大量使用
get_nowait非阻塞调用进行轮询检查 -
轮询操作模式:初始化后以短轮询操作为主要工作模式
-
异步通信架构
-
批处理特性:数据以批处理方式在组件间传递
-
短消息交互:组件间传递小型数据包,所有数据流的大小完全相同(0.00005436 MB),平均传输时间约0.0038秒
-
异步结果返回:任务完成后结果通过队列异步返回
主要组件分析

物理视图: 资源分配与使用观测
通过物理视图,很容易观测到系统部署在两个物理节点上,每个节点配备8张NVIDIA L20Y GPU(每张约80GB显存),64核CPU以及约750GB的内存。

资源分配状态
-
节点1:CPU使用率约1.5%,负载较轻
-
节点2:CPU使用率约9.9%,负载适中
-
节点1:19.7%(使用约159GB,剩余约646GB)
-
节点2:5.6%(使用约45GB,剩余约760GB)
-
节点1:8张GPU分配给了
model_worker(8~15) -
节点2:6张GPU分配给了
model_worker(1,3-7),总体比较活跃,有2张GPU(0,2)处于空闲状态
分布式火焰图: 瓶颈分析
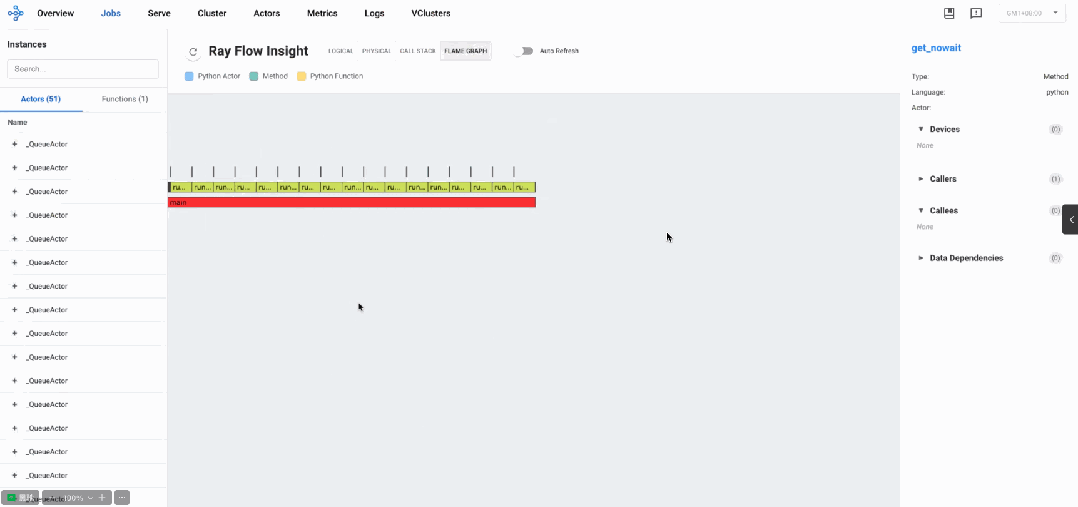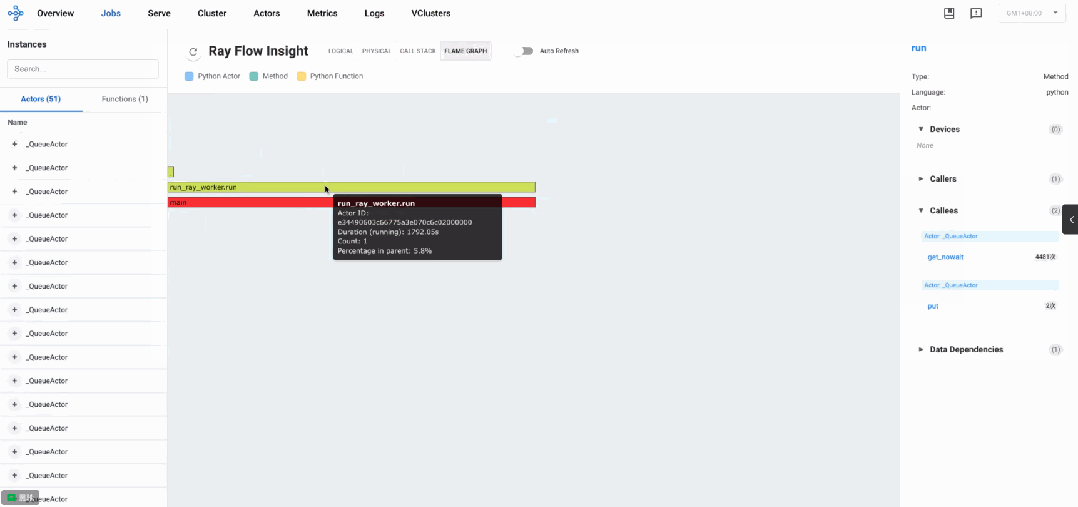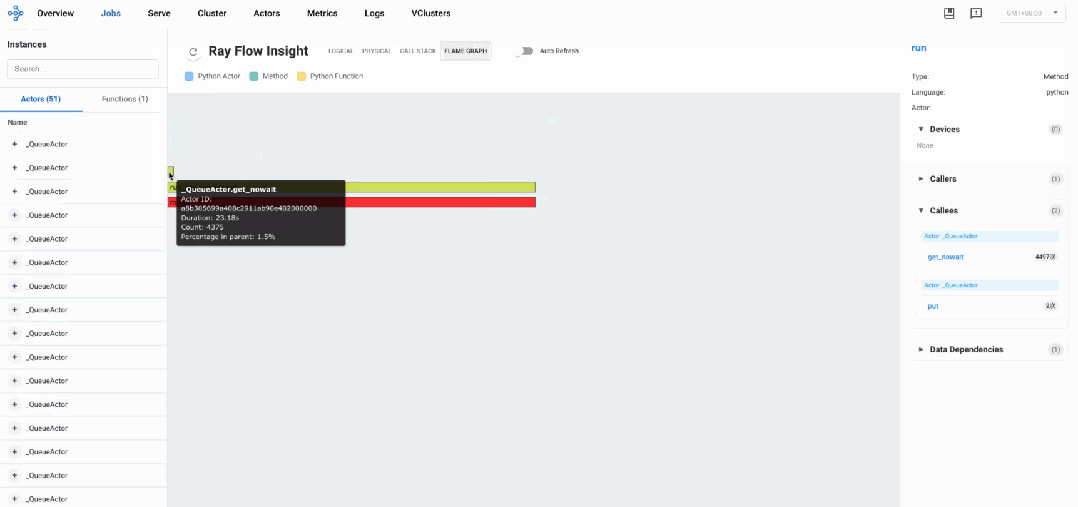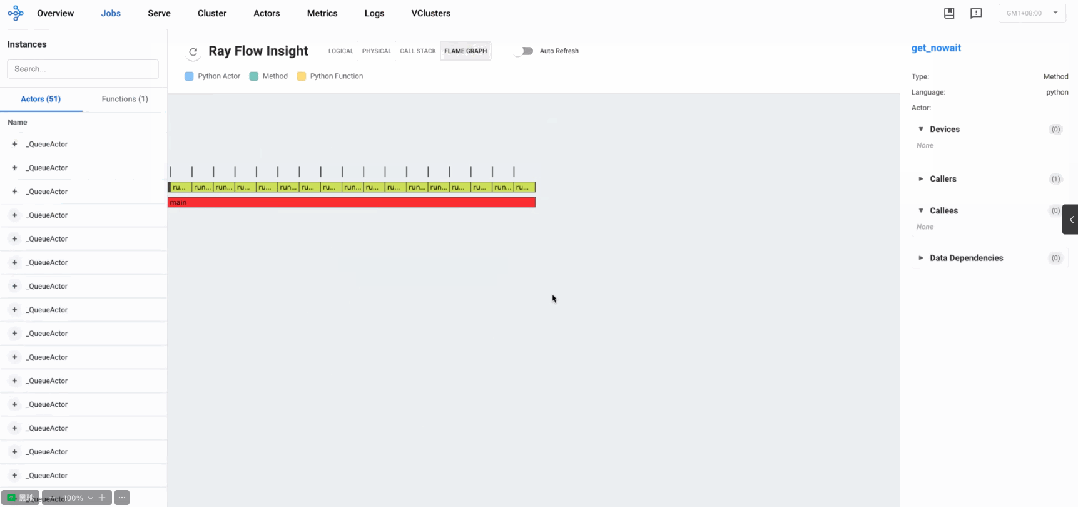
火焰图数据显示系统以初始化阶段开始,随后进入大量轮询操作模式。主要调用模式如下:
-
以
get_nowait方法调用为主导(占总调用次数的95%以上) -
每个model_worker执行大量轮询操作,每秒数百次
get_nowait调用 -
put和get方法调用相对较少,通常每个组件仅2-3次
分布式调用栈
从当前调用栈可以看出正在处于get_nowait轮询阶段,调用总次数在4k多,由此可以看出是高频短轮询。
veRL框架案例分析
