线上部署DeepSeek-R1模型显存占用持续上升?本文剖析PyTorch显存管理机制,提供优化建议,避免显存碎片化。
原文标题:AI Infra之模型显存管理分析
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章提到了量化可以减少显存占用,INT8和INT4量化精度损失不同,除了文章中提到的适用场景,还有什么其他的考量因素吗?
3、文章中提到context_factory()是PyTorch 的上下文管理器,常用来管理GPU资源,性能监控,异常捕获等场景。除了这些,它还有什么其他的应用场景么?
原文内容

阿里妹导读
本文围绕某线上客户部署DeepSeek-R1满血版模型时进行多次压测后,发现显存占用一直上升,从未下降的现象,记录了排查过程。
背景
某线上客户部署DeepSeek-R1满血版模型,进行多次压测后,发现显存占用一直上升,从未下降,于是发出了灵魂三问:
在分析问题之前,必须要了解客户的环境,客户的环境如下:
排查分析
显存分配是否合理
面对客户疑问,抱着“显存真的一直上升吗?”的怀疑尝试复现客户的情况。利用vllm启动模型时候,vllm日志中已经显示如下对单卡的显存的占用信息。
INFO 03-20 19:40:50 worker.py:267] Memory profiling takes 16.56 seconds
INFO 03-20 19:40:50 worker.py:267] the current vLLM instance can use total_gpu_memory (9x.00 GiB) x gpu_memory_utilization (0.95) = 9x.00 GiB
INFO 03-20 19:40:50 worker.py:267] model weights take 42.59GiB; non_torch_memory takes 2.30GiB; PyTorch activation peak memory takes 1.42GiB; the rest of the memory reserved for KV Cache
is 4x.00 GiB.
在ACS中,分布式部署的大模型,每个Pod是8张GPU卡。所以Pod维度是9x.00 GiB*8=7xxGiB
模型占用/Pod:42.59GiB*8=340.72GiB
non_torch_memory/Pod:2.30GiB*8=18.4GiB
PyTorch activation peak memory/每Pod:1.42Gib*8=11.36GiB
KV Cache/每Pod 4x.00GiB*8=3xxGiB
而Prometheus监控显示显存Pod占用7xxGiB的显存,这个是和日志匹配上的。

尝试复现抓住现场
第一次请求
以下面的语句对模型进行query请求。
time curl http://172.17.98.24:8080/v1/chat/completions -H "Content-Type: application/json" -d '{ "model": "ds", "messages": [ { "role": "system", "content": "你是个友善的AI助手。" }, { "role": "user", "content": "介绍一下深度学习好吗。" } ], "max_tokens": 2048 }'
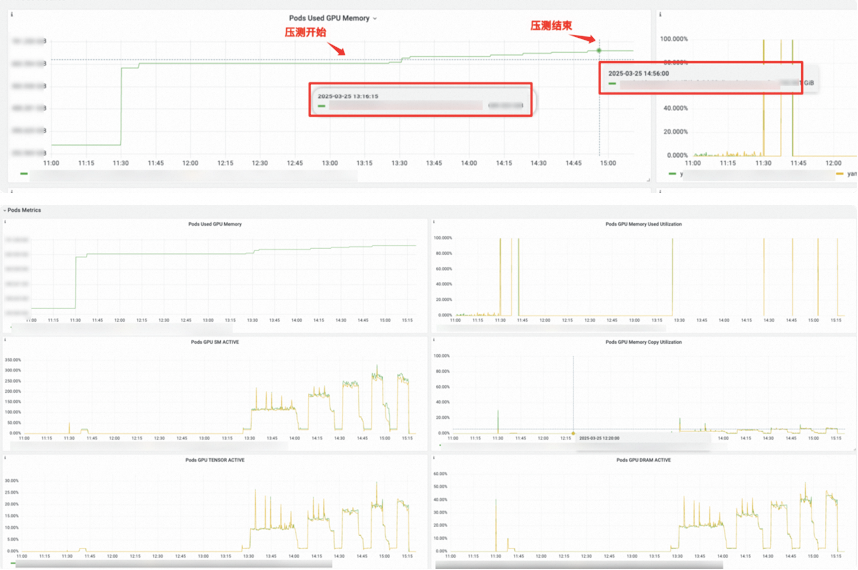
Prometheus监控显示显存使用上升2GiB, 并且持续2h未下降。

