通过模拟时钟中断和调度事件,优化和测试虚拟机监控器,提高虚拟化环境的性能和稳定性。
原文标题:schedule:原来还可以这样让进程让出 CPU?
原文作者:阿里云开发者
冷月清谈:
具体实现上,该方法需要保存和恢复寄存器状态,确保程序能够在调度后正确返回之前的执行流程。同时,还需要考虑一些细节问题,例如如何避免中断处理程序本身被中断、如何避免死锁等。文章还提到了金丝雀栈检查机制和中断优先级等硬件规范,这些都是保证系统稳定性和安全性的重要因素。
该方法提供了一种在非抢占式内核中模拟抢占式调度的思路,可用于测试和优化VMM,提高虚拟化环境的性能和稳定性。
怜星夜思:
2、在多核系统中,如何确保模拟的时钟中断只在一个指定的CPU核心上触发?
3、文章中提到的金丝雀栈检查机制,除了防止栈溢出攻击,还能起到哪些作用?
原文内容

阿里妹导读
文章主要讲述通过模拟时钟中断和调度事件来优化和测试虚拟机监控器(VMM)的方法,包括流程设计、寄存器状态的保存与恢复、硬件中断处理规范等细节。
一、需求背景
云的一个很重要的技术是——虚拟化,可以把云想象成一块块很大的蛋糕,虚拟化就好比一把刀,目标是把这一块块的蛋糕切开分给不同的用户。

蛋糕就是 cpu、内存等资源,现在有了资源,那如何来创建、配置、管理这些 VM 呢,答案是使用 VMM(虚拟机监控器)目前主流的虚拟化方案是 qemu/kvm,其中 qemu 是用户态程序,kvm 是内核态模块,二者相互配合完成。

当 VM 内部执行特殊指令或者发生某些事件时,会从 guest 退出到 host 上的 VMM 进行处理,在退出时需要保存好 VM 相关的寄存器信息等,在处理完成后重新进入 guest 时加载这些信息,大部分的逻辑都是在内核态完成的。同样的,对于传统的操作系统,机器上的内核态进程会共享物理 CPU,发生进程切换时需要保存硬件的上下文信息,使得进程在下一次被调度的时候能够正常运行。
所有的云厂商为了提高竞争力,无论是否使用 qemu/kvm 这一套虚拟化方案,都一定会去拆分、优化甚至自定义 VMM 的部分行为,性能提升的同时,也让线上生产环境变得庞大、复杂。对于线上环境,非预期的中断对现有进程的运行会造成一定的影响,为了保障新功能上线的稳定性,线下的测试也需要尽可能构造线上真实的场景,甚至更大的压力去覆盖尽可能全的内核代码路径,暴露潜在的问题。

举个例子,对于大部分的线上机器,可能很久都不会出现 swap 的情况,因为内存压力并不大,线下测试环境更多的是做新老功能的正确性验证。进程的状态可能会由于多种情况发生变化,主要可以归为两类:一类是中断,另一类是调度。在内核态程序运行的任意时刻触发一个中断十分容易做到,但是在任意时刻触发一个调度听起来就不那么好实现了。
很多人会想这样一个问题,对于抢占式内核,注入一个中断大概率就可以发生一次调度了,但是在大部分服务器上默认配置的是非抢占式内核,所以我们实现的功能非常接近于在没有打开 CONFIG_PREEMPT 配置的内核中实现在中断结束后做一次抢占式调度。
二、方案设计
2.1. 流程梳理
前置判断:
-
向内核插入一个模块,注册时钟中断,每间隔 20ms 触发一次。
-
判断打断的进程是否是目标的内核态进程,因为 cpu 上会发生进程切换,打断的如果不是目标进程就忽略。
-
判断当前 preempt_cnt 是零,同时不在软中断上下文中。
-
判断打断时进程正在执行的指令允许主动注入调度,让出 cpu。

修改操作:
-
在进程的内核栈上保存中断时寄存器的信息。
-
修改中断记录的寄存器信息,将 ip 置为新的函数地址。