veRL是字节开源的强化学习框架,在我们的实验中,我们启动了一个单机8卡的veRL作业,并使用Ray Flow Insight进行可视化分析。
测试环境
-
算法:使用veRL框架执行GRPO算法
-
节点数:1 个节点,8张A100计算卡
-
BaseModel:DeepSeek-Coder-V2-Lite-Instruct
-
Rollout:采用VLLM(实例数:2,TP为4)
-
精度:BF16
为了区分不同的Actor角色,我们修改了部分veRL的代码(single_controller/ray/base.py):
for key, user_defined_cls in cls_dict.items(): user_defined_cls = _unwrap_ray_remote(user_defined_cls) _bind_workers_method_to_parent(WorkerDict, key, user_defined_cls) # NOTE:Modify the cls name to make the Ray Actor more clear. WorkerDict.__name__= user_defined_cls.__name__
逻辑视图: veRL系统透视
在逻辑视图中,我们可以看到2类Ray Actor: register_center、ActorRolloutRefWorker,2类Normal Task:main_task、bundle_reservation_check_fun,这些都是veRL框架基于Ray的API进行控制面的一些操作。
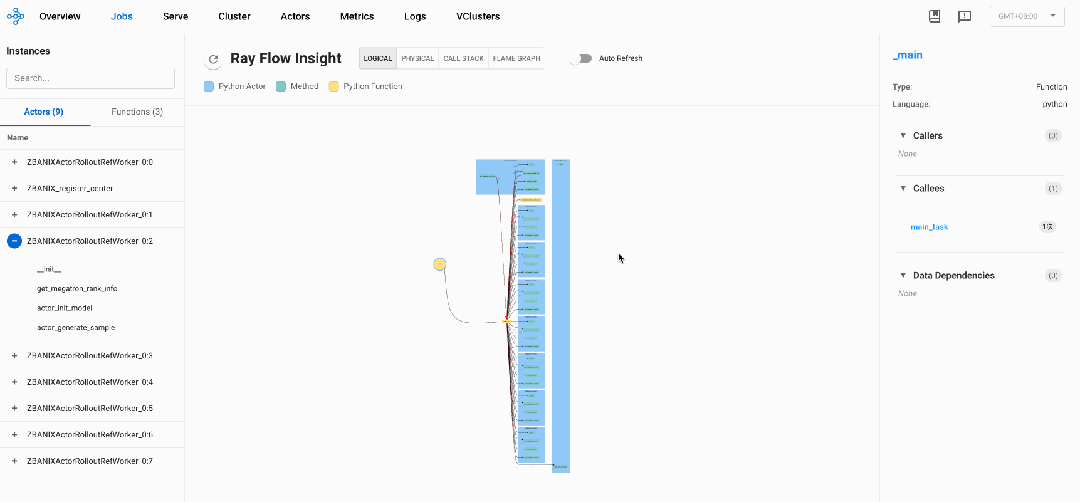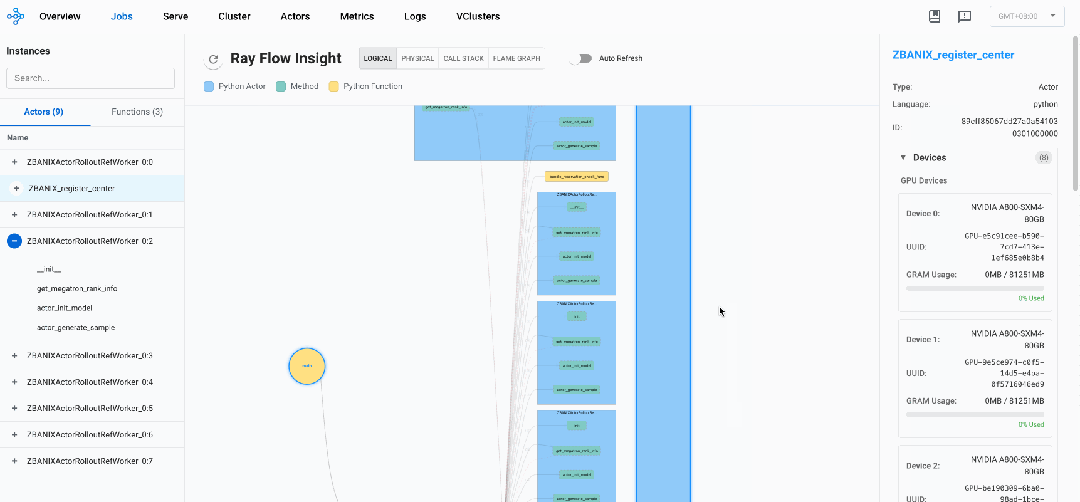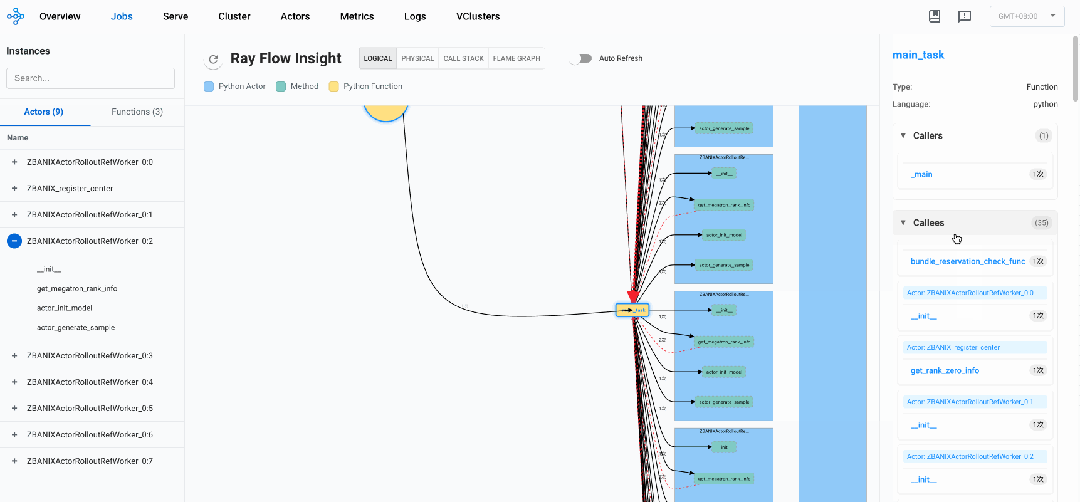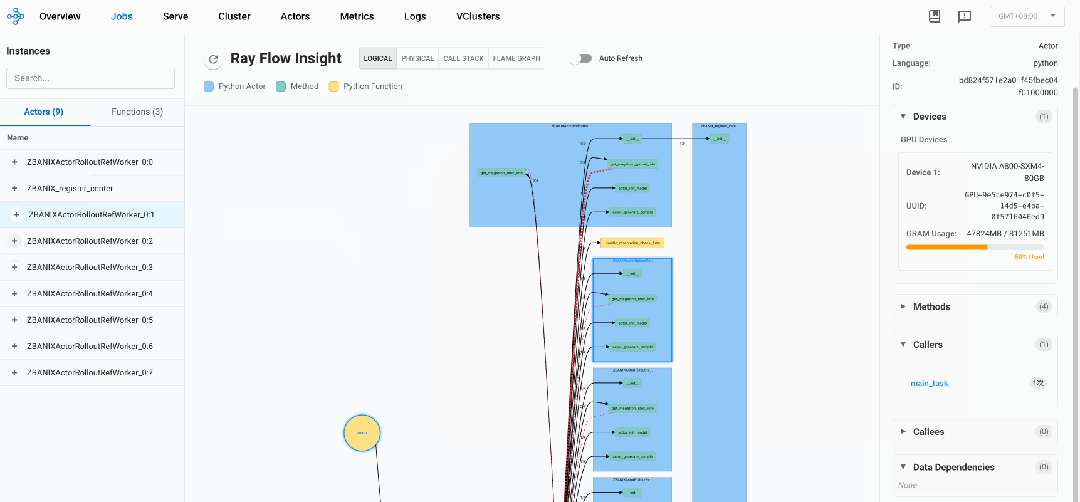
我们可以看到,veRL框架遵循带有分布式执行的中央协调模式:
-
