DeepSeek 的成功证明强化学习对提升AI推理能力至关重要,推荐《深度学习入门4》快速入门。
原文标题:DeepSeek 爆火出圈,强化学习撑起 AI 的半壁江山!
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、强化学习和监督学习、无监督学习相比,最大的区别是什么?实际应用中该如何选择?
3、DeepSeek 的技术细节没有透露太多,大家觉得它在强化学习方面具体做了哪些改进?
原文内容
最近,AI 界杀出了一匹黑马 ——DeepSeek,它在推理能力上取得了重大突破,吸引了无数人的目光。这一成就让我们再次深刻认识到强化学习(Reinforcement Learning,RL)在提升大模型智能方面的关键作用。不管是 OpenAI 的 ChatGPT,还是 DeepMind 的 AlphaGo,强化学习几乎都是这些顶尖 AI 模型背后的核心驱动力。在这个 AI 飞速发展、竞争激烈的时代,深入了解强化学习的核心思想和应用场景,显得尤为重要。
在这个 AI 竞速的时代,如果你想真正理解 AI 是如何思考、如何优化决策的,强化学习就是绕不开的关键技术。那么,如何快速入门这一领域?《深度学习入门4:强化学习》(“鱼书”系列第四部)无疑是一本极佳的入门书籍,能够帮助你系统地掌握强化学习的基本原理,并了解它在人工智能中的实际应用。
本文将从专业的角度,结合当下 DeepSeek 的最新技术进展,为你解读为什么强化学习如此重要,以及如何通过这本书快速入门。
为什么强化学习是 AI 进步的关键?
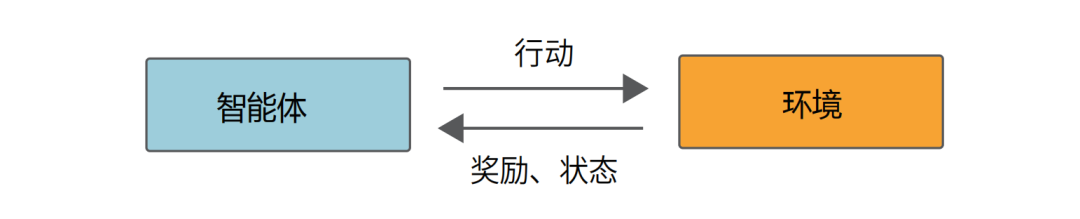
强化学习框架
强化学习不同于传统的监督学习、无监督学习,它不依赖于固定的数据标签,而是让智能体(Agent)在环境(Environment)中不断尝试、学习,并优化自己的策略(Policy),最终获得最大化的奖励(Reward)。打个比方,这就像小孩学骑自行车,或者机器人学习高效行走,不是一开始就知道所有正确答案,而是在一次次的尝试中慢慢掌握技巧。
机器人行走问题中的相互作用
那么,强化学习究竟在哪些方面展现出了优势呢?
1. 突破复杂问题求解的瓶颈
在很多 AI 任务里,手动标注大量高质量数据是很困难的。比如自动驾驶、机器人控制、金融决策这些领域,环境充满了不确定性,决策过程也很复杂,监督学习很难直接发挥作用。而强化学习却能大显身手,成为解决这类问题的理想方法。
2. 助力大模型的推理能力提升
DeepSeek 之所以备受关注,就是因为在大模型推理能力上取得了突破,这里面强化学习功不可没。它能让 AI 学会更有效的推理方式,而不是简单地根据已有的数据进行模仿。就像 ChatGPT 采用的 RLHF(Reinforcement Learning from Human Feedback),这是一种强化学习方法,通过人类反馈来优化模型输出,让答案更准确、更易懂。
3. 广泛的应用场景
强化学习的应用范围非常广泛,在许多领域都展现出了强大的实力:
-
游戏 AI:从 AlphaGo 到 DeepMind 的 StarCraft 代理,强化学习在游戏领域创造了一个又一个奇迹。
-
机器人控制:在自动化生产、无人机导航、机械臂操作等场景中,强化学习让机器人变得更加自主,能够更好地完成任务。
-
自动交易:在量化金融领域,强化学习也发挥着重要作用,帮助交易系统优化投资策略,获取更好的收益。
如何快速入门强化学习?
想要真正理解和掌握强化学习,一本专业又通俗易懂的入门指南必不可少。“鱼书” 系列一直是深度学习入门的经典选择,《深度学习入门 4:强化学习》更是其中的佼佼者。
本书延续了“鱼书”系列一贯的风格,提供实际代码,边实践边学习,无须依赖外部库,从零开始实现支撑强化学习的基础技术。
内容概览
1. 把握潮流中的变与不变
深度学习领域发展迅速,有些东西会随着时间流逝,有些却能一直传承。你在本书中学到的就是不变的东西。作者坚信,强化学习、马尔可夫决策过程、贝尔曼方程、Q 学习、神经网络的基本原则等技术将一如既往地重要。希望你通过本书熟练掌握强化学习领域的基础知识,并体会到“不变的东西”的魅力。
2. 内容丰富,讲解简明易懂
作为超高人气“鱼书”系列第四部作品,它延续了这一系列的写作和讲解风格,搭配丰富的图、表、代码示例,加上轻松、简明的讲解,能让你清晰地理解强化学习中各种方法之间的关系,不知不觉就掌握了这门技术。
3. 原理与实践并重
本书旨在确保你能够牢固掌握强化学习的独特理论,奉行“只有做出来才能真正理解”的理念,将这一主题的每个构成要素都从“理论”和“实践”两个方面进行详尽解释,并鼓励你动手尝试。与仅通过数学公式解释理论的图书不同,你将通过实际运行本书代码获得许多令人惊叹的领悟。
作译者简介
作者:斋藤康毅
1984 年出生于日本长崎县,东京工业大学毕业,并完成东京大学研究生院课程。目前在某企业从事人工智能相关的研究和开发工作。著有“鱼书”系列《深度学习入门:基于Python的理论与实现》《深度学习进阶:自然语言处理》《深度学习入门2:自制框架》,同时也是 Python in Practice、The Elements of Computing Systems、Building MachineLearning Systems with Python 的日文版译者。
译者:郑明智
智慧医疗工程师,主要研究方向为医疗与前沿 ICT 技术的结合及其应用。译有《深度学习基础与实践》《详解深度学习》《白话机器学习的数学》等书。
抓住 AI 发展的浪潮,从强化学习开始!
AI 时代的竞争,归根结底是对智能的竞争。DeepSeek 这样的 AI 研究机构正在推动大模型向更强的推理能力发展,而强化学习正是这场革命的关键技术之一。如果你希望跟上 AI 发展的步伐,深入理解强化学习,《深度学习入门4:强化学习》无疑是一个绝佳的起点。
⬇️点击购买⬇️,一起开启强化学习之旅!
进一步学习:深度强化学习