会不会是KV Cache不足
在请求过程中KV cache使用率在0.1左右,所以原则上不存在KV显存不足,占用系统层面显存。

通过配置VLLM指标抓取,也从侧面佐证了KV cache占用很低,不存在KV Cache不足。同时通过Ray的监控也证明了在Query时候,显存使用率增长,但不会下降。


监控指标是否异常
因为指标是来自Prometheus,所以可能是Prometheus的指标问题,或Prometheus的PromQL语句展现的是累计值。
分析Prometheus的指标的Expore如下,采集的是DCGM_FI_DEV_FB_USED,并且该值和nvidia-smi命令中Memory-Usage的已使用值相对应。
sum(DCGM_FI_DEV_FB_USED{PodName=~"", NamespaceName=~""})by(NamespaceName, PodName)
|
指标名称 |
指标类型 |
单位 |
说明 |
|
DCGM_FI_DEV_FB_USED |
Gauge |
MiB |
表示帧缓存已使用数。 该值与nvidia-smi命令中Memory-Usage的已使用值对应。 |
进到pod对比前后的nvidia-smi情况,可以看到每张GPU卡的显存都会提高,并且一直不会被释放。

显存增长是否有上限
对推理服务进行了100个请求,10并发,INPUT 3500,OUTPUT 1250的压测,发现压测后Pod显存占用增长了将近60GiB,压测结束后依然不会下降。
是NCCL还是CUDA
到目前为止,问题可以明确在推理框架以下了,但是不确定是NCCL还是CUDA引发的异常显存占用,所以需要对模型服务抓取nsight进行分析。容器环境抓取比较费劲,需要挂载nas等存储以便储存临时的nsight文件。
#抓取vllm nsight
nohup nsys launch -t cuda,nvtx,osrt,cudnn,cublas,opengl,cudla-verbose,cusolver-verbose --cudabacktrace=all --cuda-memory-usage=true --cuda-um-cpu-page-faults=true --cuda-um-gpu-page-faults=true --session-new vllm-capture1 vllm serve /model/DeepSeek-R1/ --port 8080 --trust-remote-code --served-model-name ds --enable-reasoning --reasoning-parser deepseek_r1 --max-num-batched-tokens 8192 --max-model-len 8192 --enable-prefix-caching --gpu-memory-utilization 0.90 --tensor-parallel-size 16 --enforce-eager > /tmp/vllm-capture.log 2>&1 &
看nsight文件,收到query请求后,由pytorch调用cudamalloc申请显存,共申请246M x 8 (Phase2: 显存增加2GB)与复现现象一致。
NCCL初始化配置在模型加载时已经完成,可以排除NCCL导致。