系统由一个注册中心actor(register_center)和八个rollout actor(ActorRolloutRefWorker_0:0到ActorRolloutRefWorker_0:7)组成
-
调用流程显示一个星形模式,其中主函数(main_task)直接调用所有worker actor上的方法。worker actor之间没有直接通信,这表明采用了中央控制模型。
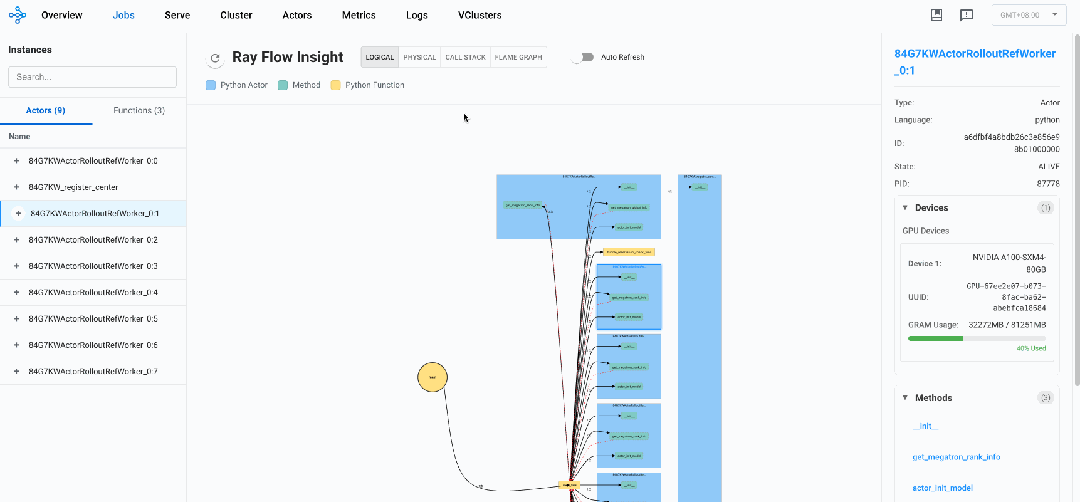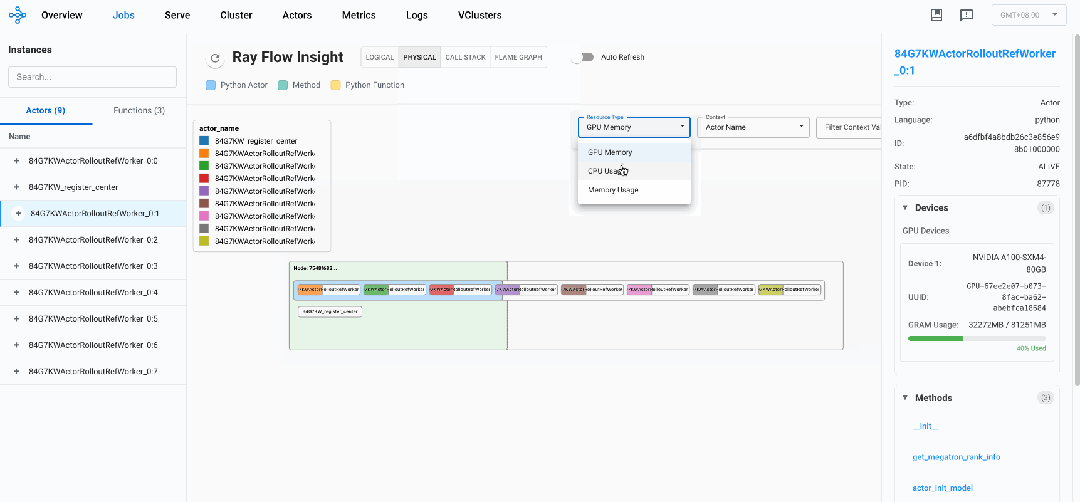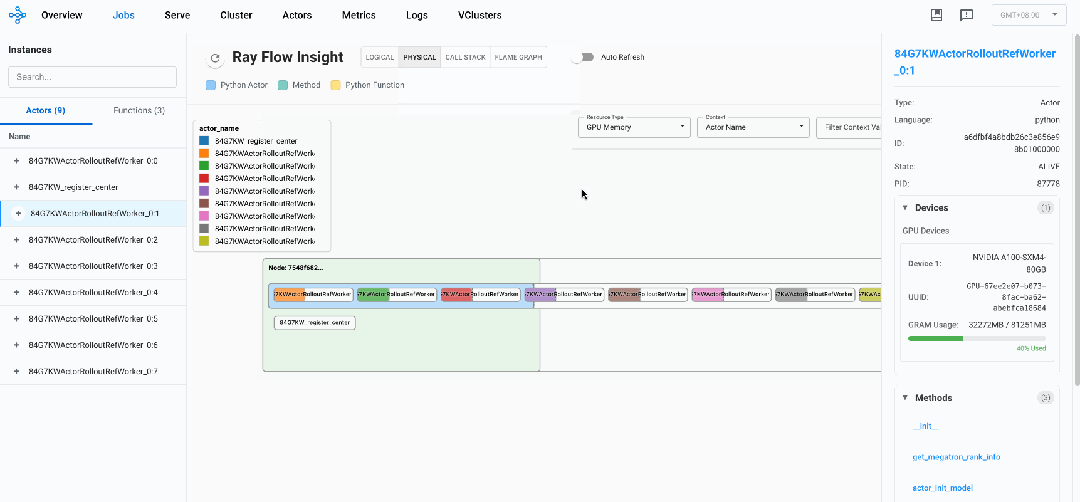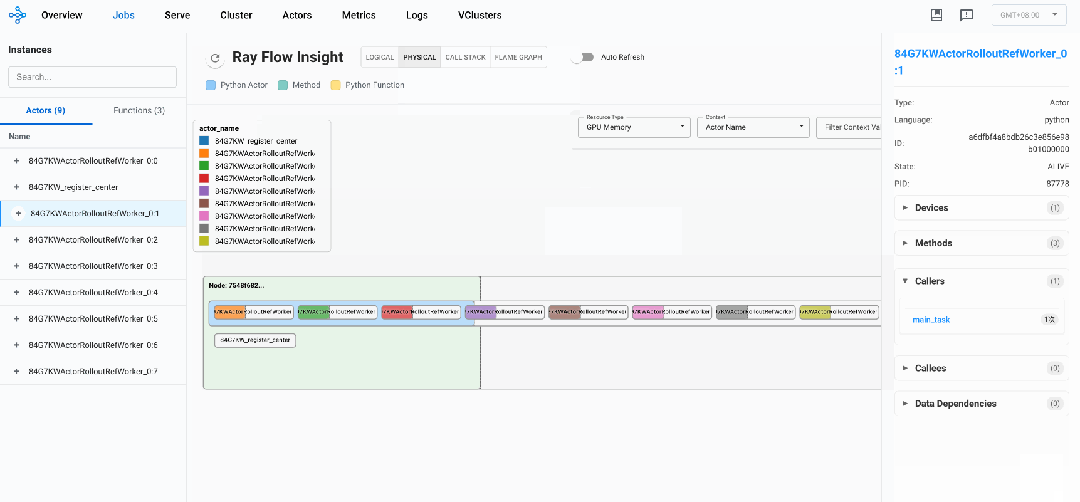
-
注册中心 (register_center):
-
不占用任何专用GPU资源
-
内存占用较小(约159MB RSS)
-
CPU使用率低(0.3%)
-
作为协调者而非计算节点运行
-
Worker节点 (ActorRolloutRefWorker_0:0 到 ActorRolloutRefWorker_0:7):
-
每个worker被分配一个专用GPU
-
CPU使用率非常高(~100.7-100.8%),表明是计算密集型工作
-
内存占用大且均衡(约68GB RSS)
-
每个worker被分配到特定编号的GPU上
def get_megatron_rank_info(self):
from megatron.core import parallel_state as mpu
tp_rank = mpu.get_tensor_model_parallel_rank()
dp_rank = mpu.get_data_parallel_rank()
pp_rank = mpu.get_pipeline_model_parallel_rank()
cp_rank = mpu.get_context_parallel_rank()
info = DistRankInfo(tp_rank=tp_rank, dp_rank=dp_rank, pp_rank=pp_rank, cp_rank=cp_rank)