-
中断返回,执行 msleep 主动 schedule。
-
恢复原来程序的寄存器信息,至此程序等于主动执行了一次 msleep 让出了 cpu。
2.2. 具体图示

和流程图对应:
第一步:通过 timer 打断某个 CPU 正在运行的进程,此时会在栈上记录当前进程的寄存器信息。
第二步:在 timer 的 callback 函数中,在栈顶附近记录当前中断发生时原来程序的 r14、r15 寄存器的值,接着将中断寄存器的 r15 修改为原来程序运行时的 ip,r14 修改为 flags,接着将 rip 的值修改为自定义的函数地址。
第三步:timer 中断正式返回,此时因为 rip 的值被修改,程序执行 new_func 函数逻辑,在函数一开始,且由于 rsp 的值当前指向 r14。
-
通过移动 rsp 将当前进程 r15 的值(rip)赋值给到打断进程 rsp - 8 的位置,同理将 r14 的值(flags)放在 rsp -16 的位置,这样原来函数执行的 rip 以及 flags 寄存器就可以在最后进行恢复。
-
将内核栈上记录的 r14、r15 紧挨着 flags 寄存器存放。
-
保存其它寄存器信息,此时 rsp 指向存放的最后一个寄存器。
第四步:做好寄存器的恢复和记录后,执行 msleep 主动触发 schedule,执行完成后,无论栈如何变化,rsp 会重新指向保存的最后一个寄存器。
2.3. 细节分析
2.3.1. 时钟中断实现
具体选用 hrtimer 来完成每 20ms 触发一次调度的目标。正常使用相关的接口函数就好了,需要注意的一个点就是 start 的时候如果使用带 PINNED 的标志,可以绑定到当前运行的 cpu 上,这样就可以给每个 CPU 都开启一个 hrtimer。
void timer_callback() { // 这里写对中断寄存器的保存、修改操作 }void setup_timer() {
// 设置时钟中断间隔,这里单位 ns
ktime_t interval = ktime_set(0, 20000000);// 初始化
hrtimer_init(&timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL_PINNED);// 设置 timer 中断执行的函数
timer.function = &timer_callback;// 启动 timer 中断
hrtimer_start(&timer, interval, HRTIMER_MODE_REL_PINNED);
restart:
hrtimer_forward_now(timer, interval);
return HRTIMER_RESTART;
}
2.3.2 前置判断由来
-
为什么需要判断 preempt_cnt 以及是否在软中断上下文
因为 preempt_cnt 为 0 的时候才允许被抢占,同时也不希望抢占处于软中断处理的情况,相关的 mask 信息如下:

这里还需要关注一个点,就是避免误伤,这个注入程序打断内核进程时,避免打断还在 msleep 的进程,为此可以通过 task_struct 中 sched_info 的 pcount 来做一个区分。当进程重新被调度的时候,pcount 会增加 1,那么在每次注入的时候,将其置为 0,当这个值大于等于 2 的时候说明肯定已经在执行原来的函数了,因为自定义的函数 new_func 中并没有其它调度点。
-
为什么有一些 rip 需要过滤?