设置环境变量,GPU设置为阻塞同步方式,方便观察GPU信息。由于deepseek模型参数量大,加载缓慢,更换Qwen 1.5B模型,使用单机环境方便,现象依然存在,并且增加prompt长度,显存申请数量增加,与压侧显存不断增长现象相对应。
#阻塞同步 export CUDA_LAUNCH_BLOCKING=1#PDB
from vllm import LLM,sampling_paramsprompt=[
“Hello, my name is”,
“The president of the United States is”,
“The capital of France is”,
“The future of AI is”,
]
model_name = “Qwen/Qwen2.5-1.5B”llm=LLM(model= model_name,trust_remote_code=True,gpu_memory_utilization=0.95,max_model_len=8192)
ans=llm.generate(prompts=prompt)
for output in ans:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
通过pdb+nvidia-smi配合,观察到显存增加处为with ctx_factory()。
调用关系如下:
llm.generate()→LLMEngine.step()→model_executor.execute_model()→driver_worker.execute_model()→model_runner.execute_model()
/usr/local/lib/python3.10/bdb.py(598)run()
-> exec(cmd, globals, locals)
<string>(1)<module>()
/mnt/workspace/gx/main.py(11)<module>()
-> ans=llm.generate(prompts=prompt)
/usr/local/lib/python3.10/site-packages/vllm/utils.py(838)inner()
-> return fn(*args, **kwargs)
/usr/local/lib/python3.10/site-packages/vllm/entrypoints/llm.py(316)generate()
-> outputs = self._run_engine(use_tqdm=use_tqdm)
/usr/local/lib/python3.10/site-packages/vllm/entrypoints/llm.py(569)_run_engine()
-> step_outputs = self.llm_engine.step()
/usr/local/lib/python3.10/site-packages/vllm/engine/llm_engine.py(911)step()
-> output = self.model_executor.execute_model(
/usr/local/lib/python3.10/site-packages/vllm/executor/gpu_executor.py(110)execute_model()
-> output = self.driver_worker.execute_model(execute_model_req)
/usr/local/lib/python3.10/site-packages/vllm/worker/worker_base.py(272)execute_model()
-> output = self.model_runner.execute_model(
> /usr/local/lib/python3.10/site-packages/torch/utils/_contextlib.py(114)decorate_context()->[SamplerOutput..._metrics=None)]
-> with ctx_factory():
(Pdb)
ctx_factory()是PyTorch 的上下文管理器,常用来管理GPU资源,性能监控,异常捕获等场景。所以基本可得出此现象与pytorch缓存机制有关。
进一步佐证定位Pytorch
在/root/miniconda3/envs/niqi-vllm/lib/python3.10/site-packages/vllm/worker/model_runner.py中的def execute_model下插入:
for device_id in range(8): #8表示几张卡
print(torch.cuda.memory_summary(device_id))

压测前后,可以看到Nvidia 0和6卡增加了1346MiB,对应的是 GPU reserved memory中 “from large pool”这种增加,其他的GPU显存占用在测试前后并无区别,进一步证明显存的增加唯一源是pytorch的缓存机制。

Pytorch显存cache管理剖析
主要数据结构

Block:
-
分配 / 管理内存块的基本单位,(stream_id, size, ptr) 三元组可以特异性定位一个 Block,即 Block 维护一个 ptr 指向大小为 size 的内存块,隶属于 stream_id 的 CUDA Stream。
-
所有地址连续的 Block(不论是否为空闲,只要是由 Allocator::malloc 得来的)都被组织在一个双向链表里,便于在释放某一个 Block 时快速检查前后是否存在相邻碎片,若存在可以直接将这三个 Block 合成为一个。
BlockPool:
-
内存池,用
std::set存储 Block 的指针,按照 (cuda_stream_id -> block size -> addr) 的优先级从小到大排序。所有保存在 BlockPool 中的 Block 都是空闲的。
-
DeviceCachingAllocator中维护两种 BlockPool (large_blocks, small_blocks),分别存放较小的块和较大的块(为了分别加速小需求和大需求),简单地将 <= 1MB 的 Block 归类为小块,> 1MB 的为大块。
直观理解 Block、BlockPool 见下图:
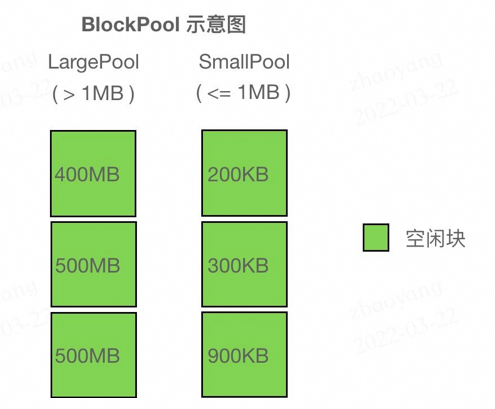
BlockPool 示意图,左边两个 500MB 的块 size 相同,因此上面的比下面的地址更
Block 在 Allocator 内有两种组织方式,一种是显式地组织在 BlockPool(红黑树)中,按照大小排列;另一种是具有连续地址的 Block 隐式地组织在一个双向链表里(通过结构体内的 prev, next 指针),可以以 O(1) 时间查找前后 Block 是否空闲,便于在释放当前 Block 时合并碎片。
申请block过程