# NOTE: Register tp/dp/pp context.
from ray.util.insight import register_current_context
register_current_context({"tp_rank": tp_rank, "dp_rank": dp_rank, "pp_rank": pp_rank, "cp_rank": cp_rank})
return info
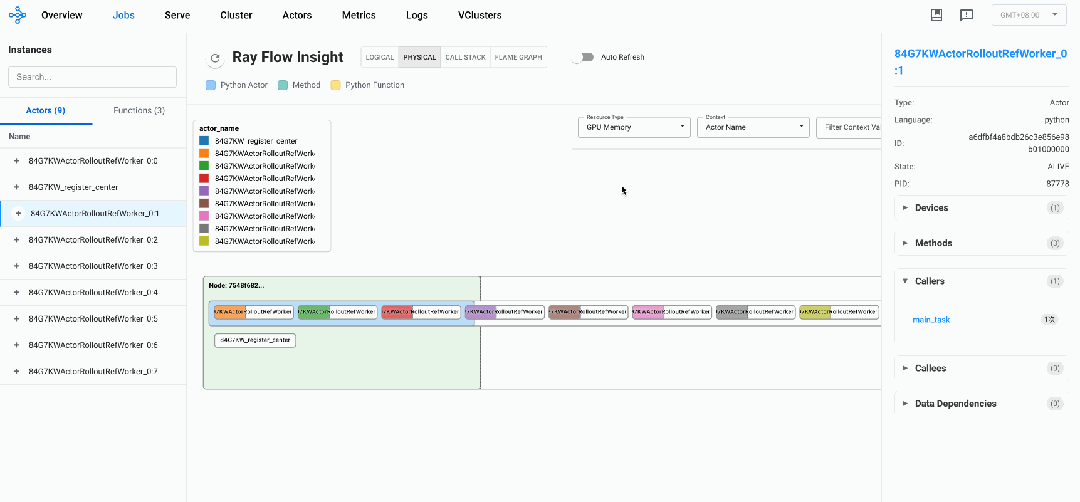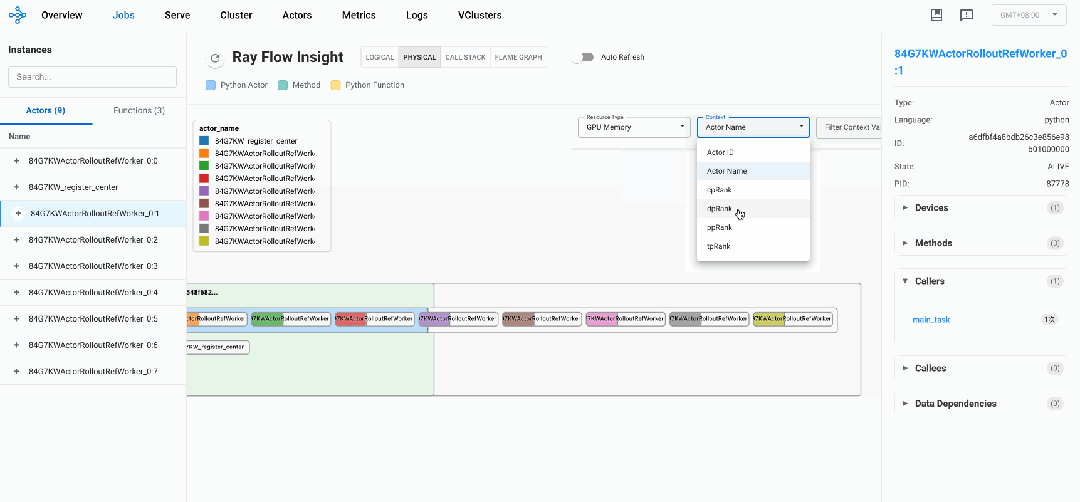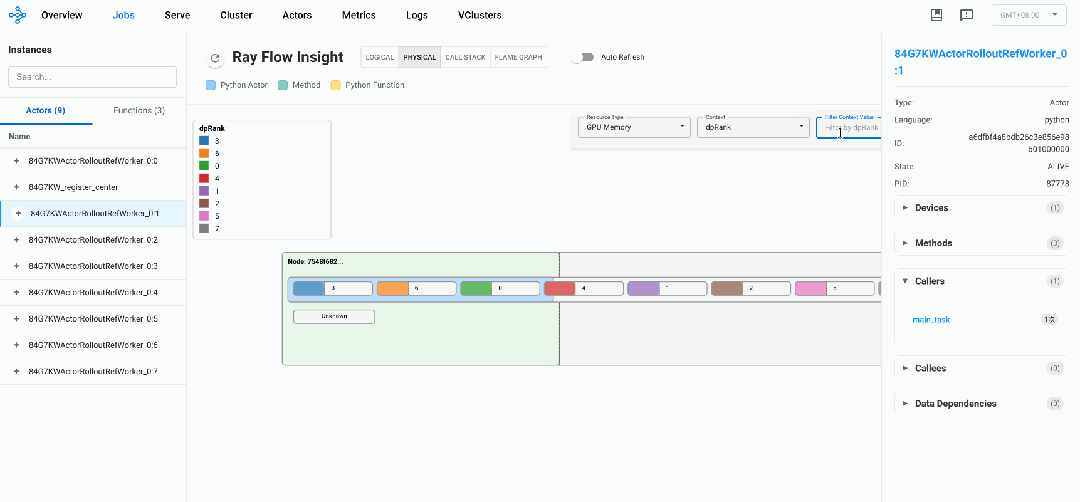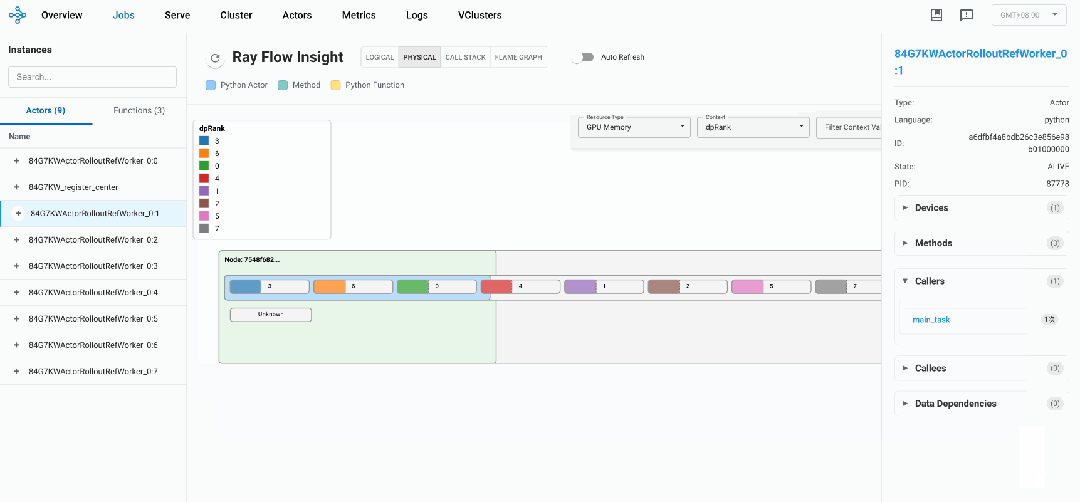
通过这些上下文信息,我们可以在 Flow Insight 中:
-
按 "pp_rank" 过滤,查看流水线并行的rank
-
按 "dp_rank" 过滤,查看数据并行的rank
-
按 "tp_rank" 过滤,查看tens or并行的rank
同时我们可以进行上下文搜索,筛选出我们需要的上下文对应的Actor。
分布式火焰图: 瓶颈分析
下图展示了verl的分布式火焰图,我们可以看到执行各个阶段不同调用的执行时间和占比
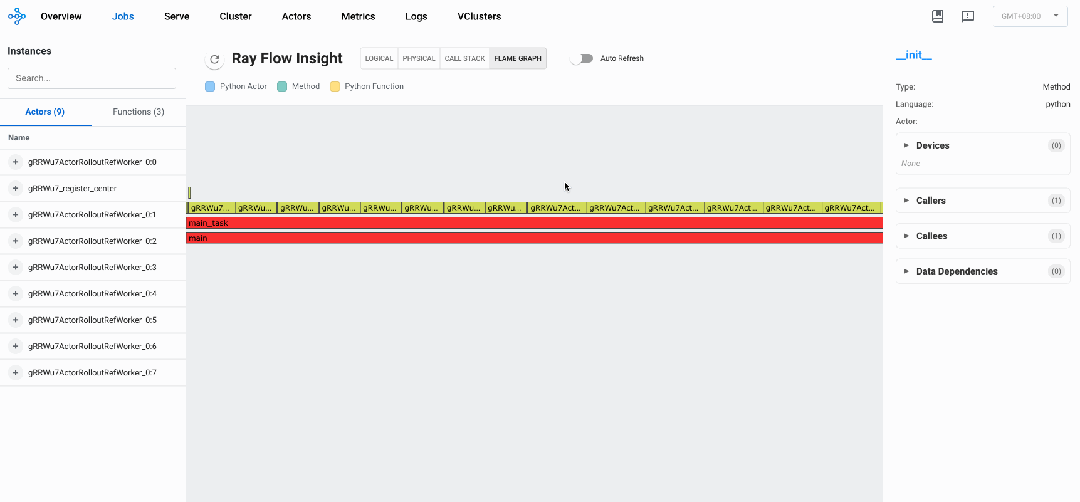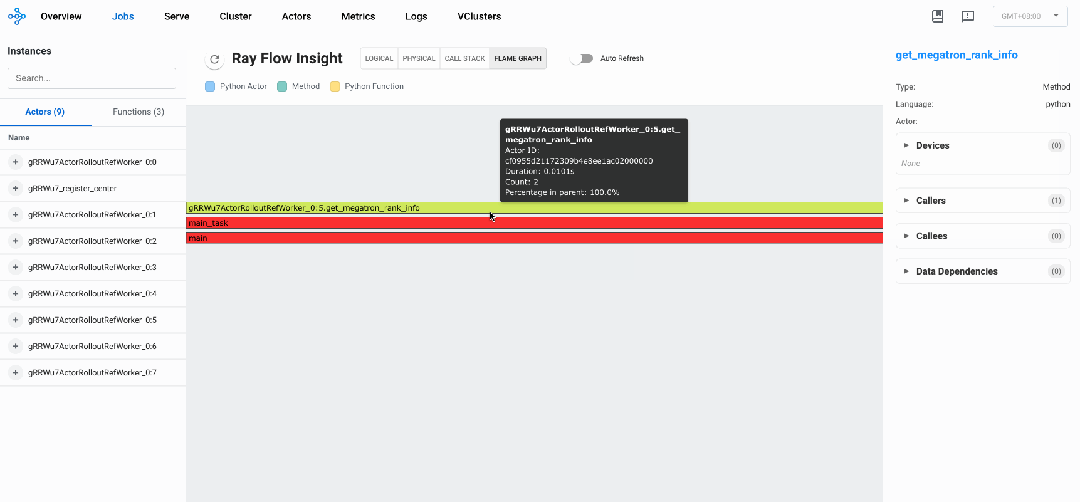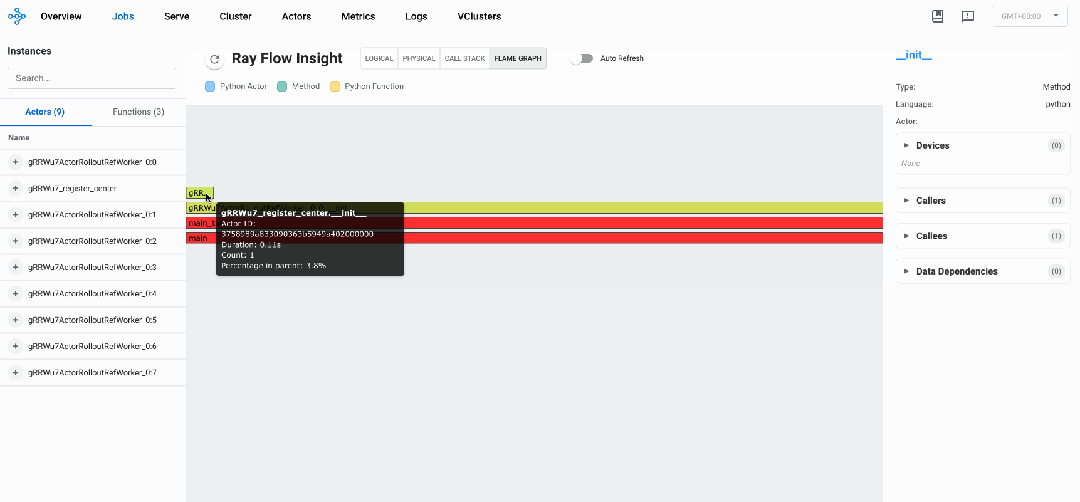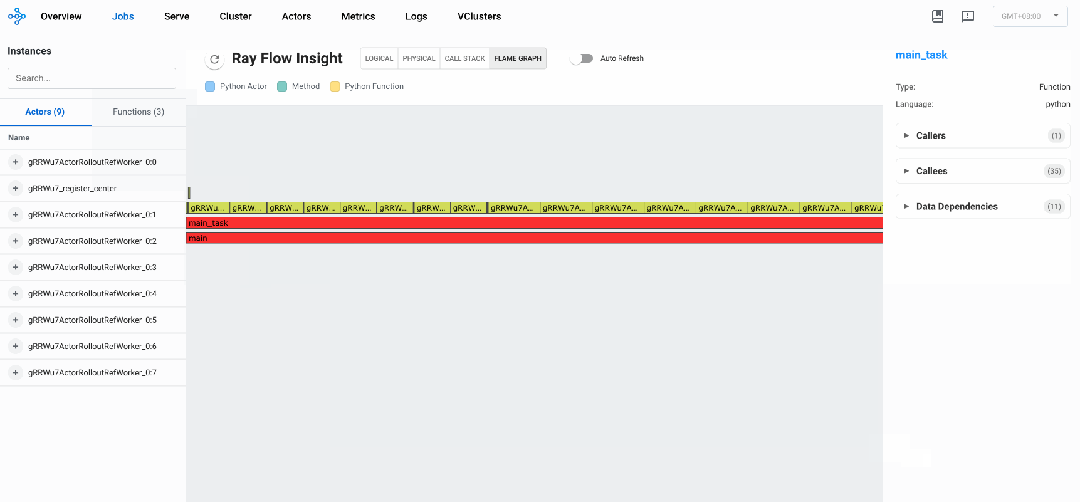
我们可以看到如下性能瓶颈:
-
样本生成阶段是明显的性能瓶颈,占总执行时间约70%,优化此阶段将带来最大的整体性能提升
分布式调用栈:
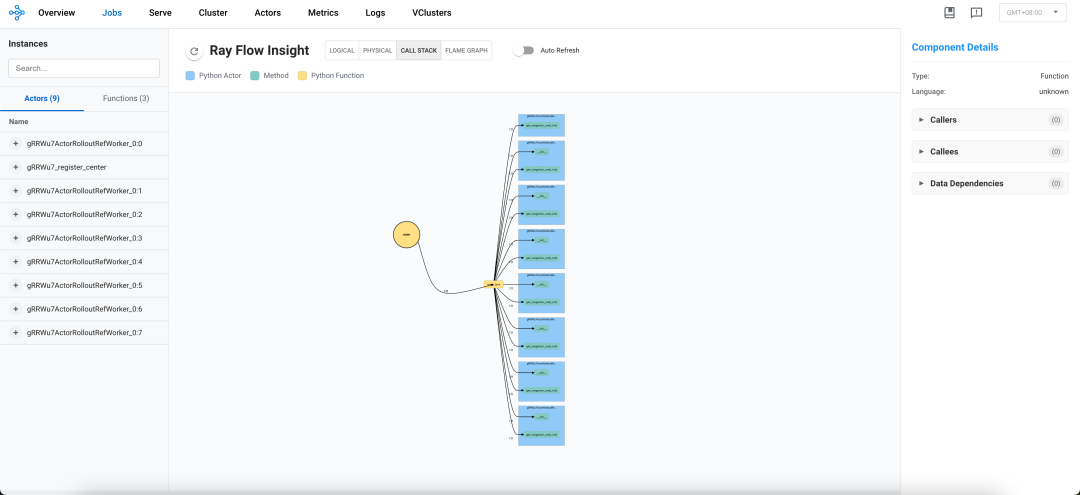
下图展示了verl的分布式调用栈,可以看到目前在get_megatron_rank_info阶段。
OpenRLHF框架案例分析
测试环境
-
算法:使用OpenRLHF框架执行PPO算法
-
节点数:2 个节点,每个节点4张A100计算卡
-
BaseModel:Qwen2.5-7B-Instruct