因为一些涉及到拿锁的函数逻辑,也不应该发生调度,当拿到锁的内核进程被调度出去后,如果下一个运行的程序也需要拿到相同的锁,就会发生严重的死锁问题,如下图所示:

内核进程 1 绑定在 CPU0 上运行,且拿到一把锁,此时发生调度,CPU0 开始运行内核进程 2,就会一直夯在拿锁逻辑,内核进程 1 也永远不会再被调度。
这里还涉及到一个点,自旋锁上锁期间也应该禁止抢占。
#define preempt_disable() barrier()
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, RET_IP);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
2.3.3. 金丝雀栈检查
看到具体实现的时候,很多人可能很好理解使用 r15 保存原来函数 rip 的原因,但是却不太清楚为什么还需要用 r14 来特地保存 flags 寄存器,那看一下下面这个 core 的信息:
#0 [ffffc900032dfb30] machine_kexec at ffffffff8105a401
#1 [ffffc900032dfb88] __crash_kexec at ffffffff8113bfd1
#2 [ffffc900032dfc48] panic at ffffffff81093892
#3 [ffffc900032dfcd0] __stack_chk_fail at ffffffff81093225
#4 [ffffc900032dfcd8] kvm_skip_emulated_instruction at ffffffffc0a19a64
#5 [ffffc900032dfd00] kvm_emulate_cpuid at ffffffffc0a4caf8
#6 [ffffc900032dfd28] vcpu_enter_guest at ffffffffc0a201f4
可以看到因为发生 __stack_chk_fail,导致机器发生 panic 挂掉,那接着分析一下为什么会发生 __stack_chk_fail。__stack_chk_fail 这里就是开启 stack protector 后,程序在执行函数最开始会在 rsp 向栈顶偏移一定位置的地址放置一个金丝雀(canary),执行完成后查看金丝雀有没有被恶意修改。下图简要展示了安放金丝雀后开始执行函数的栈变化,当函数执行完后,会重新判断金丝雀的值是否跟之前一致,一致的情况下才认为能够安全返回,否则说明栈上信息被恶意修改,最坏的情况是跳到其它函数(跟注入一个新的函数有点儿类似)特别是病毒程序继续运行,但“道高一尺,魔高一丈”,金丝雀能防护的只是按照从栈顶开始顺序破坏栈上数据的情况。对于绕过金丝雀直接修改栈中间数据的情况,就无能为力了。
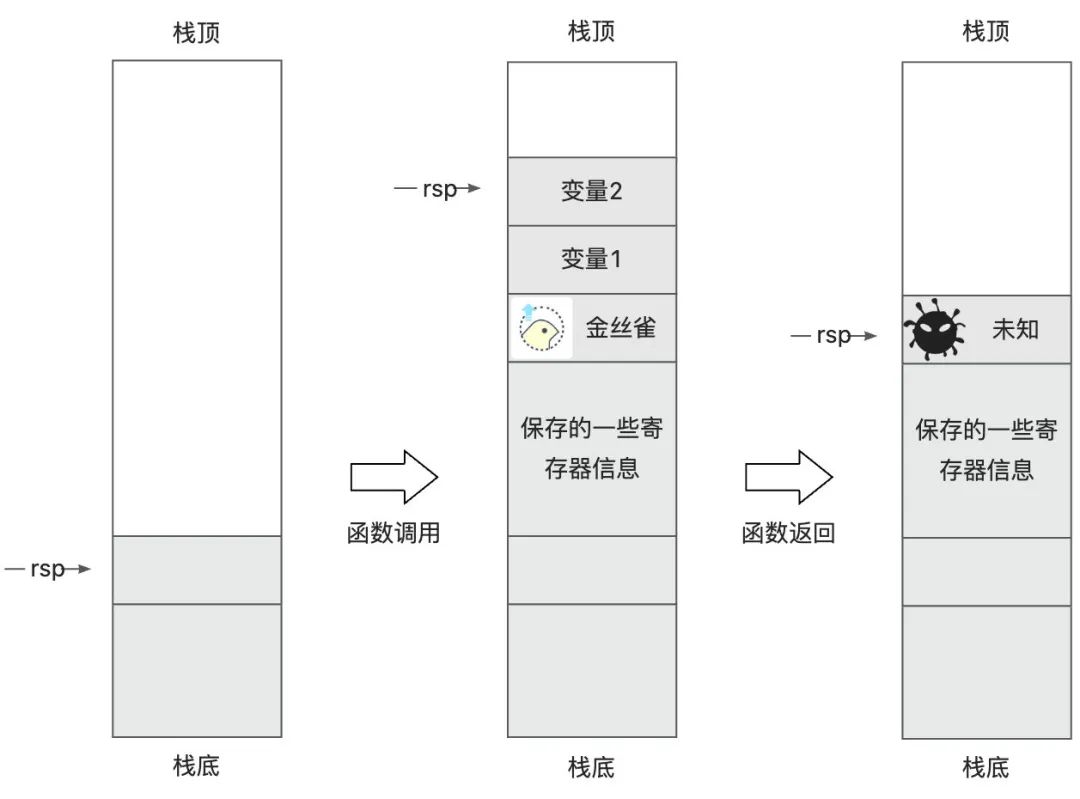
继续分析,是不是这个值真的被改了,看一下 line5-6 就是把 rsp 先减了16,也就是往栈顶挪动,把 gs: 0x28 赋值给 rax,再把 rax 赋值给 rsp + 8 的位置,就完成了金丝雀的安放。在 line 9-11 中,把金丝雀的值拿出来放到 rdx 中,xor 金丝雀的值和栈上的值,如果不一样则跳转到 __stack_chk_fail。
0xffffffffc0a199e0 <kvm_skip_emulated_instruction>: nopl 0x0(%rax,%rax,1) [FTRACE NOP]
0xffffffffc0a199e5 <kvm_skip_emulated_instruction+5>: push %rbp
0xffffffffc0a199e6 <kvm_skip_emulated_instruction+6>: push %rbx
0xffffffffc0a199e7 <kvm_skip_emulated_instruction+7>: mov %rdi,%rbx
0xffffffffc0a199ea <kvm_skip_emulated_instruction+10>: sub $0x10,%rsp
0xffffffffc0a199ee <kvm_skip_emulated_instruction+14>: mov %gs:0x28,%rax
0xffffffffc0a199f7 <kvm_skip_emulated_instruction+23>: mov %rax,0x8(%rsp)
...
0xffffffffc0a19a39 <kvm_skip_emulated_instruction+89>: mov 0x8(%rsp),%rdx
0xffffffffc0a19a3e <kvm_skip_emulated_instruction+94>: xor %gs:0x28,%rdx
0xffffffffc0a19a47 <kvm_skip_emulated_instruction+103>: jne 0xffffffffc0a19a5f <kvm_skip_emulated_instruction+127>
...
0xffffffffc0a19a5f <kvm_skip_emulated_instruction+127>: callq 0xffffffff81093210 <__stack_chk_fail>
怎么看到 rdx 当前是什么值呢?那就看一下 panic 函数的汇编和栈信息,先看看汇编,line14,rdx 放在了 rbp 向前9个值的位置(0x48 = 72 = 9*8)。