根据 size 决定实际上的 alloc_size:
- 为小于 1MB 的 size 分配 2MB;
- 为 1MB ~ 10MB 的 size 分配 20MB;
- 为 >= 10MB 的 size 分配 { size 向上取整至 2MB 倍数 } MB。

碎片管理
通过环境变量会指定一个阈值 max_split_size_mb,实际上从变量名可以看出,指定的是最大的可以被 “split” 的 Block 的大小。
alloc_block 函数通过 cuda 新申请的 Block(这是 Allocator 唯一一个创建新 Block 的途径)大小是计算出的 alloc_size 而不是用户通过 malloc 请求的大小 size。因此,如果 malloc 成功返回了一个 Block,Allocator 会通过函数 should_split 检查:
-
由于过量分配内存,Block 内部产生的大小为 alloc_size - size 的碎片大小称为 remaining;
-
如果这个 Block 属于 small_blocks 且 remaining >= 512 Bytes;或者 remaining >= 1MB 且该 Block 大小没有超过上述的阈值,则这个 Block 需要被 split。
max_split_size_mb)会不断被分成小的 Block。值得注意的是,由于新 Block 的产生途径只有一条,即通过 alloc_block 函数经由 cudaMalloc 申请,无法保证新 Block 与其他 Block 地址连续,因此所有被维护在双向链表内的有连续地址空间的 Block 都是由一个最初申请来的 Block 拆分而来的。
一段连续空间内部(由双向链表组织的 Block 们)如下图所示:

释放block
当 Block 被释放时,会检查其 prev、next 指针是否为空(以此判断是否被使用)。若没有在被使用,则会使用 try_merge_blocks 合并相邻的 Block。由于每次释放 Block 都会检查,因此不会出现两个相邻的空闲块,于是只需检查相邻的块是否空闲即可。这一检查过程见 free_block 函数。又因为只有在释放某个 Block 时才有可能使多个空闲块地址连续,所以只需要在释放 Block 时整理碎片即可。
释放cache
CUDACachingAllocator 申请并维护的缓存,不会自动释放,直到显式调用torch.cuda.memory.empty_cache()实际会走到CUDACachingAllocator:emptyCache,最终通过release_blocks释放large/small 两个blocks。

