哥本哈根大学等团队提出新方法MM-FSS,利用文本和2D信息助力3D小样本分割,无需额外标注成本,已被ICLR 2025接收为Spotlight论文。
原文标题:ICLR 2025 Spotlight |「免费」多模态信息助力3D小样本分割
原文作者:机器之心
冷月清谈:
本文介绍了一种新的多模态Few-shot 3D点云语义分割(FS-PCS)方法,旨在解决3D场景理解中对大量标注数据的依赖问题。该方法通过融合文本和2D图像信息,在不增加额外标注成本的前提下,显著提升了模型在小样本学习环境下的新类别识别能力。核心在于提出的MultiModal Few-Shot SegNet (MM-FSS)模型,该模型包含跨模态特征头(IF Head)和单模态特征头(UF Head),分别用于学习与2D视觉特征对齐的3D点云特征和提取3D点云本身的特征。通过跨模态对齐预训练和Meta-learning,MM-FSS能够有效整合多模态信息,并在测试阶段利用Test-time Adaptive Cross-modal Calibration (TACC)技术缓解训练偏差,从而实现更好的泛化性能。实验结果表明,该方法在标准FS-PCS数据集上取得了优异表现,为未来的研究提供了新的方向。
怜星夜思:
1、这篇文章提出的多模态融合方法,在实际应用中会遇到哪些挑战?比如数据获取、模态之间的对齐等等,有什么好的解决方案吗?
2、文章中提到的TACC(Test-time Adaptive Cross-modal Calibration)技术,是如何缓解Few-shot模型的training bias的?这个思路能不能应用到其他领域?
3、文章提出的MM-FSS模型,在meta-learning阶段是如何利用文本模态特征的?文本信息在提升分割效果上起到了什么作用?
2、文章中提到的TACC(Test-time Adaptive Cross-modal Calibration)技术,是如何缓解Few-shot模型的training bias的?这个思路能不能应用到其他领域?
3、文章提出的MM-FSS模型,在meta-learning阶段是如何利用文本模态特征的?文本信息在提升分割效果上起到了什么作用?
原文内容

该文章的第一作者安照崇,目前在哥本哈根大学攻读博士学位,导师为 Serge Belongie。他硕士毕业于苏黎世联邦理工学院(ETH Zurich),在硕士期间,他跟随导师 Luc Van Gool 进行了多个研究项目。他的主要研究方向包括场景理解、小样本学习以及多模态学习。
当人形机器人能够辨识身边的一切,VR/AR 设备呈现出定制化的虚拟世界,自动驾驶汽车实时捕捉路面状况,这一切都依赖于对 3D 场景的精确理解。然而,这种精准的 3D 理解往往需要大量详细标注的 3D 数据,极大推高了时间成本和资源消耗,而每当出现新场景或特定目标时,又不得不重复这一繁重过程。
Few-shot 学习是一种有效的解决思路——通过极少量标注样本,让模型迅速掌握新类别,从而大幅改善了这一局限性。但当前研究都局限于单模态点云数据,忽略了多模态信息的潜在价值。对此,University of Copenhagen、ETH Zurich 等团队填补了这一空白,提出了一个全新的多模态 Few-shot 3D 分割设定和创新方法:在无需额外标注成本的前提下,融合了文本,2D,3D 信息,助力模型更好地适应到新类别。
这篇文章已被 ICLR 2025 接收为 Spotlight 论文,欢迎关注论文和代码,了解更多细节!

-
论文:Multimodality Helps Few-shot 3D Point Cloud Semantic Segmentation
-
论文链接:https://arxiv.org/abs/2410.22489
-
GitHub链接:https://github.com/ZhaochongAn/Multimodality-3D-Few-Shot