0xffffffff81093739 <panic>: callq 0xffffffffc008a000 0xffffffff8109373e <panic+5>: push %rbp 0xffffffff8109373f <panic+6>: mov %rsp,%rbp 0xffffffff81093742 <panic+9>: push %r14 0xffffffff81093744 <panic+11>: push %r13 0xffffffff81093746 <panic+13>: push %r12 0xffffffff81093748 <panic+15>: push %r10 0xffffffff8109374a <panic+17>: lea 0x10(%rbp),%r10 0xffffffff8109374e <panic+21>: push %rbx 0xffffffff8109374f <panic+22>: mov %rdi,%r12 0xffffffff81093752 <panic+25>: mov %r10,%r13 0xffffffff81093755 <panic+28>: sub $0x50,%rsp 0xffffffff81093759 <panic+32>: mov %rsi,-0x50(%rbp) 0xffffffff8109375d <panic+36>: mov %rdx,-0x48(%rbp) 0xffffffff81093761 <panic+40>: mov %rcx,-0x40(%rbp) 0xffffffff81093765 <panic+44>: mov %r8,-0x38(%rbp) 0xffffffff81093769 <panic+48>: mov %r9,-0x30(%rbp) 0xffffffff8109376d <panic+52>: mov 0x17e1a5d(%rip),%bl # 0xffffffff828751d0 <crash_kexec_post_notifiers> 0xffffffff81093773 <panic+58>: mov %gs:0x28,%rax 0xffffffff8109377c <panic+67>: mov %rax,-0x60(%rbp) 0xffffffff81093780 <panic+71>: xor %eax,%eax
所以需要看一下 rdx 的值是多少,看一下栈信息:
#1 [ffffc900032dfb88] __crash_kexec at ffffffff8113bfd1 ffffc900032dfb90: ffff88c10fbf0000 ffff88816e7f2e80 ffffc900032dfba0: ffffc900032dfcd8 ffffffff820950a0 ffffc900032dfbb0: ffffc900032dfcc8 0000000000000000 ffffc900032dfbc0: 0000000000000000 0000000000000018 ffffc900032dfbd0: 0000000065afa019 0000000065afb000 ffffc900032dfbe0: 0000000000000001 ffff88816e7f2e80 ffffc900032dfbf0: 0000000000000000 0000000000000000 ffffc900032dfc00: ffffc900032dfb90 ffffffff8287bd0c ffffc900032dfc10: ffffffff8113bf60 0000000000000010 ffffc900032dfc20: 0000000000000046 ffffc900032dfb88 ffffc900032dfc30: 0000000000000018 489974d7d1bb3300 ffffc900032dfc40: ffff88c10fbf0001 ffffffff81093892 #2 [ffffc900032dfc48] panic at ffffffff81093892
可以看到栈上的数据,panic ffffffff81093892,往前一个是 rbp,再往前 9 个是 rdx,rdx 是0。
也就是说 xor %gs:0x28,%rdx 这一句给目标寄存器赋值赋的是 0,那说明两个值是相等的,怎么还会进入到 __stack_chk_fail 呢?说明判断语句有问题,哪个寄存器会影响判断逻辑?答案是 flags 寄存器,那就很奇怪了,回过来看看写的代码,看起来没有修改 flags 寄存器的地方?
__asm__ volatile ( // 先回到中断前栈顶位置 "addq $1024, %rsp\n\t" // 把 r15 push 过来(实际是 rip),这样 retq 语义才正确 "pushq %r15\n\t" // 回到存放中断前 r15 的地方 "subq $1016, %rsp\n\t" // 把 r15 pop 出来 "popq %r15\n\t" // 再回到中断前 rip 的地方 "addq $1008, %rsp\n\t" );
但是很多时候程序运行不像表面看到的那样,语义本身可能就会修改 flags 寄存器,AI 的时代合理运用工具,问问 GPT?