结论及建议
nvidia-smi值是reserved_memory和torch context显存之和。在推理过程中虽然不会主动释放,但是随着block的增多,也会有大量新的请求使用已经存在的空闲block,增长趋势会愈发变慢最终达到稳态。
CUDA_PYTORCH_CUDA_ALLOC_CONF将max_split_size_mb调小,来减少显存碎片化的影响。
max_split_size_mb外,还可以考虑其他优化策略来减少显存碎片化,如使用显存清理工具(如torch.cuda.empty_cache())或调整模型和数据加载策略。
本文撰写过程中感谢@复东@倪祺给予的帮助。
附录
模型显存计算逻辑
总显存计算
推理所需显存=模型参数部分+激活参数部分+KV Cache部分
-
模型参数部分=模型参数量 × 精度系数
- 量化精度与字节数关系:
- FP16/BF16:每个参数占用 2字节
- INT8:每个参数占用 1字节
- INT4:每个参数占用 0.5字节
-
激活参数部分=激活参数量 × 精度系数
-
KV Cache部分=并发数 × (输入Token数+输出Token数) × 2 × 层数 × hidden_size × Sizeof(精度系数)
- 关键参数说明:
- 层数:模型层数(如DeepSeek-R1 671B可能包含80层)
- 隐藏层维度:模型每层的神经元数量(如1024或更大)
- 序列长度:上下文长度(例如1K、4K、8K等)
- 量化精度:与模型参数一致,如FP16/BF16对应2字节
总的显存容量评估如下:=671×1GB+37x1G+30×(2048+2048)×2×61×7168×1Bytes=671 GB + 100.08GB=808.08GB
首token及每Token延时评估
大模型推理其实不只看GPU的显存大小,其他参数如GPU的算力、GPU的显存带宽以及模型参数量大小都是影响实际使用的重要因素:
- GPU显存大小:决定了能够加载并运行多大量&精度的模型;
- GPU算力大小:与首token延时密切相关,算力越高首Token越快;
- GPU带宽大小:与每token延时有关,带宽越大token并发越高;
- 模型参数&精度:通常模型参数越大,准确率越高,逻辑能力越强;
1、首token延时评估公式如下:
首token延时=模型参数×并发数×输入Token数×sizeof(精度) /(GPU峰值算力*90%)
2、每token延时计算方法
每token延时=模型权重内存大小÷(显存带宽*利用率)+KV Cahce内存大小÷(显存带宽*利用率)+卡间通信时延
卡间通信延时:hidden_size ×并发数× sizeof(精度) × 2 × layers ÷卡间带宽
- 单卡推理:显存带宽利用率 按经验值60%,
- 多卡并行:显存带宽利用率 按经验值40%
上下文长度对显存的影响
上下文长度直接影响KV缓存的大小。以FP16精度为例:
- 每Token的KV缓存需求 ≈ 2 × 层数 × 隐藏层维度 × 2字节
- 总KV缓存需求 ≈ 每Token需求 × 序列长度 × 批大小
- 示例:
对于671B模型(层数80,隐藏维度8192),1K上下文长度的KV缓存需求为:2 × 80 × 8192 × 2字节 × 1024 ≈ 2.6GB
若扩展到8K上下文,则需求升至 21GB。
优化策略与显存压缩
量化技术:
使用INT8或INT4量化可显著降低显存需求。例如,671B模型在INT4下显存占用仅需 335.5GB(参数)+ 约5.3GB(KV缓存)≈ 340.8GB
大模型量化:降低占用显存,加快推理速度但损失精度
大模型的量化精度INT8与INT4:INT8适用于大多数需要推理加速的场景;INT4导致较大精度损失,特定场景仍有价值
异构计算:
通过将稀疏MoE矩阵卸载到CPU内存,仅保留稠密部分在GPU显存中(如KTransformers项目),可将671B模型的显存需求从200GB+压缩至24GB。
算子优化:
使用Marlin算子加速量化计算,结合CUDA Graph减少显存碎片,提升利用率
总结公式
- 总显存 ≈ (参数量 × 量化字节数) + (2 × 层数 × 序列长度 × 隐藏维度 × 量化字节数× 批大小) + 框架开销
- 关键变量:参数量、量化精度、上下文长度、批大小、模型架构参数(层数、隐藏维度)。
Pytorch显存管理源码
Block* malloc( c10::DeviceIndex device, size_t orig_size, cudaStream_t stream) { // done outside the lock because we don't know what locks the recorder needs // to have... auto context = maybeGatherContext(RecordContext::STATE);std::unique_lock<std::recursive_mutex> lock(mutex);
if (C10_LIKELY(captures_underway.empty())) {
// Processes end-of-life events for outstanding allocations used on
// multiple streams (checks if their GPU-side uses are complete and
// recycles their memory if so)
//
// Q. Why skip process_events if a capture might be underway?
// A. process_events involves cudaEventQueries, illegal during CUDA graph
// capture.
// Dumb simple solution: defer reclaiming these allocations until after
// capture. Cross-stream memory use is uncommon, so the deferral’s
// effect on memory use during capture should be small.
process_events(context);
}
size_t size = round_size(orig_size);
auto& pool = get_pool(size, stream);
const size_t alloc_size = get_allocation_size(size);
AllocParams params(device, size, stream, &pool, alloc_size, stats);
params.stat_types = get_stat_types_for_pool(pool);// First, try to get a block from the existing pool.
bool block_found =
// Search pool
get_free_block(params)
// Trigger callbacks and retry search
|| (trigger_free_memory_callbacks(params) && get_free_block(params));// Can’t reuse an existing block; try to get a new one.
if (!block_found) {
// Do garbage collection if the flag is set.
if (C10_UNLIKELY(
set_fraction &&
CUDAAllocatorConfig::garbage_collection_threshold() > 0.0)) {
garbage_collect_cached_blocks(context);
}
// Attempt allocate
// WARNING: alloc_block may release the allocator lock when calling