-
Rollout:采用VLLM(实例数:4,TP为1)
-
精度:BF16
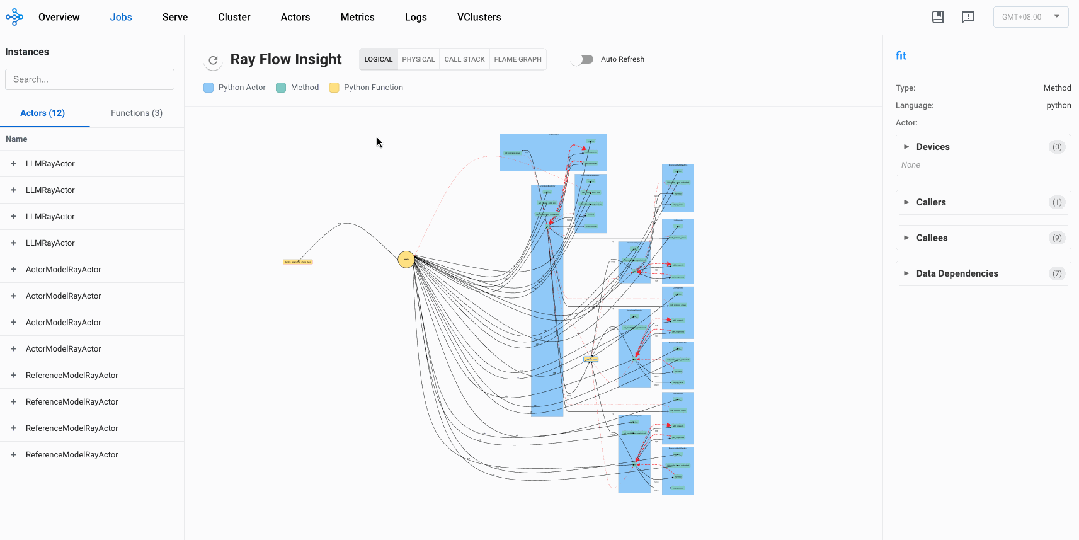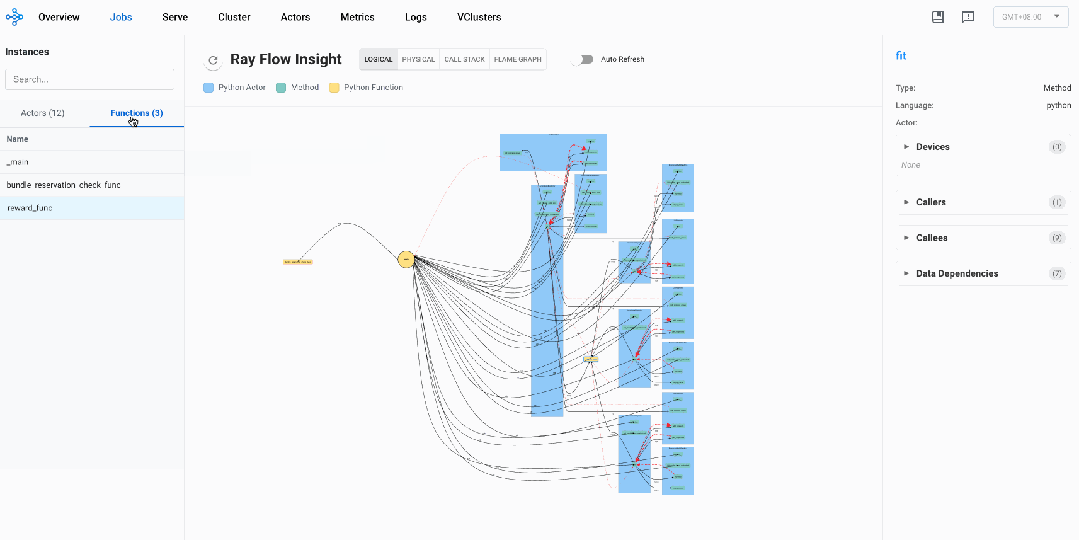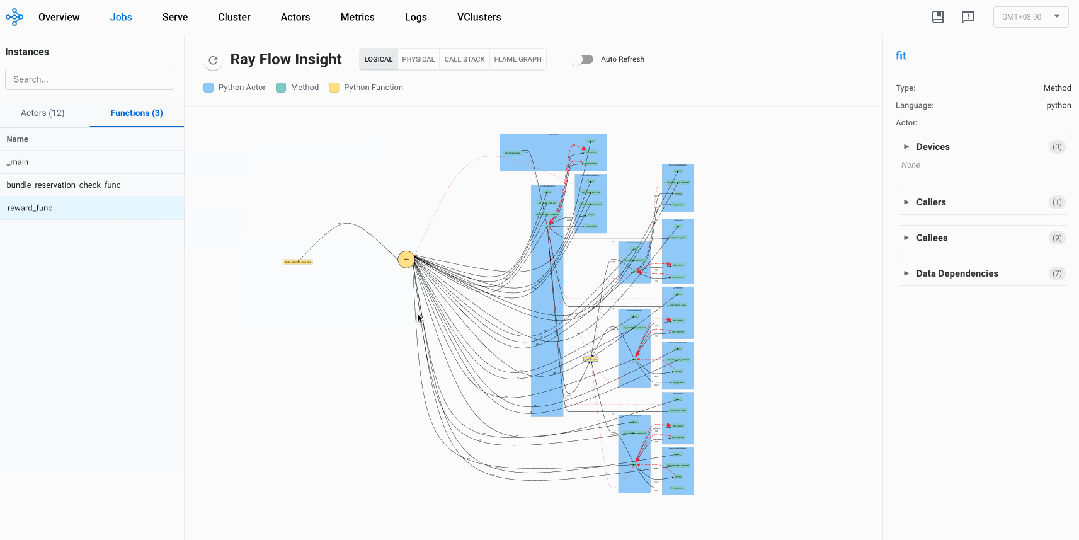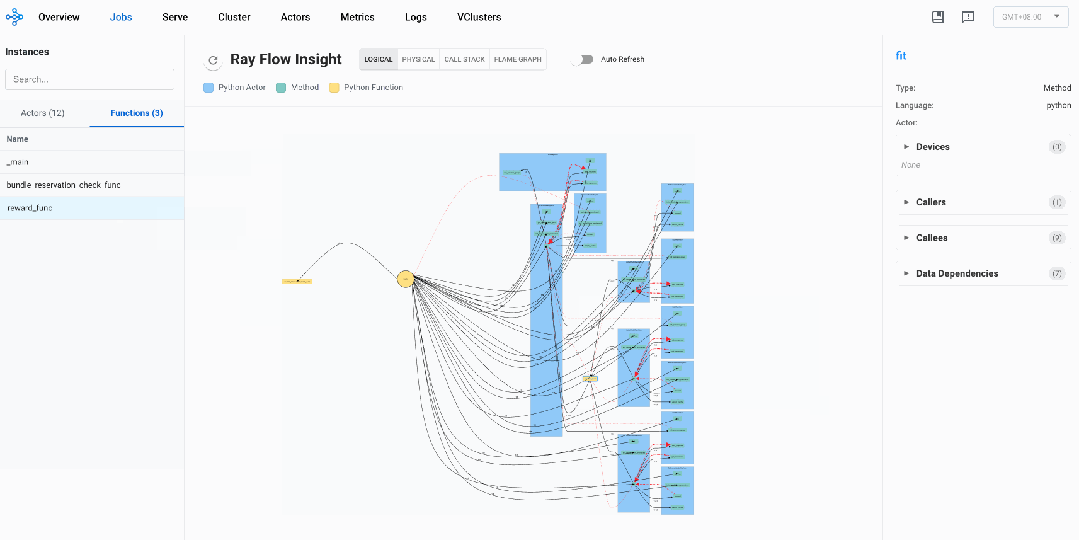
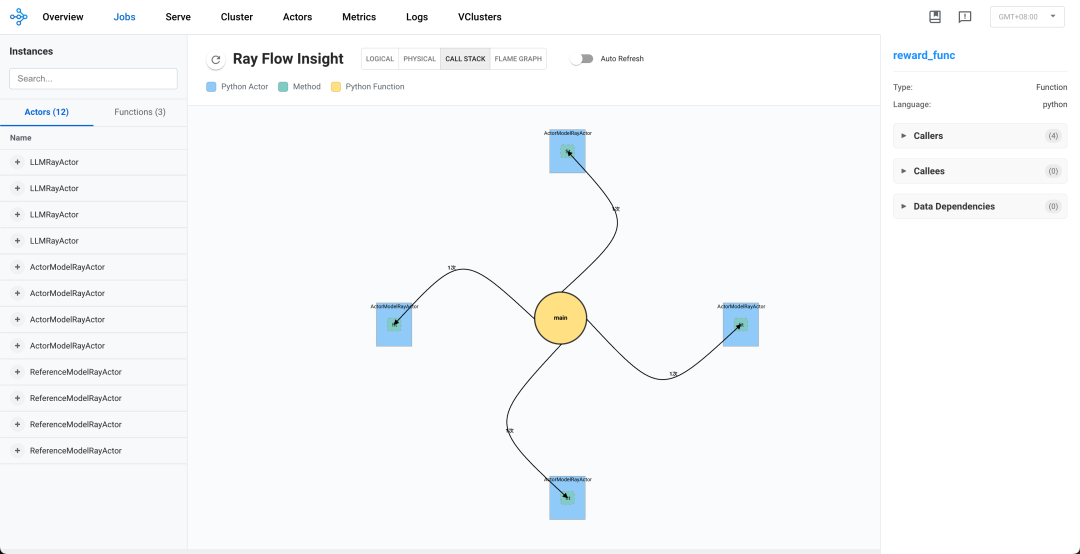
逻辑视图: OpenRLHF系统透视
全局视图如下
-
我们可以看到中间的圆形main,它代表着driver
-
从driver有很多条控制边,指向不同的Actor的方法和不同的Normal Task
-
不同的Actor Instances对应不同蓝色的框,我们可以看到三种Ray Actor:LLMRayActor、ActorModelRayActor、 ReferenceModelRayActor
-
黄色的方框代表Normal Task,我们可以看到两个Normal Task:bundle_reservation_check_func、reward_func
通过逻辑视图,我们梳理出如下调用模式:
-
_main函数初始化所有Ray Actor及其方法:
-
初始化每个actor
-
通过get_master_addr_port获取网络配置
-
使用init_model_from_pretrained加载模型
-
通过ActorModelRayActors的fit方法开始训练
-
训练过程展示了明确的RLHF模式:
-
ActorModelRayActors调用fit,调用LLMRayActors的init_process_group初始化分布式进程
-
ActorModelRayActors通过add_requests向LLMRayActors发送请求(数据大小约0.17-0.20MB)
-
LLMRayActors通过get_responses响应(数据大小约2.2-2.8MB)
-
通过forward调用ReferenceModelRayActors(数据大小约0.007-0.017MB)
-
推理后,通过empty_cache调用管理GPU内存