果不其然,在操作栈指针的时候,flags 寄存器就会被修改掉,所以在函数返回的时候,flags 寄存器不对,导致调度函数执行完回到内核函数后,判断逻辑行为变得不可控,出现了这个错误。那同样的,需要在中断过程中把 flags 寄存器也保存下来。
2.3.4. 中断硬件规范
在具体的实现过程中,除了软件保存寄存器信息,移动 rsp 指针等,还要关注中断硬件规范。
-
时钟中断返回后:
执行 new_func 函数,需要先保存此时的 r14、r15,也就是中断时 flags 寄存器和 rip 寄存器的值,接着将内核栈上的 r14、r15 从靠近栈顶的位置读出来,试想一下读 r14、r15 的时候如果 rsp 指向如下图所示:

此时 rsp 指向的是 r15,如果在恢复 r15、r14 之前来了一个中断,那么此时这个中断会以 r14 所在的地址为起始地址作为它的栈空间,这个时候硬件便会往栈上自动 push ss 寄存器以及其它寄存器,所以在内核上下文中,始终要保持 rsp 指向离栈顶最近的有效值,避免数据的覆盖。

-
时钟中断中:
那是不是时钟中断的过程中就可以随意赋值,rsp 随意指向?答案依然是否定的。这里可以参考 intel 手册,对于中断优先级的解释如下,高优先级的中断是可以打断低优先级的中断。

此外,NMI 作为不可屏蔽中断,更特殊,优先级高于可以被 mask 的中断,所以不仅要在函数执行过程中保证 rsp 往栈顶方向没有有效数据,同时在 timer 中断过程中也要保证 rsp 一直指向地址最小(栈顶方向)的有效数据。
三、附录
3.1. kvm 修改
重新定义这两个函数,去修改 preempt_count。
#undef preempt_disable #define preempt_disable() \ do { \ preempt_count_inc(); \ barrier(); \ } while (0) #undef preempt_enable #define preempt_enable() \ do { \ barrier(); \ preempt_count_dec();\ } while (0)
3.2. schedule 程序
#include <linux/module.h> #include <linux/kernel.h> #include <linux/kprobes.h> #include <linux/smp.h> #include <linux/io.h> #include <linux/stacktrace.h> #include <linux/stop_machine.h> #include <linux/sched.h> #include <linux/delay.h> #include <linux/slab.h> #include <linux/proc_fs.h> #include <linux/hrtimer.h> #include <linux/cpu.h> #include <linux/uaccess.h> #include <linux/fs.h> #include <asm/irq_regs.h> #include <linux/kallsyms.h> // timer intr interval #define DEFAULT_INTERVAL_NS 20000000 // 20 ms #define NEW_RSP_OFFSET 1024 #define MAX_RIP_COUNT 20 typedef struct { struct hrtimer timer; ktime_t interval; int running; } hrtimer_data_t; static hrtimer_data_t hr_timer_data[NR_CPUS]; static struct proc_dir_entry *hrtimer_dir; // msleep time static int interval = 1; module_param(interval, int, S_IRUGO); MODULE_PARM_DESC(interval, "An integer parameter"); static void *csd_data; static void *cfd_data; static unsigned long riplist[MAX_RIP_COUNT] = { // _raw_spin_lock 0xffffffff8181ab30, 0xffffffff8181ab4f, // native_queued_spin_lock_slowpath 0xffffffff810ecbf0, 0xffffffff810ecda1, }; static int rip_count = sizeof(riplist) / sizeof(riplist[0]); int in_riplist(unsigned long rip) { int i, j; for (i = 0, j = 0; i < rip_count/2; i++, j=j+2) { if (riplist[j] <= rip && rip <= riplist[j+1]) { return 1; // 找到,返回 1 } } return 0; // 没有找到,返回 0 } struct call_function_data { call_single_data_t __percpu *csd; cpumask_var_t cpumask; cpumask_var_t