// cudaMalloc. So far this function has not modified allocator state, but
// keep in mind that any observed allocator state may change across calls
// to alloc_block since it may release the lock.
block_found = alloc_block(params, false, context, lock)
// Free enough available cached blocks to satisfy alloc and retry
// alloc.
|| (release_available_cached_blocks(params, context) &&
alloc_block(params, false, context, lock))
// Free all non-split cached blocks and retry alloc.
|| (C10_LIKELY(captures_underway.empty()) &&
release_cached_blocks(context) &&
alloc_block(params, true, context, lock));
}if (!block_found) {
//OOM流程
}
bool split_remainder = should_split(params.block, params.size());
return alloc_found_block(
params, orig_size, std::move(context), split_remainder);
}
void free(Block* block) { std::shared_ptr<GatheredContext> context = maybeGatherContext(RecordContext::ALL); std::lock_guard<std::recursive_mutex> lock(mutex);block->allocated = false;
// following logic might modifying underlaying Block, causing the size
// changed. We store ahead for reporting
auto orig_block_ptr = block->ptr;
auto orig_block_size = block->size;StatTypes stat_types = get_stat_types_for_pool(*block->pool);
for_each_selected_stat_type(stat_types, & {
stats.allocation[stat_type].decrease(1);
stats.allocated_bytes[stat_type].decrease(block->size);
});
auto allocated_bytes_gauge =
STATIC_GAUGE(pytorch.CUDACachingAllocator.allocated_bytes);
allocated_bytes_gauge.record(
stats.allocated_bytes[static_cast<int64_t>(StatType::AGGREGATE)]
.current);record_trace(
TraceEntry::FREE_REQUESTED,
int64_t(block->ptr),
block->requested_size,
block->stream,
block->device,
context ? context : block->context_when_allocated);if (block->size >= CUDAAllocatorConfig::max_split_size())
stats.oversize_allocations.decrease(1);if (!block->stream_uses.empty()) {
if (C10_UNLIKELY(!captures_underway.empty())) {
// It’s forbidden to cudaEventQuery an event recorded during CUDA graph
// capture. We conservatively defer recording end-of-life events until
// the next call to process_events() (which won’t happen until no
// captures are underway)
needs_events_deferred_until_no_capture.push_back(block);
} else {
insert_events(block);
}
} else {
free_block(block, context);
}
c10::reportMemoryUsageToProfiler(
orig_block_ptr,
-static_cast<int64_t>(orig_block_size),
stats.allocated_bytes[static_cast<size_t>(StatType::AGGREGATE)].current,
stats.reserved_bytes[static_cast<size_t>(StatType::AGGREGATE)].current,
c10::Device(c10::DeviceType::CUDA, block->device));
}
size_t try_merge_blocks(Block* dst, Block* src, BlockPool& pool) { if (!src || src->allocated || src->event_count > 0 || !src->stream_uses.empty() || dst->mapped != src->mapped) { return 0; }AT_ASSERT(dst->is_split() && src->is_split());
if (dst->prev == src) { // [src dst]
dst->ptr = src->ptr;
dst->prev = src->prev;
if (dst->prev) {
dst->prev->next = dst;
}
dst->context_when_segment_allocated =
std::move(src->context_when_segment_allocated);
} else { // [dest src]
dst->next = src->next;
if (dst->next) {
dst->next->prev = dst;
}
}
const size_t subsumed_size = src->size;
dst->size += subsumed_size;
// NOLINTNEXTLINE(clang-analyzer-deadcode.DeadStores)
auto erased =
src->mapped ? pool.blocks.erase(src) : pool.unmapped.erase(src);
TORCH_INTERNAL_ASSERT_DEBUG_ONLY(erased == 1);
delete src;
return subsumed_size;
}
智能理解 PPT 内容,快速生成讲解视频
在制作线上课程、自媒体内容或者活动宣传视频时,用户通常需要撰写解说词、录制音频和剪辑视频,制作流程繁琐且周期较长。本方案利用大模型的理解和生成能力自动将 PPT 转化为讲解视频,提高了制作效率,使创作者能专注于内容创新。
点击阅读原文查看详情。