-
reward计算
-
所有四个ActorModelRayActors以相同频率(每个6次)调用reward_func函数
-
reward计算返回非常小的数据(约0.0004MB)
我们可以分析调用频率和模式:
- 高频操作:
-
a.对Reference Model的forward操作(每个actor 6次调用)
-
b.empty_cache操作(每个actor 6次调用)
-
c.reward_func调用(每个actor 6次调用)
- 数据流大小:
-
a.最大的数据传输是LLMRayActors通过get_responses向ActorModelRayActors的传输(约2.2-2.8MB)
-
b.add_requests请求大小中等(约0.17-0.20MB)
-
c.推理结果和reward数据非常小(<0.02MB)
- 关键路径:
a.reward计算似乎是潜在瓶颈,每次调用需要1.2-1.5秒
关于OpenRLHF更详细的内容,可以参考:图解OpenRLHF中基于Ray的分布式训练流程https://zhuanlan.zhihu.com/p/12871616401
物理视图: 资源分配与使用观测
利用物理视图,我们可以观察actor的物理布局信息
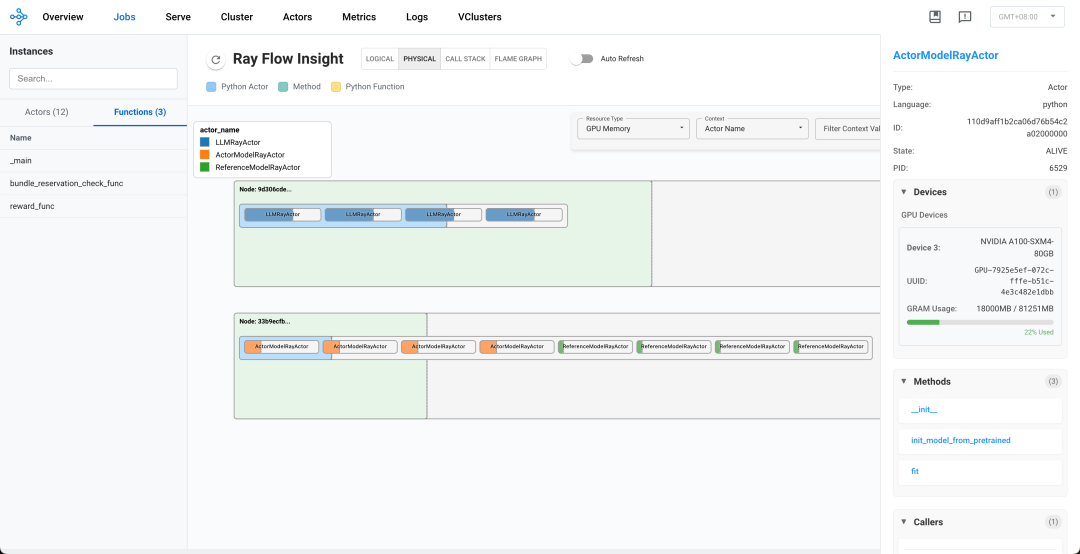
物理节点布局
系统在两个物理节点上运行:
-
节点ID:a6967f22f166b7a65f229e70ddef8f8a60c4fe716d57a8149c969638
-
主要托管所有LLMRayActor
-
节点ID: 5165655b497cf5020b7298d95b98b6e15353b0a06435dba781ee54ab
-
托管所有ActorModelRayActor和ReferenceModelRayActor
资源配置与分配策略
LLM节点 (第一个节点)
-
每个LLMRayActor独占一个完整GPU
-
资源分配模式:严格1:1分配,每个Actor获得一个GPU和相应的CPU
-
所有GPU内存使用相似(约51GB,总容量81GB)
Actor和Reference节点 (第二个节点)
-
采用共享资源模式:
-
每个GPU由一对ActorModel和ReferenceModel共享