cpumask_ipi; }; int should_schedule(unsigned long rip) { int cpu; struct call_function_data *cfd; call_single_data_t *csd; if (in_riplist(rip)) return 0; csd = this_cpu_ptr(csd_data); if (csd->flags) return 0; cfd = this_cpu_ptr(cfd_data); for_each_cpu(cpu, cpu_online_mask) { csd = per_cpu_ptr(cfd->csd, cpu); if (csd->flags) return 0; } return 1; } void new_func(void) { __asm__ volatile ( // 先回到 r15 的位置 "addq $168, %rsp\n\t" // 先回到栈顶位置 "addq $8192, %rsp\n\t" // 把 r15 push 过来(实际是 rip),这样 retq 语义才正确 "pushq %r15\n\t" // 保存 flags 寄存器 "pushq %r14\n\t" // 回到 1024 设定的地方 "subq $8184, %rsp\n\t" // 把 r15 pop 出来 "popq %r14\n\t" "popq %r15\n\t" // 再回到原来的地方 "addq $8168, %rsp\n\t" "pushq %rbp\n\t" // 保存 rbp "pushq %rbx\n\t" // 保存 rbx "pushq %r12\n\t" // 保存 r12 "pushq %r13\n\t" // 保存 r13 "pushq %rax\n\t" // 保存 rax "pushq %rcx\n\t" // 保存 rcx "pushq %rdx\n\t" // 保存 rdx "pushq %rsi\n\t" // 保存 rsi "pushq %rdi\n\t" // 保存 rdi "pushq %r8\n\t" // 保存 r8 "pushq %r9\n\t" // 保存 r9 "pushq %r10\n\t" // 保存 r10 "pushq %r11\n\t" // 保存 r11 ); msleep(interval); __asm__ volatile ( "popq %r11\n\t" // 恢复 r11 "popq %r10\n\t" // 恢复 r10 "popq %r9\n\t" // 恢复 r9 "popq %r8\n\t" // 恢复 r8 "popq %rdi\n\t" // 恢复 rdi "popq %rsi\n\t" // 恢复 rsi "popq %rdx\n\t" // 恢复 rdx "popq %rcx\n\t" // 恢复 rcx "popq %rax\n\t" // 恢复 rax "popq %r13\n\t" // 恢复 r13 "popq %r12\n\t" // 恢复 r12 "popq %rbx\n\t" // 恢复 rbx "popq %rbp\n\t" // 恢复 rbp "popfq\n\t" // 恢复 flags 寄存器 "retq\n" ); } EXPORT_SYMBOL(new_func); static unsigned long exec_count = 0; static enum hrtimer_restart timer_callback(struct hrtimer *timer) { //int cpu = smp_processor_id(); hrtimer_data_t *data = container_of(timer, hrtimer_data_t, timer); int softirq_preempt_count = preempt_count() & (PREEMPT_MASK | SOFTIRQ_MASK); struct pt_regs *regs = get_irq_regs(); unsigned long stack_min = (unsigned long)current->stack; if (!should_schedule(regs->ip)) goto restart; if (softirq_preempt_count == 0 && strstr(current->comm, "vcpu-worker") && !strstr(current->comm, "swap") && (current->flags & PF_KTHREAD)) { if (current->sched_info.pcount >= 2) { // Check for injection condition if (regs->sp - stack_min >= (8192+ 2048)) { current->sched_info.pcount = 0; regs->sp = regs->sp - (8192 + 21*8); // 把寄存器全记录下来 *(((unsigned long *)regs->sp) + 21) = regs->r15; *(((unsigned long *)regs->sp) + 20) = regs->r14; *(((unsigned long *)regs->sp) + 