3D Few-shot 分割结果示例
引言
3D 场景理解在具身智能、VR/AR 等领域至关重要,帮助设备准确感知和解读三维世界。然而,传统全监督模型虽在特定类别上表现出色,但其能力局限于预定义类别。每当需要识别新类别时,必须重新收集并标注大量 3D 数据以及重新训练模型,这一过程既耗时又昂贵,极大地制约了模型的应用广度。
3D Few-shot 学习旨在利用极少量的示例样本以适应模型来有效的识别任意的全新类别,大大降低了新类适应的开销,使得传统的 3D 场景理解模型不再局限于训练集中有限的类别标签,对广泛的应用场景有重要的价值。
具体而言,对于 Few-shot 3D 点云语义分割(FS-PCS)任务,模型的输入包括少量支持样本(包含点云及对应新类标签)和查询点云。模型需要通过利用支持样本获得关于新类别的知识并应用于分割查询点云,预测出查询点云中关于新类别的标签。在模型训练和测试时使用的目标类别无重合,以保证测试时使用的类均为新类,未被模型在训练时见过。
目前,该领域涌现出的工作 [1,2] 都只利用点云单模态的输入,忽略了利用多模态信息的潜在的益处。对此,这篇文章提出一个全新的多模态 Few-shot 3D 分割设定,利用了文本和 2D 模态且没有引入额外的标注开销。在这一设定下,他们推出了创新模型——MultiModal Few-Shot SegNet (MM-FSS)。该模型通过充分整合多模态信息,有效提升小样本上新类别的学习与泛化能力,证明了利用普遍被忽略的多模态信息对于实现更好的小样本新类泛化的重要性,为未来研究开辟了全新方向。
Multimodal FS-PCS Setup

图 1. 多模态 FS-PCS 设定
为便于讨论,以下都将 Few-shot 3D 点云语义分割简称为 FS-PCS。
传统的 FS-PCS 任务:模型的输入包含少量的支持点云以及对应的新类别的标注(support point cloud & support mask)。此外,输入还包括查询点云(query point cloud)。模型需借助 support 样本中关于新类别的知识,在 query 点云中完成新类别分割。
多模态 FS-PCS 任务:作者引入的多模态 FS-PCS 包括了除 3D 点云之外的两个额外模态:文本和 2D。文本模态相应于支持样本中的目标类别 / 新类的名称。2D 模态相应于 2D 图片,往往伴随 3D 场景采集同步获得。值得注意的是,2D 模态仅用于模型预训练,不要求在 meta-learning 和测试时作为输入,保证了其 Few-shot 输入形式与传统 FS-PCS 对齐,仅需要相同的数据且无需额外标注。
新的 Multimodal FS-PCS 模型 MM-FSS
模型概览

图 2. MM-FSS 架构
关键模块解析
MM-FSS 在 Backbone 后引入两个特征提取分支:
-
Intermodal Feature (IF) Head(跨模态特征头):学习与 2D 视觉特征对齐的 3D 点云特征。
-
Unimodal Feature (UF) Head(单模态特征头):提取 3D 点云本身的特征。
① 预训练阶段
MM-FSS 先进行跨模态对齐预训练,通过利用 3D 点云和 2D 图片数据对,使用 2D 视觉 - 语言模型(VLM)输出的 2D 特征监督 IF head 输出的 3D 特征,使得 IF Head 学习到与 2D 视觉 - 语言模型对齐的 3D 特征。这一阶段完成后:
-
Backbone 和 IF Head 保持冻结,确保模型在 Few-shot 学习时能利用其预训练学到的 Intermodal 特征。这样,在 Few-shot 任务中无需额外的 2D 输入,仅依赖 Intermodal 特征即可获益于多模态信息。
-
此外,该特征也隐式对齐了 VLM 的文本特征,为后续阶段利用重要的文本引导奠定基础。
② Meta-learning 阶段
在 Few-shot 训练(称为 meta-learning)时,给定输入的 support 和 query 点云,MM-FSS 分别将 IF Head 和 UF Head 输出的两套特征计算出对应的两套 correlations(correlations 表示每个 query 点和目标类别 prototypes 之间的特征相似度)。
-
两套 correlations 会通过 Multimodal Correlation Fusion (MCF) 进行融合,生成初始多模态 correlations,包含了 2D 和 3D 的视觉信息。这个过程可以表示为:

其中 和
和  分别表示用 IF Head 和 UF Head 特征算得的 correlations。
分别表示用 IF Head 和 UF Head 特征算得的 correlations。 为 MCF 输出的初始多模态 correlations。
为 MCF 输出的初始多模态 correlations。
-
当前获得的多模态 correlations 融合了不同的视觉信息源,但文本模态中的语义信息尚未被利用,因此设计了 Multimodal Semantic Fusion (MSF) 模块,进一步利用文本模态特征作为语义引导,提升多模态 correlations:

其中  为文本模态的语义引导,
为文本模态的语义引导, 为文本和视觉模态间的权重(会动态变化以考虑不同模态间变化的相对重要性),
为文本和视觉模态间的权重(会动态变化以考虑不同模态间变化的相对重要性), 为多模态 correlations。
为多模态 correlations。
③ 测试阶段
为缓解 Few-shot 模型对于训练类别的 training bias(易被测试场景中存在的训练类别干扰,影响新类分割),MM-FSS 在测试时引入 Test-time Adaptive Cross-modal Calibration (TACC) :利用跨模态的语义引导(由 IF Head 生成)适应性地修正预测结果,实现更好的泛化。
跨模态的语义引导未经 meta-learning 训练,有更少的 training bias。为了有效的执行测试时修正,作者提出基于支持样本及其标签估算可靠性指标,用于自动调整修正程度(当该语义引导可靠性更高时,分配更大的修正权重,否则分配更小的权重):


实验结果

表 1. 实验结果
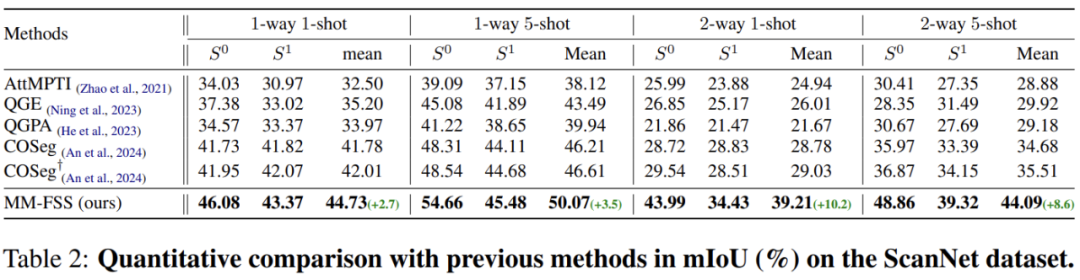
表 2.实验结果

图 3. MM-FSS 的可视化对比结果

图 4. MM-FSS 的可视化消融实验结果
实验在两个标准的 FS-PCS 数据集上进行,证明了 MM-FSS 在各类 few-shot 任务中都实现了最佳性能。可视化也清楚表明了模型能够实现更优的新类分割,展示了更强的新类泛化能力。更多详细实验和分析内容请参见论文。
总结
这项工作首次探索了融合多模态以提升 FS-PCS 任务的可能性。文中首先提出了全新的多模态 FS-PCS 设定,无额外开销地融合文本和 2D 模态。在该设定下,作者提出首个多模态 FS-PCS 模型 MM-FSS,显式的利用文本模态,隐式的利用 2D 模态,最大化其灵活性和各场景下的应用性。
MM-FSS 包含了 MCF 和 MSF 来有效的从视觉线索和语义信息双重角度高效聚合多模态知识,增强对新类概念的全面理解。此外,为了协调 few-shot 模型的 training bias,作者设计了 TACC 技术,在测试时动态的修正预测。
综合来看,该工作展示了过往被普遍忽略的「免费」多模态信息对于小样本适应的重要性,为未来的研究提供了宝贵的新视野且开放了更多有趣的潜在方向。可参考的方向包括性能的提升 [2,3],训练和推理效率的优化 [4],更深入的模态信息利用等。
引用
[1] Zhao, Na, et al. "Few-shot 3d point cloud semantic segmentation." *Proceedings of the IEEE/CVF conference on computer vision and pattern recognition*. 2021.
[2] An, Zhaochong, et al. "Rethinking few-shot 3d point cloud semantic segmentation." *Proceedings of the IEEE/CVF conference on computer vision and pattern recognition*. 2024.
[3] Liu, Yuanwei, et al. "Intermediate prototype mining transformer for few-shot semantic segmentation." Advances in Neural Information Processing Systems 35 (2022): 38020-38031.
[4] Wu, Xiaoyang, et al. "Point transformer v3: Simpler faster stronger." *Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition*. 2024.
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]