-
ActorModel占用更多GPU内存(21-25GB)
-
ReferenceModel占用较少GPU内存(约2.2-2.3GB)
内存和CPU使用模式
-
MEM使用:
-
LLMRayActor: 大约14.6GB RAM
-
ActorModelRayActor: 约6.4GB RAM
-
ReferenceModelRayActor: 约13.2GB RAM (尽管GPU内存使用小,但系统内存使用大)
-
CPU使用:
-
LLMRayActor: CPU使用率低(0.3-0.5%)
-
ActorModelRayActor: CPU使用率中等(19.8-22.3%)
-
ReferenceModelRayActor: CPU使用率高(32.1-51.2%)
总的来看,我们可以观察到如下几点:
-
将大型LLM模型与Actor模型和reference模型分离到不同物理节点
-
减少资源竞争,提高系统稳定性
-
ActorModel和ReferenceModel共享GPU,但有不同的内存分配
-
每个GPU上分配的总内存使用不超过30GB(总容量81GB),保留足够缓冲空间
-
每个物理节点上的负载均匀分布在4个GPU上
-
同类模型分配相似资源,确保性能一致性
-
reference model CPU使用率高,但GPU内存占用少,表明模型结构设计上的差异
-
Actor model CPU和GPU使用更加平衡
分布式火焰图:瓶颈分析
通过分析Ray的火焰图数据,我可以深入了解OpenRLHF框架的执行流程、性能特征和潜在瓶颈。
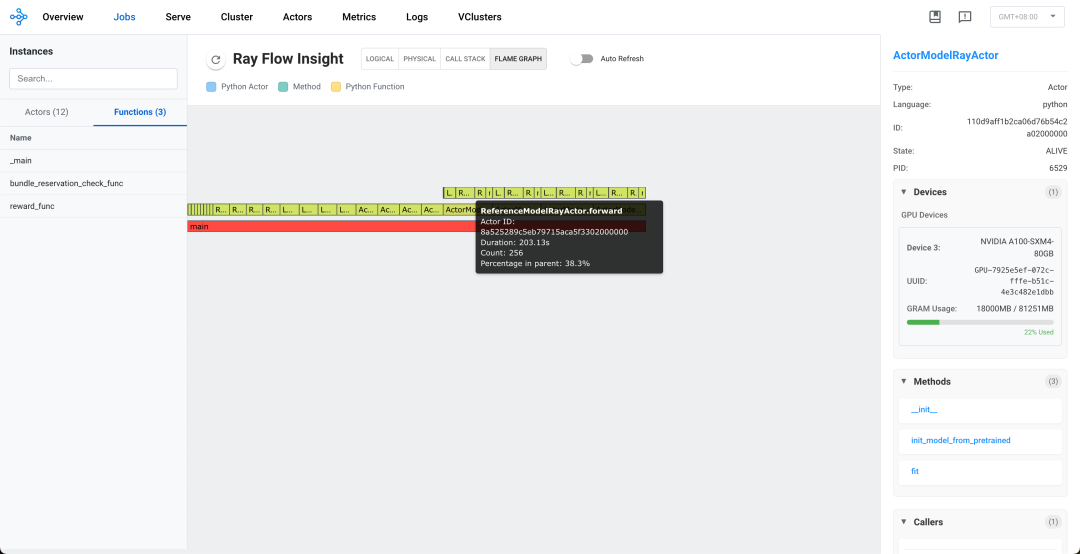
初始化与加载阶段
-
模型初始化耗时
-
LLM model: 初始化时间约193-195秒,四个实例耗时相近
-
Actor model: 初始化时间约5.3-5.6秒
-
Reference model: 初始化时间约5.2-5.7秒
-
模型加载耗时
-
Actor model加载: 所有四个实例的init_model_from_pretrained调用耗时约334-335秒
-
Reference model加载: init_model_from_pretrained调用耗时约152-160秒
-