19) = regs->r13; *(((unsigned long *)regs->sp) + 18) = regs->r12; *(((unsigned long *)regs->sp) + 17) = regs->bp; *(((unsigned long *)regs->sp) + 16) = regs->bx; *(((unsigned long *)regs->sp) + 15) = regs->r11; *(((unsigned long *)regs->sp) + 14) = regs->r10; *(((unsigned long *)regs->sp) + 13) = regs->r9; *(((unsigned long *)regs->sp) + 12) = regs->r8; *(((unsigned long *)regs->sp) + 11) = regs->ax; *(((unsigned long *)regs->sp) + 10) = regs->cx; *(((unsigned long *)regs->sp) + 9) = regs->dx; *(((unsigned long *)regs->sp) + 8) = regs->si; *(((unsigned long *)regs->sp) + 7) = regs->di; *(((unsigned long *)regs->sp) + 6) = regs->orig_ax; *(((unsigned long *)regs->sp) + 5) = regs->ip; *(((unsigned long *)regs->sp) + 4) = regs->cs; *(((unsigned long *)regs->sp) + 3) = regs->flags; *(((unsigned long *)regs->sp) + 2) = regs->sp; *(((unsigned long *)regs->sp) + 1) = regs->ss; *(((unsigned long *)regs->sp) + 0) = 0xbeefdeaddeadbeefUL; // 方便 debug *(((unsigned long *)stack_min) + 128) = regs->sp; regs->r15 = regs->ip; regs->r14 = regs->flags; regs->ip = (unsigned long)new_func; exec_count++; if (exec_count % 100 == 0) { printk(KERN_INFO "Executed new_func assignment %lu times\n", exec_count); } } else { printk(KERN_INFO "Inject new func to %s failed because the stack space is not enough: %lu\n", current->comm, regs->sp - stack_min); } } } restart: hrtimer_forward_now(timer, data->interval); return HRTIMER_RESTART; } static ssize_t proc_read(struct file *file, char __user *ubuf, size_t count, loff_t *ppos) { uintptr_t cpu = (uintptr_t)PDE_DATA(file_inode(file)); char buf[64]; int len = scnprintf(buf, sizeof(buf), "Interval: %llu ns\n", ktime_to_ns(hr_timer_data[cpu].interval)); return simple_read_from_buffer(ubuf, count, ppos, buf, len); } static void setup_timer_on_cpu(void *arg) { int cpu = smp_processor_id(); if (hr_timer_data[cpu].running) goto start; hr_timer_data[cpu].interval = ktime_set(0, DEFAULT_INTERVAL_NS); hrtimer_init(&hr_timer_data[cpu].timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL_PINNED); hr_timer_data[cpu].timer.function = &timer_callback; hr_timer_data[cpu].running = 1; start: hrtimer_start(&hr_timer_data[cpu].timer, hr_timer_data[cpu].interval, HRTIMER_MODE_REL_PINNED); } static ssize_t proc_write(struct file *file, const char __user *ubuf, size_t count, loff_t *ppos) { uintptr_t cpu = (uintptr_t)PDE_DATA(file_inode(file)); char buf[64]; unsigned long long value_ns; if (copy_from_user(buf, ubuf, min(count, sizeof(buf) - 1))) return -EFAULT; buf[count] = '\0'; if (kstrtoull(buf, 10, &value_ns)) return -EINVAL; hr_timer_data[cpu].interval = ktime_set(0, value_ns); printk(KERN_INFO "hrtimer: CPU %d interval set to %llu ns\n", (int)cpu, value_ns); // Reinitialize the timer with the new interval hrtimer_cancel(&hr_timer_data[cpu].timer); smp_call_function_single(cpu, setup_timer_on_cpu, NULL, true); return count; } static const struct file_operations proc_fops = { .owner = THIS_MODULE, .read = proc_read, .write = proc_write, }; static int timer_init(void) { int cpu; struct proc_dir_entry *entry; printk(KERN_INFO "hrtimer_module: Initializing\n"); csd_data = kallsyms_lookup_name("csd_data"); cfd_data = kallsyms_lookup_name("cfd_data"); if (!csd_data || !cfd_data) return -EINVAL; // Create the /proc/hrtimer directory hrtimer_dir = proc_mkdir("hrtimer", NULL); if (!hrtimer_dir) { printk(KERN_ALERT "hrtimer_module: Could not create /proc/hrtimer directory\n"); return -ENOMEM; } for_each_online_cpu(cpu) { char proc_name[8]; snprintf(proc_name, sizeof(proc_name), "cpu%d", cpu); // Create proc file under /proc/hrtimer for each CPU entry = proc_create_data(proc_name, 0666, hrtimer_dir, &proc_fops, (void *)(long)cpu); if (!entry) printk(KERN_ALERT "hrtimer: Could not create /proc/hrtimer entry for CPU %d\n", cpu); hr_timer_data[cpu].running = 0; smp_call_function_single(cpu, setup_timer_on_cpu, NULL, true); } return 0; } static void timer_exit(void) { int cpu; char proc_name[8]; printk(KERN_INFO "hrtimer_module: Exiting\n"); for_each_online_cpu(cpu) { snprintf(proc_name, sizeof(proc_name), "cpu%d", cpu); hrtimer_cancel(&hr_timer_data[cpu].timer); remove_proc_entry(proc_name, hrtimer_dir); } // Remove the /proc/hrtimer directory remove_proc_entry("hrtimer", NULL); } static int __init my_kprobe_init(void) { timer_init(); printk(KERN_INFO "Kprobe registered\n"); return 0; } static void __exit my_kprobe_exit(void) { timer_exit(); printk(KERN_INFO "Kprobe unregistered\n"); } module_init(my_kprobe_init); module_exit(my_kprobe_exit); MODULE_LICENSE("GPL"); MODULE_DESCRIPTION("Kprobe for smp_apic_timer_interrupt"); MODULE_AUTHOR("Your Name");
使用方法:
3.3. 参考文献
Intel SDM:https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html
--最后感谢师兄陈伟宸和主管徐云的支持 / 作者:魏子杰