这表明Actor model比Reference model大约大2倍,且LLM model的初始化过程复杂。模型加载是整个工作流中最耗时的阶段。
训练阶段关键操作
-
分布式初始化
-
init_process_group调用显示不同LLM实例初始化时间差异大, 最快的实例仅需0.006秒, 最慢的实例需要0.56秒, 这表明分布式同步存在不均衡性
-
请求处理
-
add_requests调用耗时显著:前两个实例约75-76秒, 后两个实例约131秒, 这种差异表明请求批处理可能存在不平衡
-
generation获取
-
get_responses调用相对快速(0.025-0.033秒)
-
响应获取比请求添加快得多,说明大部分时间消耗在请求处理而非结果传输
-
模型前向传播
-
参考模型的forward调用(每个模型6次):总耗时约6.8-7.9秒, 平均每次调用耗时约1.1-1.3秒, 各模型间性能差异小于15%
-
内存管理
-
empty_cache操作(每个模型6次):总耗时约1.6-1.9秒, 平均每次耗时约0.27-0.31秒, 表明GPU内存管理开销适中
-
reward计算
-
reward_func被调用24次(每个Actor模型6次):总耗时约4.17秒, 每次调用平均约0.17秒, 但不同Actor模型间差异显著:
-
ActorModel 23c9 和 6ccc:总计约1.6-1.8秒
-
ActorModel 90eb 和 920a:总计仅0.33-0.38秒
-
这种5倍差异表明奖励计算可能依赖于输入内容
分布式调用栈
截取某一时刻的DStack,我们可以看到目前正在进行ActorModel的fit操作。
五、总结与展望
-
完善的容错机制:提供数据模型持久化能力,使得RayInsightMonitor故障后能恢复
-
更广泛的语言支持:除了当前的Python支持,扩展到Java和C++等多语言环境
-
智能异常检测:识别资源使用异常、任务执行时间异常,分布式组件间的异常传播路径,帮助理解问题如何在系统中扩散
-
时序快照回溯:支持历史快照回溯功能
[9] 200美金,人人可手搓QwQ,清华、蚂蚁开源极速RL框架AReaL-boba(https://zhuanlan.zhihu.com/p/1889988181006467307)